 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Speech Synthesis without Vector Quantization
Jul 11, 2024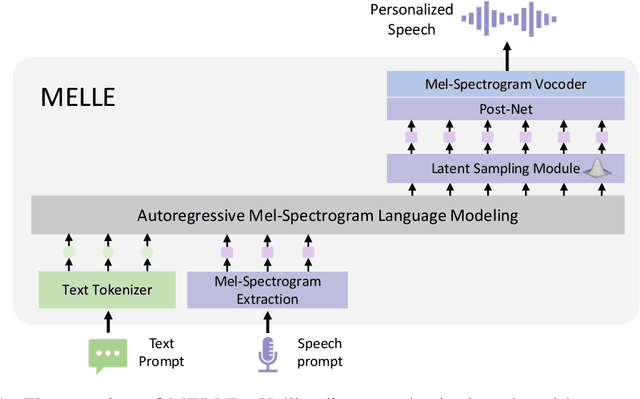



We present MELLE, a novel continuous-valued tokens based language modeling approach for text to speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which are originally designed for audio compression and sacrifice fidelity compared to mel-spectrograms. Specifically, (i) instead of cross-entropy loss, we apply regression loss with a proposed spectrogram flux loss function to model the probability distribution of the continuous-valued tokens. (ii) we have incorporated variational inference into MELLE to facilitate sampling mechanisms, thereby enhancing the output diversity and model robustness. Experiments demonstrate that, compared to the two-stage codec language models VALL-E and its variants, the single-stage MELLE mitigates robustness issues by avoiding the inherent flaws of sampling discrete codes, achieves superior performance across multiple metrics, and, most importantly, offers a more streamlined paradigm. See https://aka.ms/melle for demos of our work.
VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment
Jun 12, 2024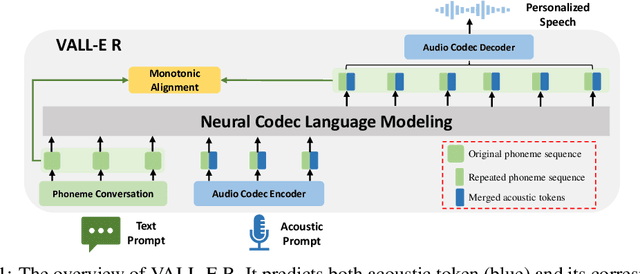

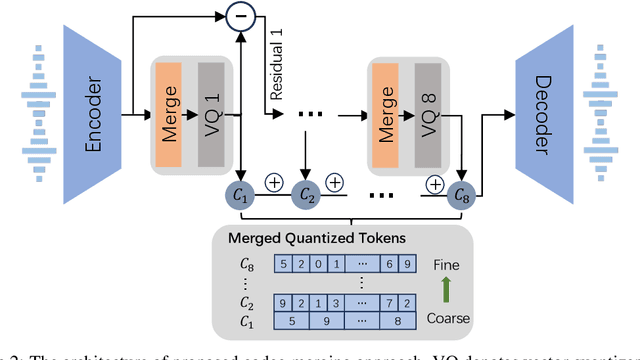

With the help of discrete neural audio codecs, large language models (LLM) have increasingly been recognized as a promising methodology for zero-shot Text-to-Speech (TTS) synthesis. However, sampling based decoding strategies bring astonishing diversity to generation, but also pose robustness issues such as typos, omissions and repetition. In addition, the high sampling rate of audio also brings huge computational overhead to the inference process of autoregression. To address these issues, we propose VALL-E R, a robust and efficient zero-shot TTS system, building upon the foundation of VALL-E. Specifically, we introduce a phoneme monotonic alignment strategy to strengthen the connection between phonemes and acoustic sequence, ensuring a more precise alignment by constraining the acoustic tokens to match their associated phonemes. Furthermore, we employ a codec-merging approach to downsample the discrete codes in shallow quantization layer, thereby accelerating the decoding speed while preserving the high quality of speech output. Benefiting from these strategies, VALL-E R obtains controllablity over phonemes and demonstrates its strong robustness by approaching the WER of ground truth. In addition, it requires fewer autoregressive steps, with over 60% time reduction during inference. This research has the potential to be applied to meaningful projects, including the creation of speech for those affected by aphasia. Audio samples will be available at: https://aka.ms/valler.
VALL-E 2: Neural Codec Language Models are Human Parity Zero-Shot Text to Speech Synthesizers
Jun 08, 2024



This paper introduces VALL-E 2, the latest advancement in neural codec language models that marks a milestone in zero-shot text-to-speech synthesis (TTS), achieving human parity for the first time. Based on its predecessor, VALL-E, the new iteration introduces two significant enhancements: Repetition Aware Sampling refines the original nucleus sampling process by accounting for token repetition in the decoding history. It not only stabilizes the decoding but also circumvents the infinite loop issue. Grouped Code Modeling organizes codec codes into groups to effectively shorten the sequence length, which not only boosts inference speed but also addresses the challenges of long sequence modeling. Our experiments on the LibriSpeech and VCTK datasets show that VALL-E 2 surpasses previous systems in speech robustness, naturalness, and speaker similarity. It is the first of its kind to reach human parity on these benchmarks. Moreover, VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases. The advantages of this work could contribute to valuable endeavors, such as generating speech for individuals with aphasia or people with amyotrophic lateral sclerosis. Demos of VALL-E 2 will be posted to https://aka.ms/valle2.
TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
May 28, 2024There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Apr 10, 2024



Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis
Apr 06, 2024



We present RALL-E, a robust language modeling method for text-to-speech (TTS) synthesis. While previous work based on large language models (LLMs) shows impressive performance on zero-shot TTS, such methods often suffer from poor robustness, such as unstable prosody (weird pitch and rhythm/duration) and a high word error rate (WER), due to the autoregressive prediction style of language models. The core idea behind RALL-E is chain-of-thought (CoT) prompting, which decomposes the task into simpler steps to enhance the robustness of LLM-based TTS. To accomplish this idea, RALL-E first predicts prosody features (pitch and duration) of the input text and uses them as intermediate conditions to predict speech tokens in a CoT style. Second, RALL-E utilizes the predicted duration prompt to guide the computing of self-attention weights in Transformer to enforce the model to focus on the corresponding phonemes and prosody features when predicting speech tokens. Results of comprehensive objective and subjective evaluations demonstrate that, compared to a powerful baseline method VALL-E, RALL-E significantly improves the WER of zero-shot TTS from $6.3\%$ (without reranking) and $2.1\%$ (with reranking) to $2.8\%$ and $1.0\%$, respectively. Furthermore, we demonstrate that RALL-E correctly synthesizes sentences that are hard for VALL-E and reduces the error rate from $68\%$ to $4\%$.
WavLLM: Towards Robust and Adaptive Speech Large Language Model
Mar 31, 2024The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at \url{aka.ms/wavllm}.
Advanced Long-Content Speech Recognition With Factorized Neural Transducer
Mar 20, 2024



In this paper, we propose two novel approaches, which integrate long-content information into the factorized neural transducer (FNT) based architecture in both non-streaming (referred to as LongFNT ) and streaming (referred to as SLongFNT ) scenarios. We first investigate whether long-content transcriptions can improve the vanilla conformer transducer (C-T) models. Our experiments indicate that the vanilla C-T models do not exhibit improved performance when utilizing long-content transcriptions, possibly due to the predictor network of C-T models not functioning as a pure language model. Instead, FNT shows its potential in utilizing long-content information, where we propose the LongFNT model and explore the impact of long-content information in both text (LongFNT-Text) and speech (LongFNT-Speech). The proposed LongFNT-Text and LongFNT-Speech models further complement each other to achieve better performance, with transcription history proving more valuable to the model. The effectiveness of our LongFNT approach is evaluated on LibriSpeech and GigaSpeech corpora, and obtains relative 19% and 12% word error rate reduction, respectively. Furthermore, we extend the LongFNT model to the streaming scenario, which is named SLongFNT , consisting of SLongFNT-Text and SLongFNT-Speech approaches to utilize long-content text and speech information. Experiments show that the proposed SLongFNT model achieves relative 26% and 17% WER reduction on LibriSpeech and GigaSpeech respectively while keeping a good latency, compared to the FNT baseline. Overall, our proposed LongFNT and SLongFNT highlight the significance of considering long-content speech and transcription knowledge for improving both non-streaming and streaming speech recognition systems.
* Accepted by TASLP 2024
Boosting Large Language Model for Speech Synthesis: An Empirical Study
Dec 30, 2023Large language models (LLMs) have made significant advancements in natural language processing and are concurrently extending the language ability to other modalities, such as speech and vision. Nevertheless, most of the previous work focuses on prompting LLMs with perception abilities like auditory comprehension, and the effective approach for augmenting LLMs with speech synthesis capabilities remains ambiguous. In this paper, we conduct a comprehensive empirical exploration of boosting LLMs with the ability to generate speech, by combining pre-trained LLM LLaMA/OPT and text-to-speech synthesis model VALL-E. We compare three integration methods between LLMs and speech synthesis models, including directly fine-tuned LLMs, superposed layers of LLMs and VALL-E, and coupled LLMs and VALL-E using LLMs as a powerful text encoder. Experimental results show that, using LoRA method to fine-tune LLMs directly to boost the speech synthesis capability does not work well, and superposed LLMs and VALL-E can improve the quality of generated speech both in speaker similarity and word error rate (WER). Among these three methods, coupled methods leveraging LLMs as the text encoder can achieve the best performance, making it outperform original speech synthesis models with a consistently better speaker similarity and a significant (10.9%) WER reduction.
COSMIC: Data Efficient Instruction-tuning For Speech In-Context Learning
Nov 03, 2023



We present a data and cost efficient way of incorporating the speech modality into a large language model (LLM). The resulting multi-modal LLM is a COntextual Speech Model with Instruction-following/in-context-learning Capabilities - COSMIC. Speech comprehension test question-answer (SQA) pairs are generated using GPT-3.5 based on the speech transcriptions as a part of the supervision for the instruction tuning. With fewer than 20M trainable parameters and as little as 450 hours of English speech data for SQA generation, COSMIC exhibits emergent instruction-following and in-context learning capabilities in speech-to-text tasks. The model is able to follow the given text instructions to generate text response even on the unseen EN$\to$X speech-to-text translation (S2TT) task with zero-shot setting. We evaluate the model's in-context learning via various tasks such as EN$\to$X S2TT and few-shot domain adaptation. And instruction-following capabilities are evaluated through a contextual biasing benchmark. Our results demonstrate the efficacy of the proposed low cost recipe for building a speech LLM and that with the new instruction-tuning data.