 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Evidence Highlighting for Frozen LLMs
Apr 24, 2026Large Language Models (LLMs) can reason well, yet often miss decisive evidence when it is buried in long, noisy contexts. We introduce HiLight, an Evidence Emphasis framework that decouples evidence selection from reasoning for frozen LLM solvers. HiLight avoids compressing or rewriting the input, which can discard or distort evidence, by training a lightweight Emphasis Actor to insert minimal highlight tags around pivotal spans in the unaltered context. A frozen Solver then performs downstream reasoning on the emphasized input. We cast highlighting as a weakly supervised decision-making problem and optimize the Actor with reinforcement learning using only the Solver's task reward, requiring no evidence labels and no access to or modification of the Solver. Across sequential recommendation and long-context question answering, HiLight consistently improves performance over strong prompt-based and automated prompt-optimization baselines. The learned emphasis policy transfers zero-shot to both smaller and larger unseen Solver families, including an API-based Solver, suggesting that the Actor captures genuine, reusable evidence structure rather than overfitting to a single backbone.
Generative Reasoning Re-ranker
Feb 08, 2026Recent studies increasingly explore Large Language Models (LLMs) as a new paradigm for recommendation systems due to their scalability and world knowledge. However, existing work has three key limitations: (1) most efforts focus on retrieval and ranking, while the reranking phase, critical for refining final recommendations, is largely overlooked; (2) LLMs are typically used in zero-shot or supervised fine-tuning settings, leaving their reasoning abilities, especially those enhanced through reinforcement learning (RL) and high-quality reasoning data, underexploited; (3) items are commonly represented by non-semantic IDs, creating major scalability challenges in industrial systems with billions of identifiers. To address these gaps, we propose the Generative Reasoning Reranker (GR2), an end-to-end framework with a three-stage training pipeline tailored for reranking. First, a pretrained LLM is mid-trained on semantic IDs encoded from non-semantic IDs via a tokenizer achieving $\ge$99% uniqueness. Next, a stronger larger-scale LLM generates high-quality reasoning traces through carefully designed prompting and rejection sampling, which are used for supervised fine-tuning to impart foundational reasoning skills. Finally, we apply Decoupled Clip and Dynamic sAmpling Policy Optimization (DAPO), enabling scalable RL supervision with verifiable rewards designed specifically for reranking. Experiments on two real-world datasets demonstrate GR2's effectiveness: it surpasses the state-of-the-art OneRec-Think by 2.4% in Recall@5 and 1.3% in NDCG@5. Ablations confirm that advanced reasoning traces yield substantial gains across metrics. We further find that RL reward design is crucial in reranking: LLMs tend to exploit reward hacking by preserving item order, motivating conditional verifiable rewards to mitigate this behavior and optimize reranking performance.
Order-Preserving Abstractive Summarization for Spoken Content Based on Connectionist Temporal Classification
Nov 16, 2017

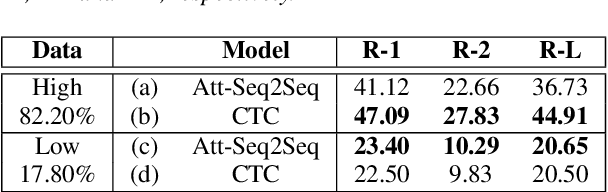
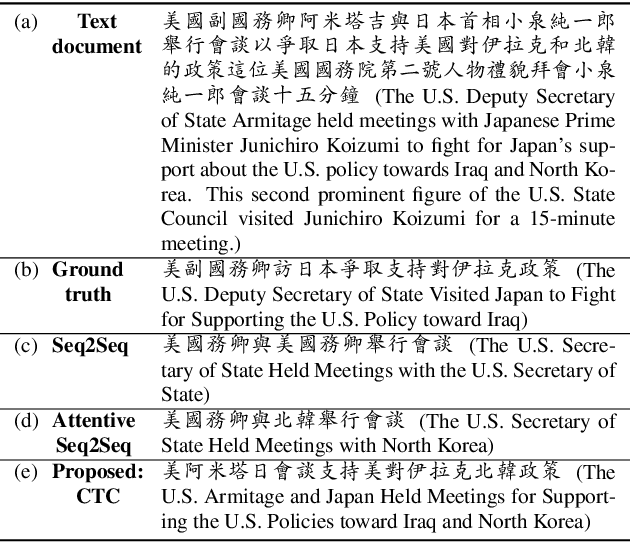
Connectionist temporal classification (CTC) is a powerful approach for sequence-to-sequence learning, and has been popularly used in speech recognition. The central ideas of CTC include adding a label "blank" during training. With this mechanism, CTC eliminates the need of segment alignment, and hence has been applied to various sequence-to-sequence learning problems. In this work, we applied CTC to abstractive summarization for spoken content. The "blank" in this case implies the corresponding input data are less important or noisy; thus it can be ignored. This approach was shown to outperform the existing methods in term of ROUGE scores over Chinese Gigaword and MATBN corpora. This approach also has the nice property that the ordering of words or characters in the input documents can be better preserved in the generated summaries.