 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSN: A Memory-based Sparse Activation Scaling Framework for Large-scale Industrial Recommendation
Feb 07, 2026Scaling deep learning recommendation models is an effective way to improve model expressiveness. Existing approaches often incur substantial computational overhead, making them difficult to deploy in large-scale industrial systems under strict latency constraints. Recent sparse activation scaling methods, such as Sparse Mixture-of-Experts, reduce computation by activating only a subset of parameters, but still suffer from high memory access costs and limited personalization capacity due to the large size and small number of experts. To address these challenges, we propose MSN, a memory-based sparse activation scaling framework for recommendation models. MSN dynamically retrieves personalized representations from a large parameterized memory and integrates them into downstream feature interaction modules via a memory gating mechanism, enabling fine-grained personalization with low computational overhead. To enable further expansion of the memory capacity while keeping both computational and memory access costs under control, MSN adopts a Product-Key Memory (PKM) mechanism, which factorizes the memory retrieval complexity from linear time to sub-linear complexity. In addition, normalization and over-parameterization techniques are introduced to maintain balanced memory utilization and prevent memory retrieval collapse. We further design customized Sparse-Gather operator and adopt the AirTopK operator to improve training and inference efficiency in industrial settings. Extensive experiments demonstrate that MSN consistently improves recommendation performance while maintaining high efficiency. Moreover, MSN has been successfully deployed in the Douyin Search Ranking System, achieving significant gains over deployed state-of-the-art models in both offline evaluation metrics and large-scale online A/B test.
MDL: A Unified Multi-Distribution Learner in Large-scale Industrial Recommendation through Tokenization
Feb 07, 2026Industrial recommender systems increasingly adopt multi-scenario learning (MSL) and multi-task learning (MTL) to handle diverse user interactions and contexts, but existing approaches suffer from two critical drawbacks: (1) underutilization of large-scale model parameters due to limited interaction with complex feature modules, and (2) difficulty in jointly modeling scenario and task information in a unified framework. To address these challenges, we propose a unified \textbf{M}ulti-\textbf{D}istribution \textbf{L}earning (MDL) framework, inspired by the "prompting" paradigm in large language models (LLMs). MDL treats scenario and task information as specialized tokens rather than auxiliary inputs or gating signals. Specifically, we introduce a unified information tokenization module that transforms features, scenarios, and tasks into a unified tokenized format. To facilitate deep interaction, we design three synergistic mechanisms: (1) feature token self-attention for rich feature interactions, (2) domain-feature attention for scenario/task-adaptive feature activation, and (3) domain-fused aggregation for joint distribution prediction. By stacking these interactions, MDL enables scenario and task information to "prompt" and activate the model's vast parameter space in a bottom-up, layer-wise manner. Extensive experiments on real-world industrial datasets demonstrate that MDL significantly outperforms state-of-the-art MSL and MTL baselines. Online A/B testing on Douyin Search platform over one month yields +0.0626\% improvement in LT30 and -0.3267\% reduction in change query rate. MDL has been fully deployed in production, serving hundreds of millions of users daily.
HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction
Jan 19, 2026Industrial large-scale recommendation models (LRMs) face the challenge of jointly modeling long-range user behavior sequences and heterogeneous non-sequential features under strict efficiency constraints. However, most existing architectures employ a decoupled pipeline: long sequences are first compressed with a query-token based sequence compressor like LONGER, followed by fusion with dense features through token-mixing modules like RankMixer, which thereby limits both the representation capacity and the interaction flexibility. This paper presents HyFormer, a unified hybrid transformer architecture that tightly integrates long-sequence modeling and feature interaction into a single backbone. From the perspective of sequence modeling, we revisit and redesign query tokens in LRMs, and frame the LRM modeling task as an alternating optimization process that integrates two core components: Query Decoding which expands non-sequential features into Global Tokens and performs long sequence decoding over layer-wise key-value representations of long behavioral sequences; and Query Boosting which enhances cross-query and cross-sequence heterogeneous interactions via efficient token mixing. The two complementary mechanisms are performed iteratively to refine semantic representations across layers. Extensive experiments on billion-scale industrial datasets demonstrate that HyFormer consistently outperforms strong LONGER and RankMixer baselines under comparable parameter and FLOPs budgets, while exhibiting superior scaling behavior with increasing parameters and FLOPs. Large-scale online A/B tests in high-traffic production systems further validate its effectiveness, showing significant gains over deployed state-of-the-art models. These results highlight the practicality and scalability of HyFormer as a unified modeling framework for industrial LRMs.
LEMUR: Large scale End-to-end MUltimodal Recommendation
Nov 17, 2025Traditional ID-based recommender systems often struggle with cold-start and generalization challenges. Multimodal recommendation systems, which leverage textual and visual data, offer a promising solution to mitigate these issues. However, existing industrial approaches typically adopt a two-stage training paradigm: first pretraining a multimodal model, then applying its frozen representations to train the recommendation model. This decoupled framework suffers from misalignment between multimodal learning and recommendation objectives, as well as an inability to adapt dynamically to new data. To address these limitations, we propose LEMUR, the first large-scale multimodal recommender system trained end-to-end from raw data. By jointly optimizing both the multimodal and recommendation components, LEMUR ensures tighter alignment with downstream objectives while enabling real-time parameter updates. Constructing multimodal sequential representations from user history often entails prohibitively high computational costs. To alleviate this bottleneck, we propose a novel memory bank mechanism that incrementally accumulates historical multimodal representations throughout the training process. After one month of deployment in Douyin Search, LEMUR has led to a 0.843% reduction in query change rate decay and a 0.81% improvement in QAUC. Additionally, LEMUR has shown significant gains across key offline metrics for Douyin Advertisement. Our results validate the superiority of end-to-end multimodal recommendation in real-world industrial scenarios.
Prompt Tuning for Item Cold-start Recommendation
Dec 24, 2024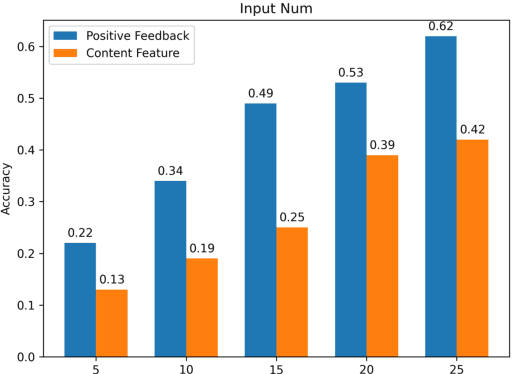
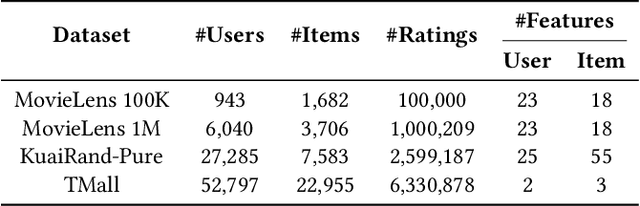
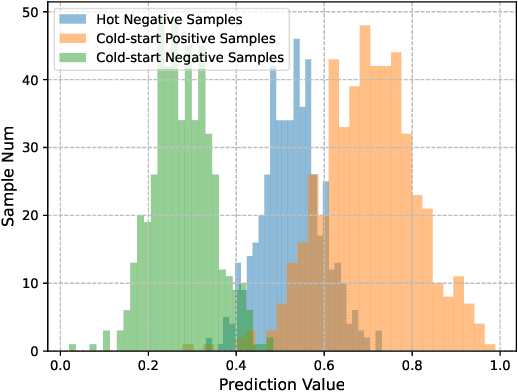
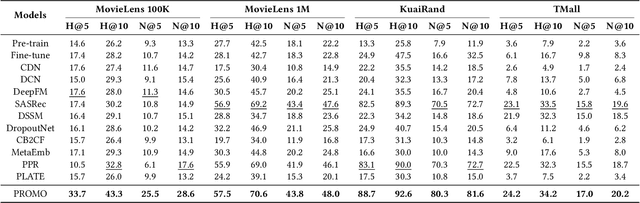
The item cold-start problem is crucial for online recommender systems, as the success of the cold-start phase determines whether items can transition into popular ones. Prompt learning, a powerful technique used in natural language processing (NLP) to address zero- or few-shot problems, has been adapted for recommender systems to tackle similar challenges. However, existing methods typically rely on content-based properties or text descriptions for prompting, which we argue may be suboptimal for cold-start recommendations due to 1) semantic gaps with recommender tasks, 2) model bias caused by warm-up items contribute most of the positive feedback to the model, which is the core of the cold-start problem that hinders the recommender quality on cold-start items. We propose to leverage high-value positive feedback, termed pinnacle feedback as prompt information, to simultaneously resolve the above two problems. We experimentally prove that compared to the content description proposed in existing works, the positive feedback is more suitable to serve as prompt information by bridging the semantic gaps. Besides, we propose item-wise personalized prompt networks to encode pinnaclce feedback to relieve the model bias by the positive feedback dominance problem. Extensive experiments on four real-world datasets demonstrate the superiority of our model over state-of-the-art methods. Moreover, PROMO has been successfully deployed on a popular short-video sharing platform, a billion-user scale commercial short-video application, achieving remarkable performance gains across various commercial metrics within cold-start scenarios
An End-to-End Framework for Marketing Effectiveness Optimization under Budget Constraint
Feb 09, 2023



Online platforms often incentivize consumers to improve user engagement and platform revenue. Since different consumers might respond differently to incentives, individual-level budget allocation is an essential task in marketing campaigns. Recent advances in this field often address the budget allocation problem using a two-stage paradigm: the first stage estimates the individual-level treatment effects using causal inference algorithms, and the second stage invokes integer programming techniques to find the optimal budget allocation solution. Since the objectives of these two stages might not be perfectly aligned, such a two-stage paradigm could hurt the overall marketing effectiveness. In this paper, we propose a novel end-to-end framework to directly optimize the business goal under budget constraints. Our core idea is to construct a regularizer to represent the marketing goal and optimize it efficiently using gradient estimation techniques. As such, the obtained models can learn to maximize the marketing goal directly and precisely. We extensively evaluate our proposed method in both offline and online experiments, and experimental results demonstrate that our method outperforms current state-of-the-art methods. Our proposed method is currently deployed to allocate marketing budgets for hundreds of millions of users on a short video platform and achieves significant business goal improvements. Our code will be publicly available.