 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Surface the Unwritten Code of Science and Society
May 25, 2025



This paper calls on the research community not only to investigate how human biases are inherited by large language models (LLMs) but also to explore how these biases in LLMs can be leveraged to make society's "unwritten code" - such as implicit stereotypes and heuristics - visible and accessible for critique. We introduce a conceptual framework through a case study in science: uncovering hidden rules in peer review - the factors that reviewers care about but rarely state explicitly due to normative scientific expectations. The idea of the framework is to push LLMs to speak out their heuristics through generating self-consistent hypotheses - why one paper appeared stronger in reviewer scoring - among paired papers submitted to 45 computer science conferences, while iteratively searching deeper hypotheses from remaining pairs where existing hypotheses cannot explain. We observed that LLMs' normative priors about the internal characteristics of good science extracted from their self-talk, e.g. theoretical rigor, were systematically updated toward posteriors that emphasize storytelling about external connections, such as how the work is positioned and connected within and across literatures. This shift reveals the primacy of scientific myths about intrinsic properties driving scientific excellence rather than extrinsic contextualization and storytelling that influence conceptions of relevance and significance. Human reviewers tend to explicitly reward aspects that moderately align with LLMs' normative priors (correlation = 0.49) but avoid articulating contextualization and storytelling posteriors in their review comments (correlation = -0.14), despite giving implicit reward to them with positive scores. We discuss the broad applicability of the framework, leveraging LLMs as diagnostic tools to surface the tacit codes underlying human society, enabling more precisely targeted responsible AI.
Uncertainty Estimation for 3D Object Detection via Evidential Learning
Oct 31, 2024



3D object detection is an essential task for computer vision applications in autonomous vehicles and robotics. However, models often struggle to quantify detection reliability, leading to poor performance on unfamiliar scenes. We introduce a framework for quantifying uncertainty in 3D object detection by leveraging an evidential learning loss on Bird's Eye View representations in the 3D detector. These uncertainty estimates require minimal computational overhead and are generalizable across different architectures. We demonstrate both the efficacy and importance of these uncertainty estimates on identifying out-of-distribution scenes, poorly localized objects, and missing (false negative) detections; our framework consistently improves over baselines by 10-20% on average. Finally, we integrate this suite of tasks into a system where a 3D object detector auto-labels driving scenes and our uncertainty estimates verify label correctness before the labels are used to train a second model. Here, our uncertainty-driven verification results in a 1% improvement in mAP and a 1-2% improvement in NDS.
QUICK: Quantization-aware Interleaving and Conflict-free Kernel for efficient LLM inference
Feb 15, 2024



We introduce QUICK, a group of novel optimized CUDA kernels for the efficient inference of quantized Large Language Models (LLMs). QUICK addresses the shared memory bank-conflict problem of state-of-the-art mixed precision matrix multiplication kernels. Our method interleaves the quantized weight matrices of LLMs offline to skip the shared memory write-back after the dequantization. We demonstrate up to 1.91x speedup over existing kernels of AutoAWQ on larger batches and up to 1.94x throughput gain on representative LLM models on various NVIDIA GPU devices.
Squeezing Large-Scale Diffusion Models for Mobile
Jul 03, 2023The emergence of diffusion models has greatly broadened the scope of high-fidelity image synthesis, resulting in notable advancements in both practical implementation and academic research. With the active adoption of the model in various real-world applications, the need for on-device deployment has grown considerably. However, deploying large diffusion models such as Stable Diffusion with more than one billion parameters to mobile devices poses distinctive challenges due to the limited computational and memory resources, which may vary according to the device. In this paper, we present the challenges and solutions for deploying Stable Diffusion on mobile devices with TensorFlow Lite framework, which supports both iOS and Android devices. The resulting Mobile Stable Diffusion achieves the inference latency of smaller than 7 seconds for a 512x512 image generation on Android devices with mobile GPUs.
Active Learning for Deep Object Detection via Probabilistic Modeling
Mar 30, 2021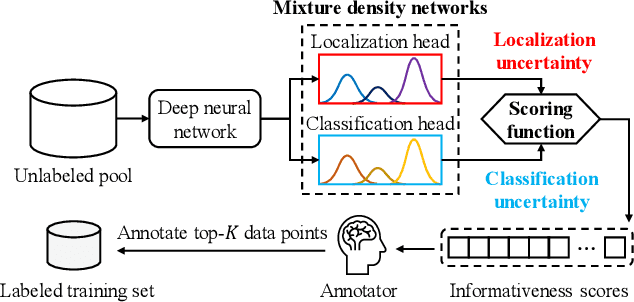
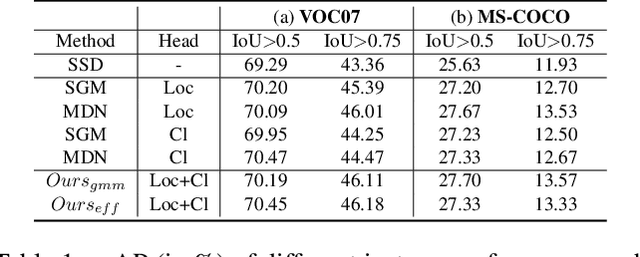
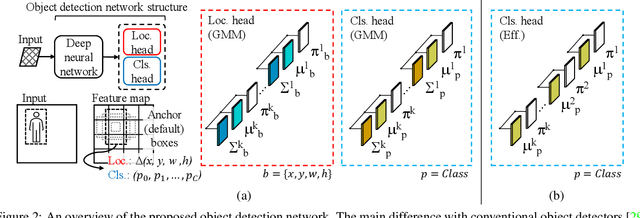
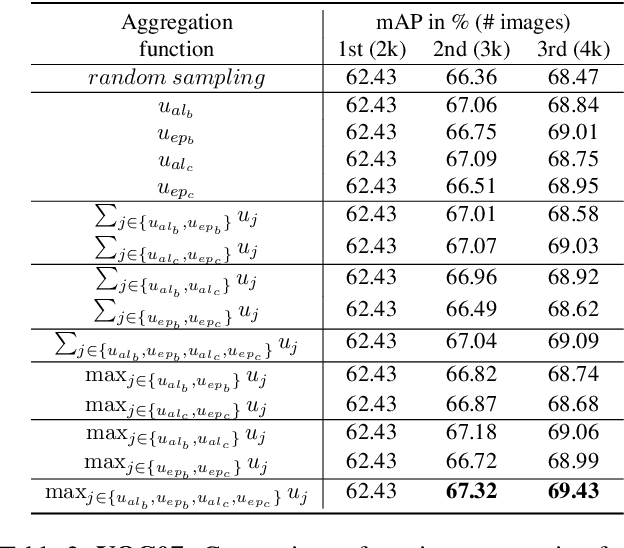
Active learning aims to reduce labeling costs by selecting only the most informative samples on a dataset. Few existing works have addressed active learning for object detection. Most of these methods are based on multiple models or are straightforward extensions of classification methods, hence estimate an image's informativeness using only the classification head. In this paper, we propose a novel deep active learning approach for object detection. Our approach relies on mixture density networks that estimate a probabilistic distribution for each localization and classification head's output. We explicitly estimate the aleatoric and epistemic uncertainty in a single forward pass of a single model. Our method uses a scoring function that aggregates these two types of uncertainties for both heads to obtain every image's informativeness score. We demonstrate the efficacy of our approach in PASCAL VOC and MS-COCO datasets. Our approach outperforms single-model based methods and performs on par with multi-model based methods at a fraction of the computing cost.
Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving
Apr 09, 2019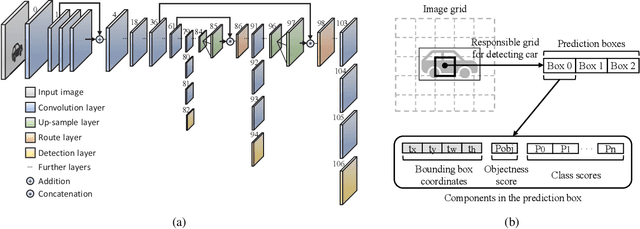
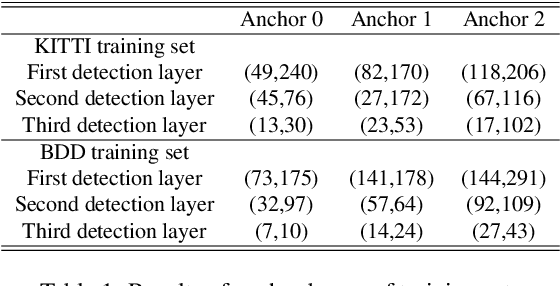
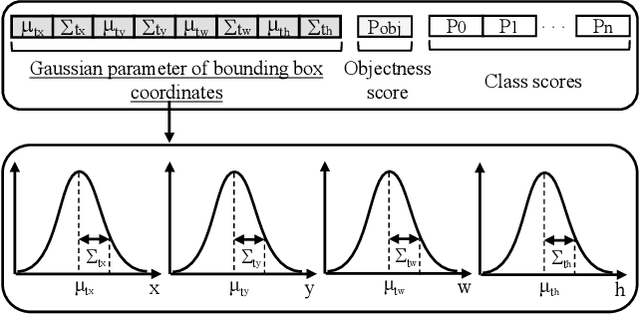
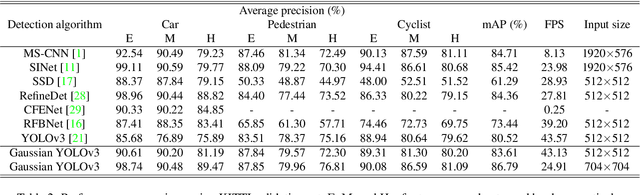
The use of object detection algorithms is becoming increasingly important in autonomous vehicles, and object detection at high accuracy and a fast inference speed is essential for safe autonomous driving. A false positive (FP) from a false localization during autonomous driving can lead to fatal accidents and hinder safe and efficient driving. Therefore, a detection algorithm that can cope with mislocalizations is required in autonomous driving applications. This paper proposes a method for improving the detection accuracy while supporting a real-time operation by modeling the bounding box (bbox) of YOLOv3, which is the most representative of one-stage detectors, with a Gaussian parameter and redesigning the loss function. In addition, this paper proposes a method for predicting the localization uncertainty that indicates the reliability of bbox. By using the predicted localization uncertainty during the detection process, the proposed schemes can significantly reduce the FP and increase the true positive (TP), thereby improving the accuracy. Compared to a conventional YOLOv3, the proposed algorithm, Gaussian YOLOv3, improves the mean average precision (mAP) by 3.09 and 3.5 on the KITTI and Berkeley deep drive (BDD) datasets, respectively. In addition, on the same datasets, the proposed algorithm can reduce the FP by 41.40% and 40.62%, and increase the TP by 7.26% and 4.3%, respectively. Nevertheless, the proposed algorithm is capable of real-time detection at faster than 42 frames per second (fps).