 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Pose Transfer for Unrigged Stylized 3D Characters
May 31, 2023



Transferring the pose of a reference avatar to stylized 3D characters of various shapes is a fundamental task in computer graphics. Existing methods either require the stylized characters to be rigged, or they use the stylized character in the desired pose as ground truth at training. We present a zero-shot approach that requires only the widely available deformed non-stylized avatars in training, and deforms stylized characters of significantly different shapes at inference. Classical methods achieve strong generalization by deforming the mesh at the triangle level, but this requires labelled correspondences. We leverage the power of local deformation, but without requiring explicit correspondence labels. We introduce a semi-supervised shape-understanding module to bypass the need for explicit correspondences at test time, and an implicit pose deformation module that deforms individual surface points to match the target pose. Furthermore, to encourage realistic and accurate deformation of stylized characters, we introduce an efficient volume-based test-time training procedure. Because it does not need rigging, nor the deformed stylized character at training time, our model generalizes to categories with scarce annotation, such as stylized quadrupeds. Extensive experiments demonstrate the effectiveness of the proposed method compared to the state-of-the-art approaches trained with comparable or more supervision. Our project page is available at https://jiashunwang.github.io/ZPT
TUVF: Learning Generalizable Texture UV Radiance Fields
May 10, 2023



Textures are a vital aspect of creating visually appealing and realistic 3D models. In this paper, we study the problem of generating high-fidelity texture given shapes of 3D assets, which has been relatively less explored compared with generic 3D shape modeling. Our goal is to facilitate a controllable texture generation process, such that one texture code can correspond to a particular appearance style independent of any input shapes from a category. We introduce Texture UV Radiance Fields (TUVF) that generate textures in a learnable UV sphere space rather than directly on the 3D shape. This allows the texture to be disentangled from the underlying shape and transferable to other shapes that share the same UV space, i.e., from the same category. We integrate the UV sphere space with the radiance field, which provides a more efficient and accurate representation of textures than traditional texture maps. We perform our experiments on real-world object datasets where we achieve not only realistic synthesis but also substantial improvements over state-of-the-arts on texture controlling and editing. Project Page: https://www.anjiecheng.me/TUVF
Affordance Diffusion: Synthesizing Hand-Object Interactions
Mar 25, 2023



Recent successes in image synthesis are powered by large-scale diffusion models. However, most methods are currently limited to either text- or image-conditioned generation for synthesizing an entire image, texture transfer or inserting objects into a user-specified region. In contrast, in this work we focus on synthesizing complex interactions (ie, an articulated hand) with a given object. Given an RGB image of an object, we aim to hallucinate plausible images of a human hand interacting with it. We propose a two-step generative approach: a LayoutNet that samples an articulation-agnostic hand-object-interaction layout, and a ContentNet that synthesizes images of a hand grasping the object given the predicted layout. Both are built on top of a large-scale pretrained diffusion model to make use of its latent representation. Compared to baselines, the proposed method is shown to generalize better to novel objects and perform surprisingly well on out-of-distribution in-the-wild scenes of portable-sized objects. The resulting system allows us to predict descriptive affordance information, such as hand articulation and approaching orientation. Project page: https://judyye.github.io/affordiffusion-www
Open-Vocabulary Panoptic Segmentation with Text-to-Image Diffusion Models
Mar 11, 2023We present ODISE: Open-vocabulary DIffusion-based panoptic SEgmentation, which unifies pre-trained text-image diffusion and discriminative models to perform open-vocabulary panoptic segmentation. Text-to-image diffusion models have shown the remarkable capability of generating high-quality images with diverse open-vocabulary language descriptions. This demonstrates that their internal representation space is highly correlated with open concepts in the real world. Text-image discriminative models like CLIP, on the other hand, are good at classifying images into open-vocabulary labels. We propose to leverage the frozen representation of both these models to perform panoptic segmentation of any category in the wild. Our approach outperforms the previous state of the art by significant margins on both open-vocabulary panoptic and semantic segmentation tasks. In particular, with COCO training only, our method achieves 23.4 PQ and 30.0 mIoU on the ADE20K dataset, with 8.3 PQ and 7.9 mIoU absolute improvement over the previous state-of-the-art. Project page is available at https://jerryxu.net/ODISE .
DIP: Differentiable Interreflection-aware Physics-based Inverse Rendering
Dec 09, 2022



We present a physics-based inverse rendering method that learns the illumination, geometry, and materials of a scene from posed multi-view RGB images. To model the illumination of a scene, existing inverse rendering works either completely ignore the indirect illumination or model it by coarse approximations, leading to sub-optimal illumination, geometry, and material prediction of the scene. In this work, we propose a physics-based illumination model that explicitly traces the incoming indirect lights at each surface point based on interreflection, followed by estimating each identified indirect light through an efficient neural network. Furthermore, we utilize the Leibniz's integral rule to resolve non-differentiability in the proposed illumination model caused by one type of environment light -- the tangent lights. As a result, the proposed interreflection-aware illumination model can be learned end-to-end together with geometry and materials estimation. As a side product, our physics-based inverse rendering model also facilitates flexible and realistic material editing as well as relighting. Extensive experiments on both synthetic and real-world datasets demonstrate that the proposed method performs favorably against existing inverse rendering methods on novel view synthesis and inverse rendering.
Autoregressive 3D Shape Generation via Canonical Mapping
Apr 05, 2022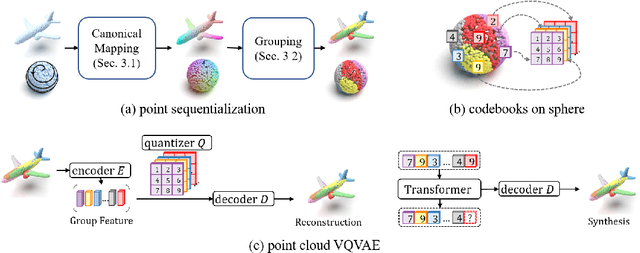
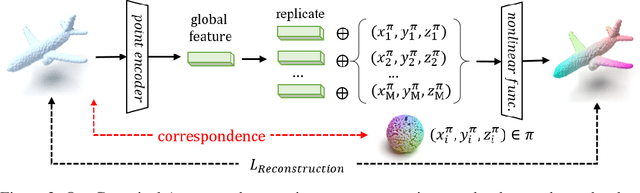
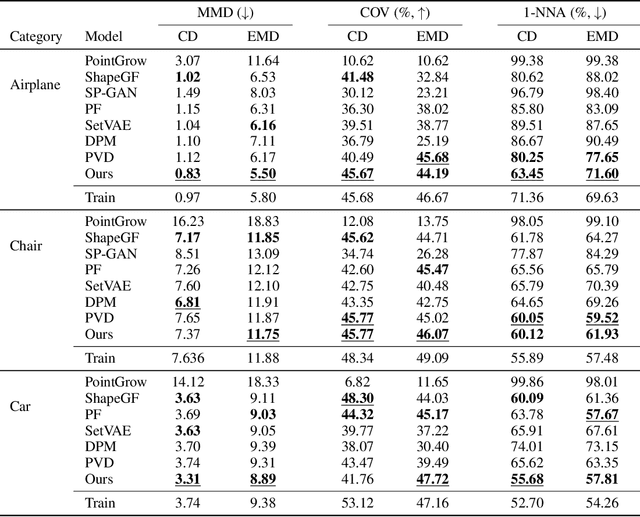
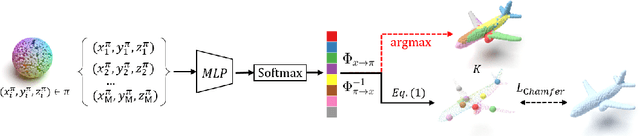
With the capacity of modeling long-range dependencies in sequential data, transformers have shown remarkable performances in a variety of generative tasks such as image, audio, and text generation. Yet, taming them in generating less structured and voluminous data formats such as high-resolution point clouds have seldom been explored due to ambiguous sequentialization processes and infeasible computation burden. In this paper, we aim to further exploit the power of transformers and employ them for the task of 3D point cloud generation. The key idea is to decompose point clouds of one category into semantically aligned sequences of shape compositions, via a learned canonical space. These shape compositions can then be quantized and used to learn a context-rich composition codebook for point cloud generation. Experimental results on point cloud reconstruction and unconditional generation show that our model performs favorably against state-of-the-art approaches. Furthermore, our model can be easily extended to multi-modal shape completion as an application for conditional shape generation.
CoordGAN: Self-Supervised Dense Correspondences Emerge from GANs
Mar 30, 2022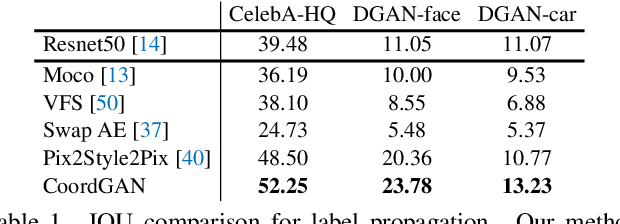
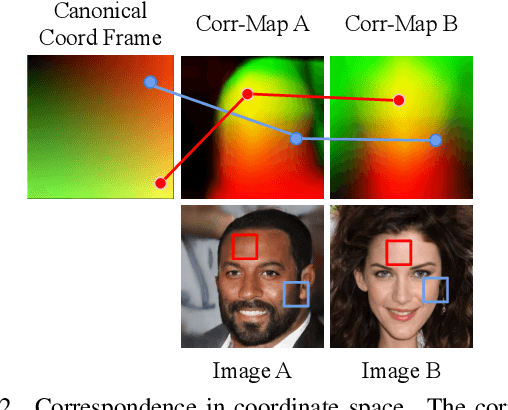
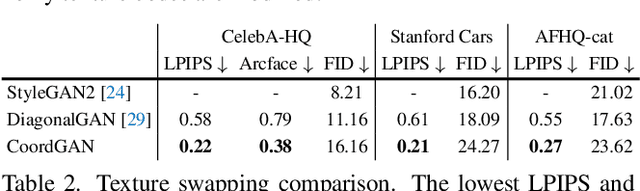
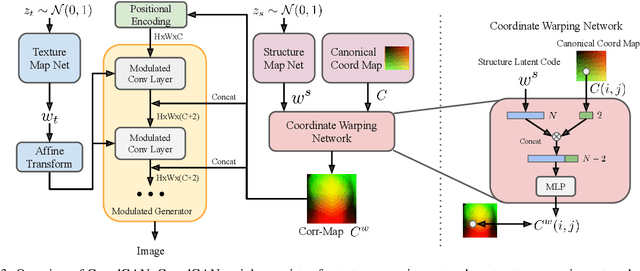
Recent advances show that Generative Adversarial Networks (GANs) can synthesize images with smooth variations along semantically meaningful latent directions, such as pose, expression, layout, etc. While this indicates that GANs implicitly learn pixel-level correspondences across images, few studies explored how to extract them explicitly. In this work, we introduce Coordinate GAN (CoordGAN), a structure-texture disentangled GAN that learns a dense correspondence map for each generated image. We represent the correspondence maps of different images as warped coordinate frames transformed from a canonical coordinate frame, i.e., the correspondence map, which describes the structure (e.g., the shape of a face), is controlled via a transformation. Hence, finding correspondences boils down to locating the same coordinate in different correspondence maps. In CoordGAN, we sample a transformation to represent the structure of a synthesized instance, while an independent texture branch is responsible for rendering appearance details orthogonal to the structure. Our approach can also extract dense correspondence maps for real images by adding an encoder on top of the generator. We quantitatively demonstrate the quality of the learned dense correspondences through segmentation mask transfer on multiple datasets. We also show that the proposed generator achieves better structure and texture disentanglement compared to existing approaches. Project page: https://jitengmu.github.io/CoordGAN/
GroupViT: Semantic Segmentation Emerges from Text Supervision
Feb 22, 2022
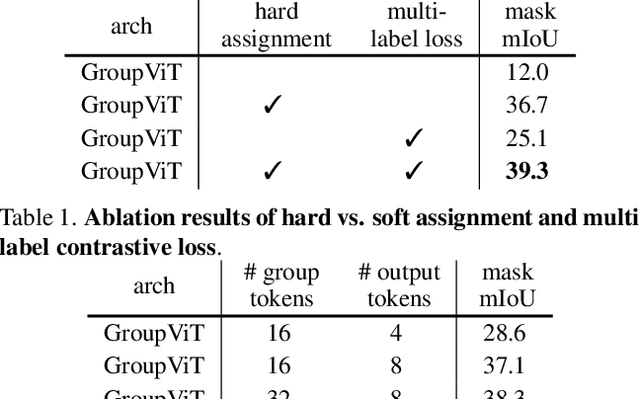
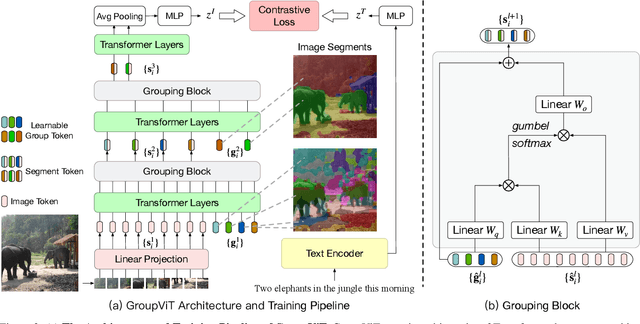
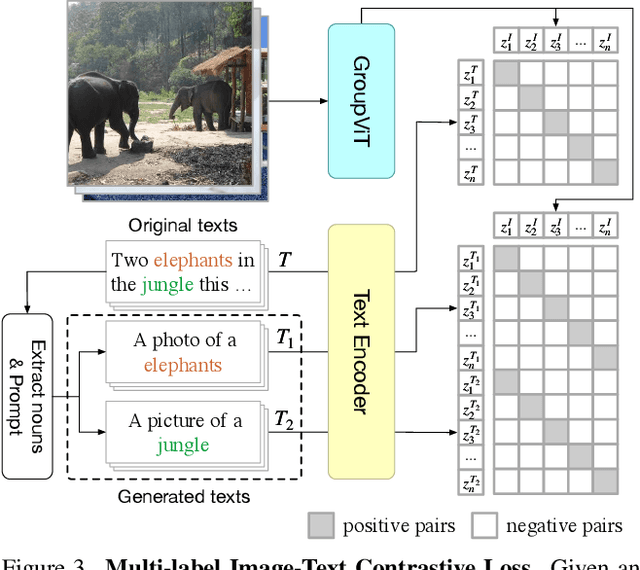
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 51.2% mIoU on the PASCAL VOC 2012 and 22.3% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision. Project page is available at https://jerryxu.net/GroupViT.
Learning Continuous Environment Fields via Implicit Functions
Nov 27, 2021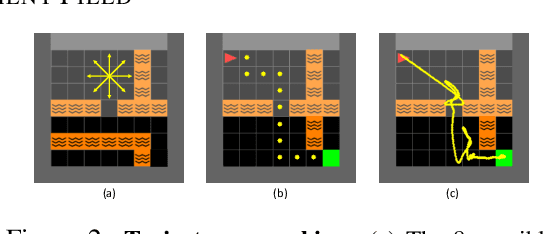
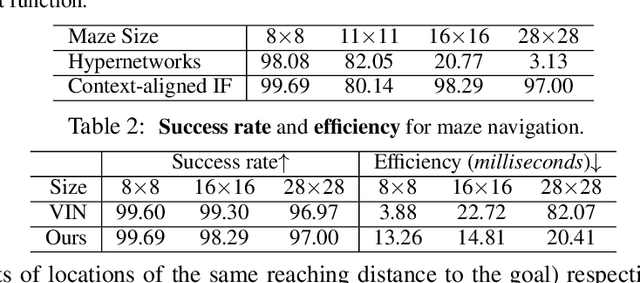
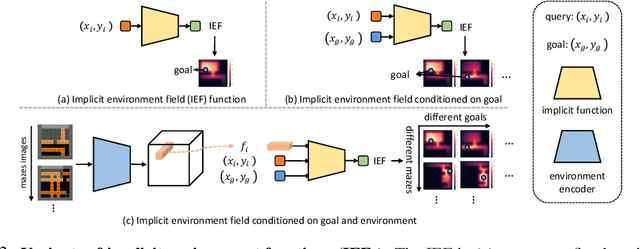
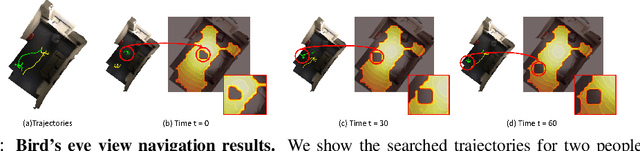
We propose a novel scene representation that encodes reaching distance -- the distance between any position in the scene to a goal along a feasible trajectory. We demonstrate that this environment field representation can directly guide the dynamic behaviors of agents in 2D mazes or 3D indoor scenes. Our environment field is a continuous representation and learned via a neural implicit function using discretely sampled training data. We showcase its application for agent navigation in 2D mazes, and human trajectory prediction in 3D indoor environments. To produce physically plausible and natural trajectories for humans, we additionally learn a generative model that predicts regions where humans commonly appear, and enforce the environment field to be defined within such regions. Extensive experiments demonstrate that the proposed method can generate both feasible and plausible trajectories efficiently and accurately.
Self-Supervised Object Detection via Generative Image Synthesis
Oct 19, 2021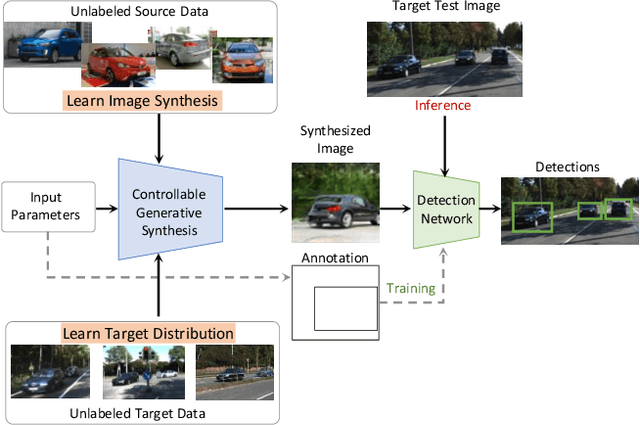
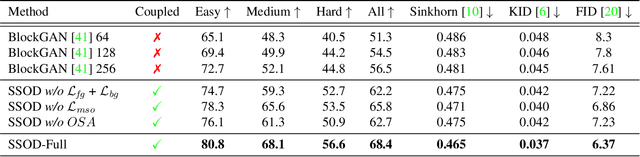
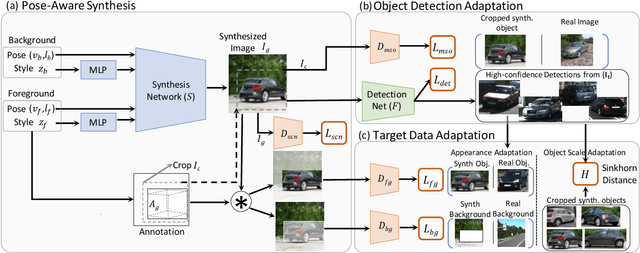
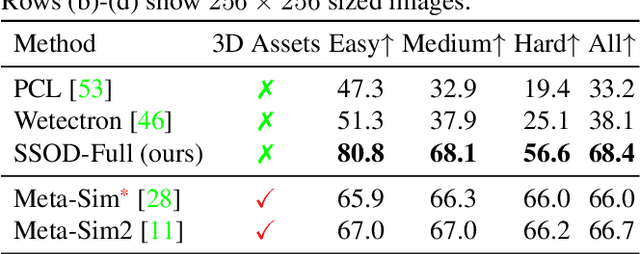
We present SSOD, the first end-to-end analysis-by synthesis framework with controllable GANs for the task of self-supervised object detection. We use collections of real world images without bounding box annotations to learn to synthesize and detect objects. We leverage controllable GANs to synthesize images with pre-defined object properties and use them to train object detectors. We propose a tight end-to-end coupling of the synthesis and detection networks to optimally train our system. Finally, we also propose a method to optimally adapt SSOD to an intended target data without requiring labels for it. For the task of car detection, on the challenging KITTI and Cityscapes datasets, we show that SSOD outperforms the prior state-of-the-art purely image-based self-supervised object detection method Wetectron. Even without requiring any 3D CAD assets, it also surpasses the state-of-the-art rendering based method Meta-Sim2. Our work advances the field of self-supervised object detection by introducing a successful new paradigm of using controllable GAN-based image synthesis for it and by significantly improving the baseline accuracy of the task. We open-source our code at https://github.com/NVlabs/SSOD.