 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSum: Synergizing LLM Reasoning and Summarization with Reinforcement Learning
Jun 11, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is a central technique for improving long-horizon reasoning in Large Language Models (LLMs). However, existing RLVR methods often encourage unnecessarily long reasoning rollouts, which can degrade reasoning coherence and exhaust the available context budget. Existing approaches to long-context organization often depend on external mechanisms to organize rollouts, rather than enabling the model to manage its own reasoning trajectory. To address this limitation, we propose ReSum, a novel RLVR framework that enables LLMs to compress and organize their reasoning trajectories through self-summarization. Our pilot studies show that self-summarization stabilizes generation by lowering token-level entropy, and that introducing a ``summarization'' phrase can substantially mitigate errors propagated from an incorrect rollout prefix. Motivated by these findings, ReSum adopts a summarization-aware adaptive rollout mechanism that contrastively evaluates whether self-summarization benefits the ongoing reasoning process. Specifically, when the model spontaneously triggers self-summarization, ReSum masks the summarization phrase to create a contrastive branch; for non-summarization positions, it instead randomly injects the phrase to create a matched branch. We further design a summarization-aware advantage to enable finer-grained comparison between contrastive rollout trajectories. Extensive experiments show that ReSum improves performance at an average of 4\% while reducing rollout length by 18.6\%.
APPO: Agentic Procedural Policy Optimization
Jun 10, 2026Recent advances in agentic Reinforcement Learning (RL) have substantially improved the multi-turn tool-use capabilities of large language model agents. However, most existing methods assign credit over coarse heuristic units, such as tool-call boundaries or fixed workflows, making it difficult to identify which intermediate decisions influence downstream outcomes. In this work, we study agentic RL from two perspectives: \textit{where to branch and how to assign credit after branching}. Our pilot analysis shows that influential decision points are broadly distributed throughout the generated sequence rather than concentrated at tool calls, while token entropy alone does not reliably reflect their impact on final outcomes. Motivated by these observations, we propose \textbf{Agentic Procedural Policy Optimization (APPO)}, which shifts branching and credit assignment from coarse interaction units to fine-grained decision points in the sequence. APPO selects branching locations using a Branching Score that combines token uncertainty with policy-induced likelihood gains of subsequent continuations, enabling more targeted exploration while filtering out spurious high-entropy positions. It further introduces procedure-level advantage scaling to better distribute credit across branched rollouts. Experiments on 13 benchmarks show that APPO consistently improves strong agentic RL baselines by nearly 4 points, while keeping efficient tool-calls and maintaining behavior interpretability.
Role-Agent: Bootstrapping LLM Agents via Dual-Role Evolution
Jun 09, 2026Although Large Language Model (LLM) agents have demonstrated strong performance on complex tasks, their learning is often limited by inefficient interaction feedback and static training environments, which hinder broader generalization. To address these limitations, this paper introduces Role-Agent, \textcolor{black}{a framework} that harnesses a single LLM to function concurrently as both the agent and the environment, enabling a bootstrapped co-evolution. Role-Agent comprises two synergistic components: World-In-Agent (WIA) and Agent-In-World (AIW). In WIA, the LLM acts as the agent and predicts future states after each action; the alignment between predicted and actual states is then used as a process reward, encouraging environment-aware reasoning. In AIW, the LLM analyzes failure modes from failed trajectories and retrieves tasks with similar failure patterns, thereby reshaping the training data distribution for targeted practice. Experiments on multiple benchmarks show that Role-Agent consistently improves performance, yielding an average gain of over 4\% over strong baselines.
Learning Agentic Policy from Action Guidance
May 12, 2026Agentic reinforcement learning (RL) for Large Language Models (LLMs) critically depends on the exploration capability of the base policy, as training signals emerge only within its in-capability region. For tasks where the base policy cannot reach reward states, additional training or external guidance is needed to recover effective learning signals. Rather than relying on costly iterative supervised fine tuning (SFT), we exploit the abundant action data generated in everyday human interactions. We propose \textsc{ActGuide-RL}, which injects action data as plan-style reference guidance, enabling the agentic policy to overcome reachability barriers to reward states. Guided and unguided rollouts are then jointly optimized via mixed-policy training, internalizing the exploration gains back into the unguided policy. Motivated by a theoretical and empirical analysis of the benefit-risk trade-off, we adopt a minimal intervention principle that invokes guidance only as an adaptive fallback, matching task difficulty while minimizing off-policy risk. On search-agent benchmarks, \textsc{ActGuide-RL} substantially improves over zero RL (+10.7 pp on GAIA and +19 pp on XBench with Qwen3-4B), and performs on par with the SFT+RL pipeline without any cold start. This suggests a new paradigm for agentic RL that reduces the reliance on heavy SFT data by using scalable action guidance instead.
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
Apr 09, 2026Large language model (LLM) agents such as OpenClaw rely on reusable skills to perform complex tasks, yet these skills remain largely static after deployment. As a result, similar workflows, tool usage patterns, and failure modes are repeatedly rediscovered across users, preventing the system from improving with experience. While interactions from different users provide complementary signals about when a skill works or fails, existing systems lack a mechanism to convert such heterogeneous experiences into reliable skill updates. To address these issues, we present SkillClaw, a framework for collective skill evolution in multi-user agent ecosystems, which treats cross-user and over-time interactions as the primary signal for improving skills. SkillClaw continuously aggregates trajectories generated during use and processes them with an autonomous evolver, which identifies recurring behavioral patterns and translates them into updates to the skill set by refining existing skills or extending them with new capabilities. The resulting skills are maintained in a shared repository and synchronized across users, allowing improvements discovered in one context to propagate system-wide while requiring no additional effort from users. By integrating multi-user experience into ongoing skill updates, SkillClaw enables cross-user knowledge transfer and cumulative capability improvement, and experiments on WildClawBench show that limited interaction and feedback, it significantly improves the performance of Qwen3-Max in real-world agent scenarios.
Where and What Matters: Sensitivity-Aware Task Vectors for Many-Shot Multimodal In-Context Learning
Nov 11, 2025Large Multimodal Models (LMMs) have shown promising in-context learning (ICL) capabilities, but scaling to many-shot settings remains difficult due to limited context length and high inference cost. To address these challenges, task-vector-based methods have been explored by inserting compact representations of many-shot in-context demonstrations into model activations. However, existing task-vector-based methods either overlook the importance of where to insert task vectors or struggle to determine suitable values for each location. To this end, we propose a novel Sensitivity-aware Task Vector insertion framework (STV) to figure out where and what to insert. Our key insight is that activation deltas across query-context pairs exhibit consistent structural patterns, providing a reliable cue for insertion. Based on the identified sensitive-aware locations, we construct a pre-clustered activation bank for each location by clustering the activation values, and then apply reinforcement learning to choose the most suitable one to insert. We evaluate STV across a range of multimodal models (e.g., Qwen-VL, Idefics-2) and tasks (e.g., VizWiz, OK-VQA), demonstrating its effectiveness and showing consistent improvements over previous task-vector-based methods with strong generalization.
DrVideo: Document Retrieval Based Long Video Understanding
Jun 18, 2024



Existing methods for long video understanding primarily focus on videos only lasting tens of seconds, with limited exploration of techniques for handling longer videos. The increased number of frames in longer videos presents two main challenges: difficulty in locating key information and performing long-range reasoning. Thus, we propose DrVideo, a document-retrieval-based system designed for long video understanding. Our key idea is to convert the long-video understanding problem into a long-document understanding task so as to effectively leverage the power of large language models. Specifically, DrVideo transforms a long video into a text-based long document to initially retrieve key frames and augment the information of these frames, which is used this as the system's starting point. It then employs an agent-based iterative loop to continuously search for missing information, augment relevant data, and provide final predictions in a chain-of-thought manner once sufficient question-related information is gathered. Extensive experiments on long video benchmarks confirm the effectiveness of our method. DrVideo outperforms existing state-of-the-art methods with +3.8 accuracy on EgoSchema benchmark (3 minutes), +17.9 in MovieChat-1K break mode, +38.0 in MovieChat-1K global mode (10 minutes), and +30.2 on the LLama-Vid QA dataset (over 60 minutes).
GeReA: Question-Aware Prompt Captions for Knowledge-based Visual Question Answering
Feb 04, 2024Knowledge-based visual question answering (VQA) requires world knowledge beyond the image for accurate answer. Recently, instead of extra knowledge bases, a large language model (LLM) like GPT-3 is activated as an implicit knowledge engine to jointly acquire and reason the necessary knowledge for answering by converting images into textual information (e.g., captions and answer candidates). However, such conversion may introduce irrelevant information, which causes the LLM to misinterpret images and ignore visual details crucial for accurate knowledge. We argue that multimodal large language model (MLLM) is a better implicit knowledge engine than the LLM for its superior capability of visual understanding. Despite this, how to activate the capacity of MLLM as the implicit knowledge engine has not been explored yet. Therefore, we propose GeReA, a generate-reason framework that prompts a MLLM like InstructBLIP with question relevant vision and language information to generate knowledge-relevant descriptions and reasons those descriptions for knowledge-based VQA. Specifically, the question-relevant image regions and question-specific manual prompts are encoded in the MLLM to generate the knowledge relevant descriptions, referred to as question-aware prompt captions. After that, the question-aware prompt captions, image-question pair, and similar samples are sent into the multi-modal reasoning model to learn a joint knowledge-image-question representation for answer prediction. GeReA unlocks the use of MLLM as the implicit knowledge engine, surpassing all previous state-of-the-art methods on OK-VQA and A-OKVQA datasets, with test accuracies of 66.5% and 63.3% respectively. Our code will be released at https://github.com/Upper9527/GeReA.
Scene-Aware Prompt for Multi-modal Dialogue Understanding and Generation
Jul 05, 2022
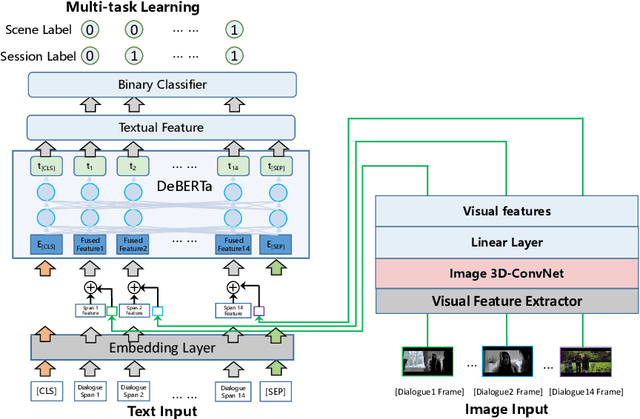
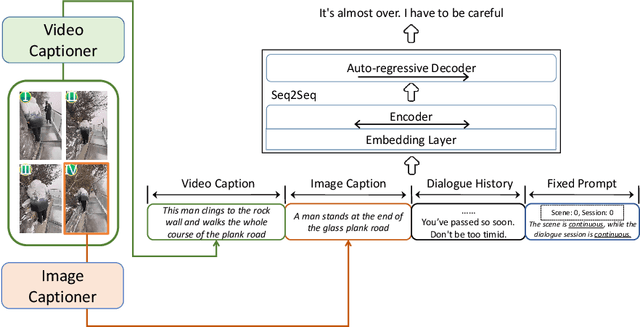
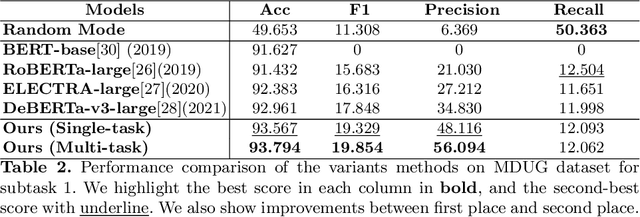
This paper introduces the schemes of Team LingJing's experiments in NLPCC-2022-Shared-Task-4 Multi-modal Dialogue Understanding and Generation (MDUG). The MDUG task can be divided into two phases: multi-modal context understanding and response generation. To fully leverage the visual information for both scene understanding and dialogue generation, we propose the scene-aware prompt for the MDUG task. Specifically, we utilize the multi-tasking strategy for jointly modelling the scene- and session- multi-modal understanding. The visual captions are adopted to aware the scene information, while the fixed-type templated prompt based on the scene- and session-aware labels are used to further improve the dialogue generation performance. Extensive experimental results show that the proposed method has achieved state-of-the-art (SOTA) performance compared with other competitive methods, where we rank the 1-st in all three subtasks in this MDUG competition.
Hybrid Mutimodal Fusion for Dimensional Emotion Recognition
Oct 16, 2021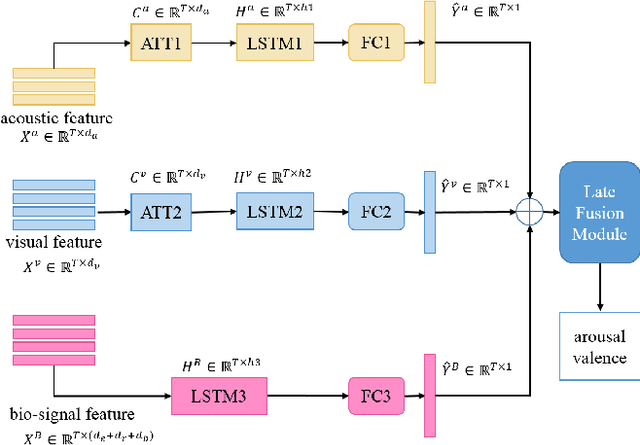
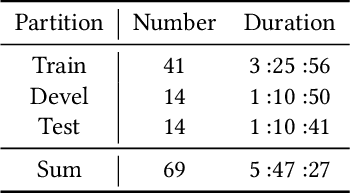
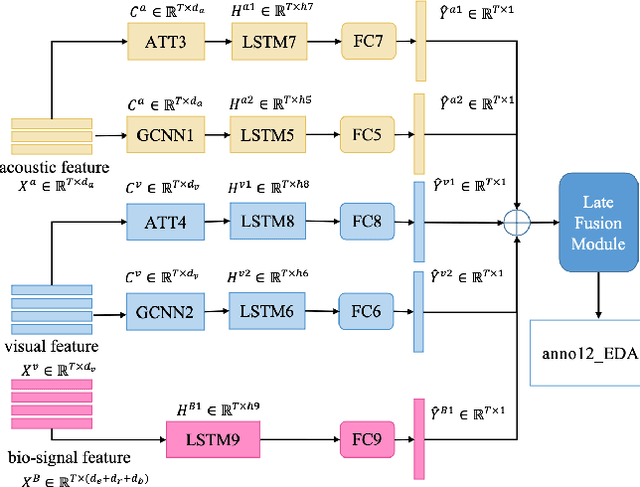
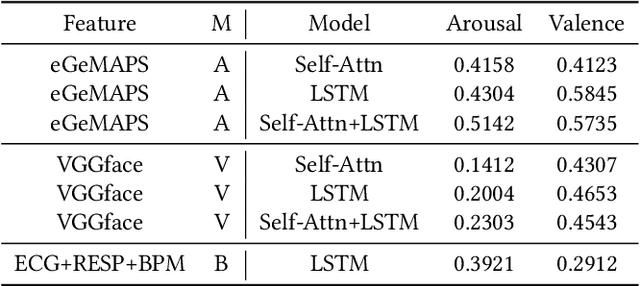
In this paper, we extensively present our solutions for the MuSe-Stress sub-challenge and the MuSe-Physio sub-challenge of Multimodal Sentiment Challenge (MuSe) 2021. The goal of MuSe-Stress sub-challenge is to predict the level of emotional arousal and valence in a time-continuous manner from audio-visual recordings and the goal of MuSe-Physio sub-challenge is to predict the level of psycho-physiological arousal from a) human annotations fused with b) galvanic skin response (also known as Electrodermal Activity (EDA)) signals from the stressed people. The Ulm-TSST dataset which is a novel subset of the audio-visual textual Ulm-Trier Social Stress dataset that features German speakers in a Trier Social Stress Test (TSST) induced stress situation is used in both sub-challenges. For the MuSe-Stress sub-challenge, we highlight our solutions in three aspects: 1) the audio-visual features and the bio-signal features are used for emotional state recognition. 2) the Long Short-Term Memory (LSTM) with the self-attention mechanism is utilized to capture complex temporal dependencies within the feature sequences. 3) the late fusion strategy is adopted to further boost the model's recognition performance by exploiting complementary information scattered across multimodal sequences. Our proposed model achieves CCC of 0.6159 and 0.4609 for valence and arousal respectively on the test set, which both rank in the top 3. For the MuSe-Physio sub-challenge, we first extract the audio-visual features and the bio-signal features from multiple modalities. Then, the LSTM module with the self-attention mechanism, and the Gated Convolutional Neural Networks (GCNN) as well as the LSTM network are utilized for modeling the complex temporal dependencies in the sequence. Finally, the late fusion strategy is used. Our proposed method also achieves CCC of 0.5412 on the test set, which ranks in the top 3.