 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the Label Distributions for Weakly-Supervised Semantic Segmentation
Mar 20, 2024



Weakly-Supervised Semantic Segmentation (WSSS) aims to train segmentation models by weak labels, which is receiving significant attention due to its low annotation cost. Existing approaches focus on generating pseudo labels for supervision while largely ignoring to leverage the inherent semantic correlation among different pseudo labels. We observe that pseudo-labeled pixels that are close to each other in the feature space are more likely to share the same class, and those closer to the distribution centers tend to have higher confidence. Motivated by this, we propose to model the underlying label distributions and employ cross-label constraints to generate more accurate pseudo labels. In this paper, we develop a unified WSSS framework named Adaptive Gaussian Mixtures Model, which leverages a GMM to model the label distributions. Specifically, we calculate the feature distribution centers of pseudo-labeled pixels and build the GMM by measuring the distance between the centers and each pseudo-labeled pixel. Then, we introduce an Online Expectation-Maximization (OEM) algorithm and a novel maximization loss to optimize the GMM adaptively, aiming to learn more discriminative decision boundaries between different class-wise Gaussian mixtures. Based on the label distributions, we leverage the GMM to generate high-quality pseudo labels for more reliable supervision. Our framework is capable of solving different forms of weak labels: image-level labels, points, scribbles, blocks, and bounding-boxes. Extensive experiments on PASCAL, COCO, Cityscapes, and ADE20K datasets demonstrate that our framework can effectively provide more reliable supervision and outperform the state-of-the-art methods under all settings. Code will be available at https://github.com/Luffy03/AGMM-SASS.
GeReA: Question-Aware Prompt Captions for Knowledge-based Visual Question Answering
Feb 04, 2024Knowledge-based visual question answering (VQA) requires world knowledge beyond the image for accurate answer. Recently, instead of extra knowledge bases, a large language model (LLM) like GPT-3 is activated as an implicit knowledge engine to jointly acquire and reason the necessary knowledge for answering by converting images into textual information (e.g., captions and answer candidates). However, such conversion may introduce irrelevant information, which causes the LLM to misinterpret images and ignore visual details crucial for accurate knowledge. We argue that multimodal large language model (MLLM) is a better implicit knowledge engine than the LLM for its superior capability of visual understanding. Despite this, how to activate the capacity of MLLM as the implicit knowledge engine has not been explored yet. Therefore, we propose GeReA, a generate-reason framework that prompts a MLLM like InstructBLIP with question relevant vision and language information to generate knowledge-relevant descriptions and reasons those descriptions for knowledge-based VQA. Specifically, the question-relevant image regions and question-specific manual prompts are encoded in the MLLM to generate the knowledge relevant descriptions, referred to as question-aware prompt captions. After that, the question-aware prompt captions, image-question pair, and similar samples are sent into the multi-modal reasoning model to learn a joint knowledge-image-question representation for answer prediction. GeReA unlocks the use of MLLM as the implicit knowledge engine, surpassing all previous state-of-the-art methods on OK-VQA and A-OKVQA datasets, with test accuracies of 66.5% and 63.3% respectively. Our code will be released at https://github.com/Upper9527/GeReA.
Hyperspectral Image Fusion via Logarithmic Low-rank Tensor Ring Decomposition
Oct 16, 2023



Integrating a low-spatial-resolution hyperspectral image (LR-HSI) with a high-spatial-resolution multispectral image (HR-MSI) is recognized as a valid method for acquiring HR-HSI. Among the current fusion approaches, the tensor ring (TR) decomposition-based method has received growing attention owing to its superior performance on preserving the spatial-spectral correlation. Furthermore, the low-rank property in some TR factors has been exploited via the matrix nuclear norm regularization along mode-2. On the other hand, the tensor nuclear norm (TNN)-based approaches have recently demonstrated to be more efficient on keeping high-dimensional low-rank structures in tensor recovery. Here, we study the low-rankness of TR factors from the TNN perspective and consider the mode-2 logarithmic TNN (LTNN) on each TR factor. A novel fusion model is proposed by incorporating this LTNN regularization and the weighted total variation which is to promote the continuity of HR-HSI in the spatial-spectral domain. Meanwhile, we have devised a highly efficient proximal alternating minimization algorithm to solve the proposed model. The experimental results indicate that our method improves the visual quality and exceeds the existing state-of-the-art fusion approaches with respect to various quantitative metrics.
VPUFormer: Visual Prompt Unified Transformer for Interactive Image Segmentation
Jun 11, 2023



The integration of diverse visual prompts like clicks, scribbles, and boxes in interactive image segmentation could significantly facilitate user interaction as well as improve interaction efficiency. Most existing studies focus on a single type of visual prompt by simply concatenating prompts and images as input for segmentation prediction, which suffers from low-efficiency prompt representation and weak interaction issues. This paper proposes a simple yet effective Visual Prompt Unified Transformer (VPUFormer), which introduces a concise unified prompt representation with deeper interaction to boost the segmentation performance. Specifically, we design a Prompt-unified Encoder (PuE) by using Gaussian mapping to generate a unified one-dimensional vector for click, box, and scribble prompts, which well captures users' intentions as well as provides a denser representation of user prompts. In addition, we present a Prompt-to-Pixel Contrastive Loss (P2CL) that leverages user feedback to gradually refine candidate semantic features, aiming to bring image semantic features closer to the features that are similar to the user prompt, while pushing away those image semantic features that are dissimilar to the user prompt, thereby correcting results that deviate from expectations. On this basis, our approach injects prompt representations as queries into Dual-cross Merging Attention (DMA) blocks to perform a deeper interaction between image and query inputs. A comprehensive variety of experiments on seven challenging datasets demonstrates that the proposed VPUFormer with PuE, DMA, and P2CL achieves consistent improvements, yielding state-of-the-art segmentation performance. Our code will be made publicly available at https://github.com/XuZhang1211/VPUFormer.
AdaptiveClick: Clicks-aware Transformer with Adaptive Focal Loss for Interactive Image Segmentation
May 07, 2023Interactive Image Segmentation (IIS) has emerged as a promising technique for decreasing annotation time. Substantial progress has been made in pre- and post-processing for IIS, but the critical issue of interaction ambiguity notably hindering segmentation quality, has been under-researched. To address this, we introduce AdaptiveClick -- a clicks-aware transformer incorporating an adaptive focal loss, which tackles annotation inconsistencies with tools for mask- and pixel-level ambiguity resolution. To the best of our knowledge, AdaptiveClick is the first transformer-based, mask-adaptive segmentation framework for IIS. The key ingredient of our method is the Clicks-aware Mask-adaptive Transformer Decoder (CAMD), which enhances the interaction between clicks and image features. Additionally, AdaptiveClick enables pixel-adaptive differentiation of hard and easy samples in the decision space, independent of their varying distributions. This is primarily achieved by optimizing a generalized Adaptive Focal Loss (AFL) with a theoretical guarantee, where two adaptive coefficients control the ratio of gradient values for hard and easy pixels. Our analysis reveals that the commonly used Focal and BCE losses can be considered special cases of the proposed AFL loss. With a plain ViT backbone, extensive experimental results on nine datasets demonstrate the superiority of AdaptiveClick compared to state-of-the-art methods. Code will be publicly available at https://github.com/lab206/AdaptiveClick.
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition
May 05, 2023



Previous methods for dynamic facial expression recognition (DFER) in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. Transformer-based methods for DFER can achieve better performances but result in higher FLOPs and computational costs. To solve these problems, the local-global spatio-temporal Transformer (LOGO-Former) is proposed to capture discriminative features within each frame and model contextual relationships among frames while balancing the complexity. Based on the priors that facial muscles move locally and facial expressions gradually change, we first restrict both the space attention and the time attention to a local window to capture local interactions among feature tokens. Furthermore, we perform the global attention by querying a token with features from each local window iteratively to obtain long-range information of the whole video sequence. In addition, we propose the compact loss regularization term to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39K) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for DFER.
Learning to Locate Visual Answer in Video Corpus Using Question
Oct 11, 2022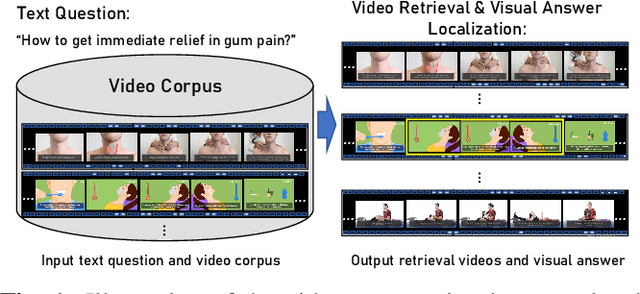
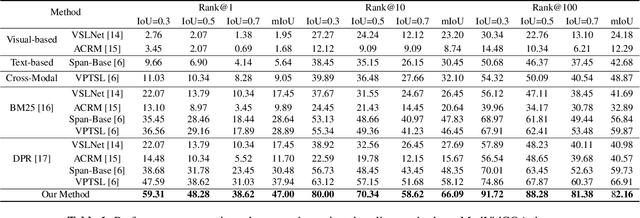
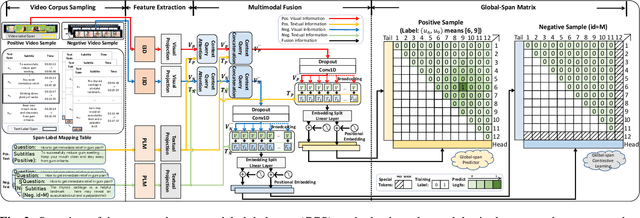

We introduce a novel task, named video corpus visual answer localization (VCVAL), which aims to locate the visual answer in a large collection of untrimmed, unsegmented instructional videos using a natural language question. This task requires a range of skills - the interaction between vision and language, video retrieval, passage comprehension, and visual answer localization. To solve these, we propose a cross-modal contrastive global-span (CCGS) method for the VCVAL, jointly training the video corpus retrieval and visual answer localization tasks. More precisely, we enhance the video question-answer semantic by adding element-wise visual information into the pre-trained language model, and designing a novel global-span predictor through fusion information to locate the visual answer point. The Global-span contrastive learning is adopted to differentiate the span point in the positive and negative samples with the global-span matrix. We have reconstructed a new dataset named MedVidCQA and benchmarked the VCVAL task, where the proposed method achieves state-of-the-art (SOTA) both in the video corpus retrieval and visual answer localization tasks. Most importantly, we pave a new path for understanding the instructional videos, performing detailed analyses on extensive experiments, which ushers in further research.
Scene-Aware Prompt for Multi-modal Dialogue Understanding and Generation
Jul 05, 2022
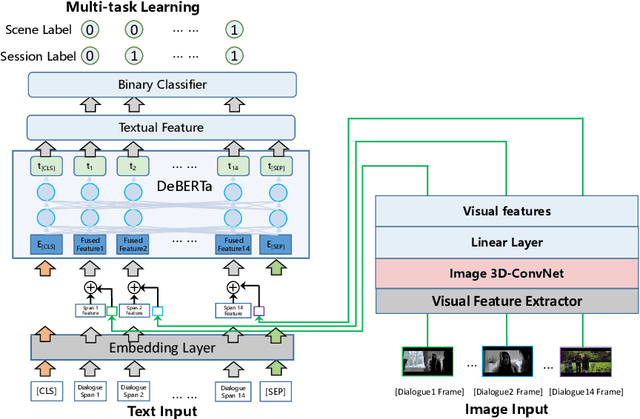
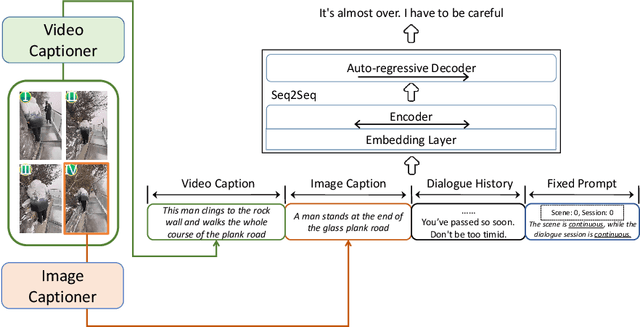
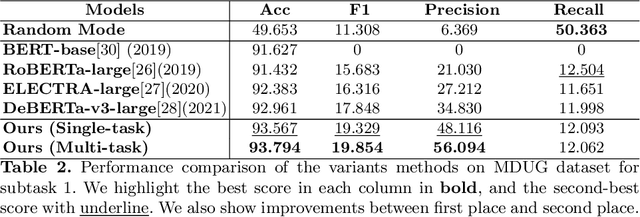
This paper introduces the schemes of Team LingJing's experiments in NLPCC-2022-Shared-Task-4 Multi-modal Dialogue Understanding and Generation (MDUG). The MDUG task can be divided into two phases: multi-modal context understanding and response generation. To fully leverage the visual information for both scene understanding and dialogue generation, we propose the scene-aware prompt for the MDUG task. Specifically, we utilize the multi-tasking strategy for jointly modelling the scene- and session- multi-modal understanding. The visual captions are adopted to aware the scene information, while the fixed-type templated prompt based on the scene- and session-aware labels are used to further improve the dialogue generation performance. Extensive experimental results show that the proposed method has achieved state-of-the-art (SOTA) performance compared with other competitive methods, where we rank the 1-st in all three subtasks in this MDUG competition.
Spatio-Temporal Transformer for Dynamic Facial Expression Recognition in the Wild
May 10, 2022
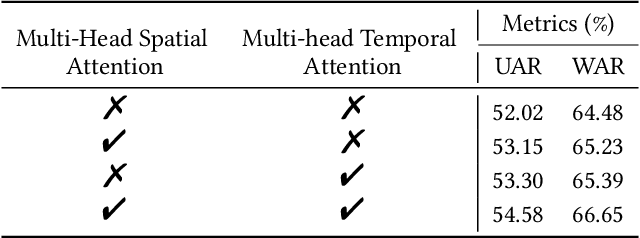
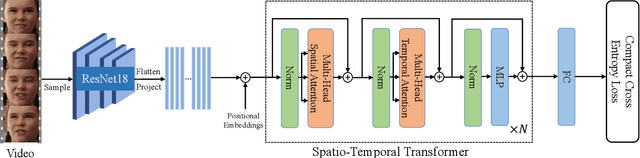
Previous methods for dynamic facial expression in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. To solve this problem, we propose the spatio-temporal Transformer (STT) to capture discriminative features within each frame and model contextual relationships among frames. Spatio-temporal dependencies are captured and integrated by our unified Transformer. Specifically, given an image sequence consisting of multiple frames as input, we utilize the CNN backbone to translate each frame into a visual feature sequence. Subsequently, the spatial attention and the temporal attention within each block are jointly applied for learning spatio-temporal representations at the sequence level. In addition, we propose the compact softmax cross entropy loss to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and AFEW) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for dynamic facial expression recognition. The source code and the training logs will be made publicly available.
LingYi: Medical Conversational Question Answering System based on Multi-modal Knowledge Graphs
Apr 20, 2022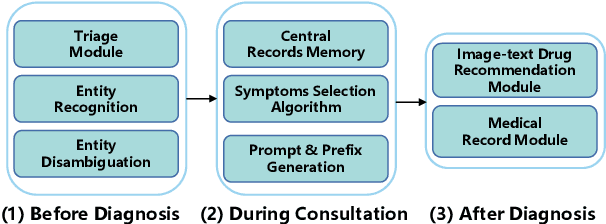
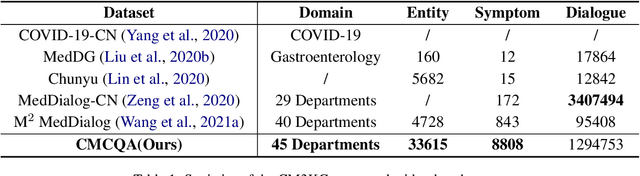
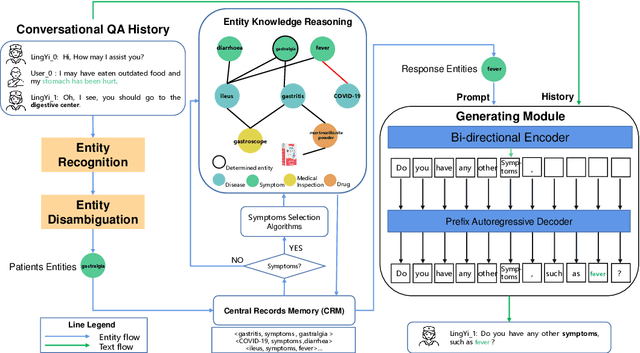
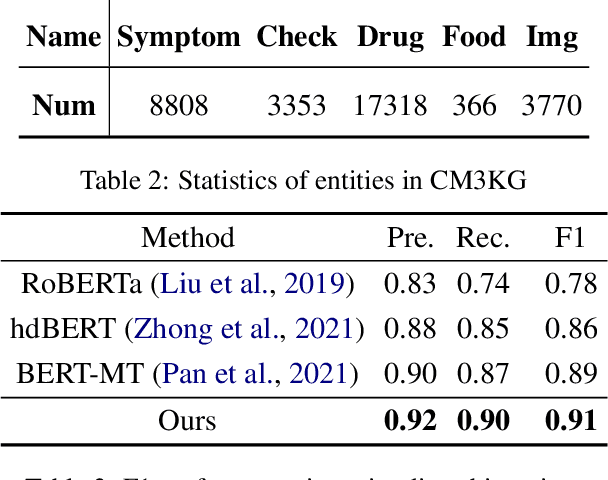
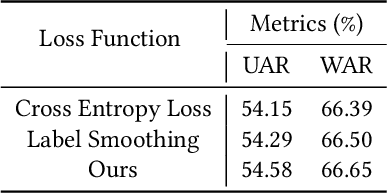
The medical conversational system can relieve the burden of doctors and improve the efficiency of healthcare, especially during the pandemic. This paper presents a medical conversational question answering (CQA) system based on the multi-modal knowledge graph, namely "LingYi", which is designed as a pipeline framework to maintain high flexibility. Our system utilizes automated medical procedures including medical triage, consultation, image-text drug recommendation and record. To conduct knowledge-grounded dialogues with patients, we first construct a Chinese Medical Multi-Modal Knowledge Graph (CM3KG) and collect a large-scale Chinese Medical CQA (CMCQA) dataset. Compared with the other existing medical question-answering systems, our system adopts several state-of-the-art technologies including medical entity disambiguation and medical dialogue generation, which is more friendly to provide medical services to patients. In addition, we have open-sourced our codes which contain back-end models and front-end web pages at https://github.com/WENGSYX/LingYi. The datasets including CM3KG at https://github.com/WENGSYX/CM3KG and CMCQA at https://github.com/WENGSYX/CMCQA are also released to further promote future research.