 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContemporary AI lacks the imagination to diverge or negate in science
Jun 09, 2026Bold projections that artificial intelligence will accelerate scientific discovery have raced ahead of evidence from working scientists, and the field still lacks large-scale, scientist-in-the-loop tests of these claims. Here we mount the largest such evaluation to date and map what AI cannot yet do for science. We invited authors of 121,640 recent preprints across biology, medicine, chemistry, and the social sciences to judge ideas that large language models (LLMs) generated from the context and puzzles of their own papers. 6,749 scientists returned 25,139 sets of ratings on novelty, empirical feasibility, probability of being true, and favorability of adoption. Three patterns emerge. First, non-reasoning LLMs collapse into a narrow "hivemind" of similar ideas; reasoning models roam a wider hypothesis space, yet no model class spontaneously proposes null hypotheses -- a move humans make more freely. Second, scientists reward ideas that resemble their own and prize probability over novelty, though social scientists tolerate risk more readily than life scientists. Senior social scientists are the harshest critics, and their skepticism is well-earned: LLMs falter most in pluralistic fields like the social sciences that demand context-aware interpretation and evolving theories. Third, automated evaluators on which the community currently relies -- LLM-as-a-judge, artificial metrics, and even state-of-the-art (SOTA) models -- agree only weakly with expert judgment, and retrieval augmentation and scientist persona prompting yield only marginal gains. A Qwen3-14B reward model we post-trained on human ratings captures field taste nuances, beats SOTA models by up to 27%, and closes the gap to the inter-rater consistency of independent peer reviewers. For all the hype, today's scientific AI still represents a collaborator whose imagination, outputs and judgment benefit from human grounding.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Narrative Flattening: How Post-Training Compresses Thematic, Affective, and Stylistic Variation in LLM Fiction
May 27, 2026Large language models produce fluent fiction, yet their creative output is widely seen as flat. We ask where this quality originates in the training and whether it affects different domains of human fiction equally. We construct a matched story-continuation paradigm across StoryStar (public-platform), TMAS (prompt-guided), and The New Yorker (professional literary)-and compare continuations from four OLMo 32B checkpoints (Base, SFT, DPO, RLVR) against matched human text. Because these checkpoints share architecture, scale, tokenizer, and pretraining, the design isolates the post-training effect. We measure each continuation along three sentence-level dimensions: thematic motion, affective prevalence, and linguistic diversity. Across all three, post-training compresses dynamic variation: thematic transitions become more uniform, high-intensity emotions give way to neutrality, and stylistic diversity across stories shrinks. We term this progressive loss narrative flattening. The effect is directionally stable across story domains but gap size depends on the human baseline: professional literary fiction is compressed most, while public-platform and prompt-guided stories show smaller gaps, consistent with their human baselines sitting closer to the model's default rhythm. Post-trained endpoints converge across domains, suggesting alignment produces a continuation regime largely insensitive to the source domain's narrative texture.
Language Models Surface the Unwritten Code of Science and Society
May 25, 2025



This paper calls on the research community not only to investigate how human biases are inherited by large language models (LLMs) but also to explore how these biases in LLMs can be leveraged to make society's "unwritten code" - such as implicit stereotypes and heuristics - visible and accessible for critique. We introduce a conceptual framework through a case study in science: uncovering hidden rules in peer review - the factors that reviewers care about but rarely state explicitly due to normative scientific expectations. The idea of the framework is to push LLMs to speak out their heuristics through generating self-consistent hypotheses - why one paper appeared stronger in reviewer scoring - among paired papers submitted to 45 computer science conferences, while iteratively searching deeper hypotheses from remaining pairs where existing hypotheses cannot explain. We observed that LLMs' normative priors about the internal characteristics of good science extracted from their self-talk, e.g. theoretical rigor, were systematically updated toward posteriors that emphasize storytelling about external connections, such as how the work is positioned and connected within and across literatures. This shift reveals the primacy of scientific myths about intrinsic properties driving scientific excellence rather than extrinsic contextualization and storytelling that influence conceptions of relevance and significance. Human reviewers tend to explicitly reward aspects that moderately align with LLMs' normative priors (correlation = 0.49) but avoid articulating contextualization and storytelling posteriors in their review comments (correlation = -0.14), despite giving implicit reward to them with positive scores. We discuss the broad applicability of the framework, leveraging LLMs as diagnostic tools to surface the tacit codes underlying human society, enabling more precisely targeted responsible AI.
Introspective Growth: Automatically Advancing LLM Expertise in Technology Judgment
May 18, 2025



Large language models (LLMs) increasingly demonstrate signs of conceptual understanding, yet much of their internal knowledge remains latent, loosely structured, and difficult to access or evaluate. We propose self-questioning as a lightweight and scalable strategy to improve LLMs' understanding, particularly in domains where success depends on fine-grained semantic distinctions. To evaluate this approach, we introduce a challenging new benchmark of 1.3 million post-2015 computer science patent pairs, characterized by dense technical jargon and strategically complex writing. The benchmark centers on a pairwise differentiation task: can a model distinguish between closely related but substantively different inventions? We show that prompting LLMs to generate and answer their own questions - targeting the background knowledge required for the task - significantly improves performance. These self-generated questions and answers activate otherwise underutilized internal knowledge. Allowing LLMs to retrieve answers from external scientific texts further enhances performance, suggesting that model knowledge is compressed and lacks the full richness of the training data. We also find that chain-of-thought prompting and self-questioning converge, though self-questioning remains more effective for improving understanding of technical concepts. Notably, we uncover an asymmetry in prompting: smaller models often generate more fundamental, more open-ended, better-aligned questions for mid-sized models than large models with better understanding do, revealing a new strategy for cross-model collaboration. Altogether, our findings establish self-questioning as both a practical mechanism for automatically improving LLM comprehension, especially in domains with sparse and underrepresented knowledge, and a diagnostic probe of how internal and external knowledge are organized.
Evolution of Cooperative Hunting in Artificial Multi-layered Societies
Jun 02, 2020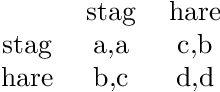
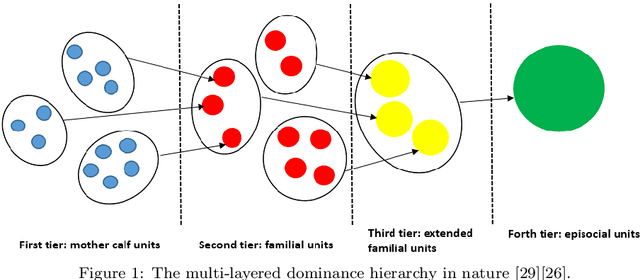
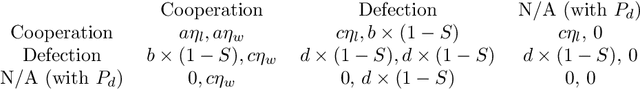
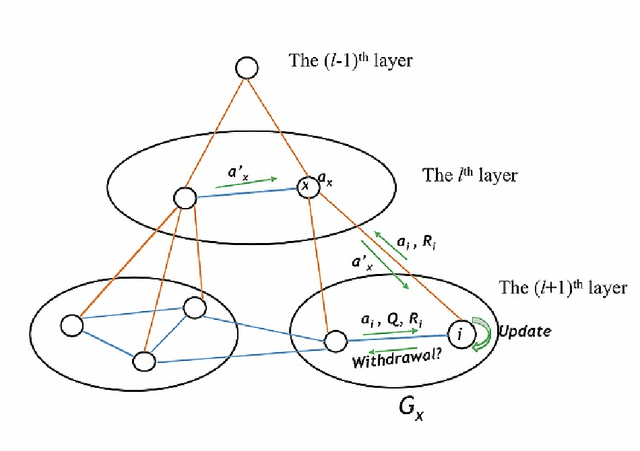
The complexity of cooperative behavior is a crucial issue in multiagent-based social simulation. In this paper, an agent-based model is proposed to study the evolution of cooperative hunting behaviors in an artificial society. In this model, the standard hunting game of stag is modified into a new situation with social hierarchy and penalty. The agent society is divided into multiple layers with supervisors and subordinates. In each layer, the society is divided into multiple clusters. A supervisor controls all subordinates in a cluster locally. Subordinates interact with rivals through reinforcement learning, and report learning information to their corresponding supervisor. Supervisors process the reported information through repeated affiliation-based aggregation and by information exchange with other supervisors, then pass down the reprocessed information to subordinates as guidance. Subordinates, in turn, update learning information according to guidance, following the "win stay, lose shift" strategy. Experiments are carried out to test the evolution of cooperation in this closed-loop semi-supervised emergent system with different parameters. We also study the variations and phase transitions in this game setting.