 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOV-PARTS: Towards Open-Vocabulary Part Segmentation
Oct 08, 2023



Segmenting and recognizing diverse object parts is a crucial ability in applications spanning various computer vision and robotic tasks. While significant progress has been made in object-level Open-Vocabulary Semantic Segmentation (OVSS), i.e., segmenting objects with arbitrary text, the corresponding part-level research poses additional challenges. Firstly, part segmentation inherently involves intricate boundaries, while limited annotated data compounds the challenge. Secondly, part segmentation introduces an open granularity challenge due to the diverse and often ambiguous definitions of parts in the open world. Furthermore, the large-scale vision and language models, which play a key role in the open vocabulary setting, struggle to recognize parts as effectively as objects. To comprehensively investigate and tackle these challenges, we propose an Open-Vocabulary Part Segmentation (OV-PARTS) benchmark. OV-PARTS includes refined versions of two publicly available datasets: Pascal-Part-116 and ADE20K-Part-234. And it covers three specific tasks: Generalized Zero-Shot Part Segmentation, Cross-Dataset Part Segmentation, and Few-Shot Part Segmentation, providing insights into analogical reasoning, open granularity and few-shot adapting abilities of models. Moreover, we analyze and adapt two prevailing paradigms of existing object-level OVSS methods for OV-PARTS. Extensive experimental analysis is conducted to inspire future research in leveraging foundational models for OV-PARTS. The code and dataset are available at https://github.com/OpenRobotLab/OV_PARTS.
Improving Knowledge Distillation via Regularizing Feature Norm and Direction
May 26, 2023



Knowledge distillation (KD) exploits a large well-trained model (i.e., teacher) to train a small student model on the same dataset for the same task. Treating teacher features as knowledge, prevailing methods of knowledge distillation train student by aligning its features with the teacher's, e.g., by minimizing the KL-divergence between their logits or L2 distance between their intermediate features. While it is natural to believe that better alignment of student features to the teacher better distills teacher knowledge, simply forcing this alignment does not directly contribute to the student's performance, e.g., classification accuracy. In this work, we propose to align student features with class-mean of teacher features, where class-mean naturally serves as a strong classifier. To this end, we explore baseline techniques such as adopting the cosine distance based loss to encourage the similarity between student features and their corresponding class-means of the teacher. Moreover, we train the student to produce large-norm features, inspired by other lines of work (e.g., model pruning and domain adaptation), which find the large-norm features to be more significant. Finally, we propose a rather simple loss term (dubbed ND loss) to simultaneously (1) encourage student to produce large-\emph{norm} features, and (2) align the \emph{direction} of student features and teacher class-means. Experiments on standard benchmarks demonstrate that our explored techniques help existing KD methods achieve better performance, i.e., higher classification accuracy on ImageNet and CIFAR100 datasets, and higher detection precision on COCO dataset. Importantly, our proposed ND loss helps the most, leading to the state-of-the-art performance on these benchmarks. The source code is available at \url{https://github.com/WangYZ1608/Knowledge-Distillation-via-ND}.
Far3Det: Towards Far-Field 3D Detection
Nov 25, 2022



We focus on the task of far-field 3D detection (Far3Det) of objects beyond a certain distance from an observer, e.g., $>$50m. Far3Det is particularly important for autonomous vehicles (AVs) operating at highway speeds, which require detections of far-field obstacles to ensure sufficient braking distances. However, contemporary AV benchmarks such as nuScenes underemphasize this problem because they evaluate performance only up to a certain distance (50m). One reason is that obtaining far-field 3D annotations is difficult, particularly for lidar sensors that produce very few point returns for far-away objects. Indeed, we find that almost 50% of far-field objects (beyond 50m) contain zero lidar points. Secondly, current metrics for 3D detection employ a "one-size-fits-all" philosophy, using the same tolerance thresholds for near and far objects, inconsistent with tolerances for both human vision and stereo disparities. Both factors lead to an incomplete analysis of the Far3Det task. For example, while conventional wisdom tells us that high-resolution RGB sensors should be vital for 3D detection of far-away objects, lidar-based methods still rank higher compared to RGB counterparts on the current benchmark leaderboards. As a first step towards a Far3Det benchmark, we develop a method to find well-annotated scenes from the nuScenes dataset and derive a well-annotated far-field validation set. We also propose a Far3Det evaluation protocol and explore various 3D detection methods for Far3Det. Our result convincingly justifies the long-held conventional wisdom that high-resolution RGB improves 3D detection in the far-field. We further propose a simple yet effective method that fuses detections from RGB and lidar detectors based on non-maximum suppression, which remarkably outperforms state-of-the-art 3D detectors in the far-field.
Towards Long-Tailed 3D Detection
Nov 16, 2022Contemporary autonomous vehicle (AV) benchmarks have advanced techniques for training 3D detectors, particularly on large-scale lidar data. Surprisingly, although semantic class labels naturally follow a long-tailed distribution, contemporary benchmarks focus on only a few common classes (e.g., pedestrian and car) and neglect many rare classes in-the-tail (e.g., debris and stroller). However, AVs must still detect rare classes to ensure safe operation. Moreover, semantic classes are often organized within a hierarchy, e.g., tail classes such as child and construction-worker are arguably subclasses of pedestrian. However, such hierarchical relationships are often ignored, which may lead to misleading estimates of performance and missed opportunities for algorithmic innovation. We address these challenges by formally studying the problem of Long-Tailed 3D Detection (LT3D), which evaluates on all classes, including those in-the-tail. We evaluate and innovate upon popular 3D detection codebases, such as CenterPoint and PointPillars, adapting them for LT3D. We develop hierarchical losses that promote feature sharing across common-vs-rare classes, as well as improved detection metrics that award partial credit to "reasonable" mistakes respecting the hierarchy (e.g., mistaking a child for an adult). Finally, we point out that fine-grained tail class accuracy is particularly improved via multimodal fusion of RGB images with LiDAR; simply put, small fine-grained classes are challenging to identify from sparse (lidar) geometry alone, suggesting that multimodal cues are crucial to long-tailed 3D detection. Our modifications improve accuracy by 5% AP on average for all classes, and dramatically improve AP for rare classes (e.g., stroller AP improves from 3.6 to 31.6)!
Learning with an Evolving Class Ontology
Oct 12, 2022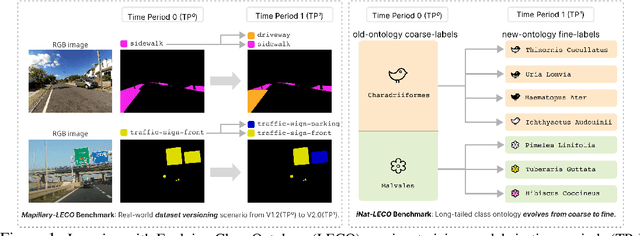
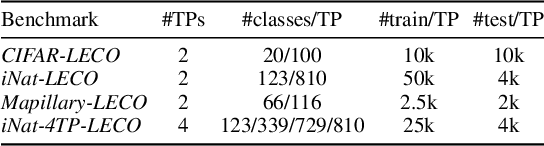
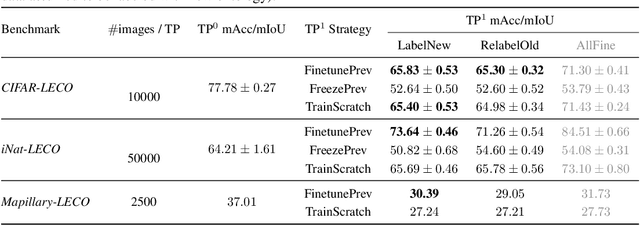
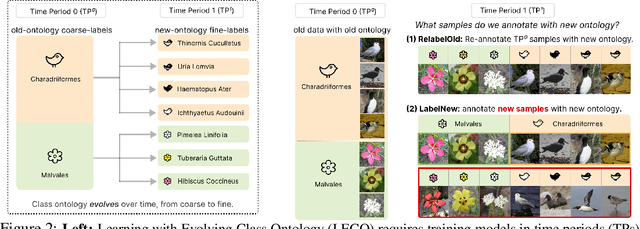
Lifelong learners must recognize concept vocabularies that evolve over time. A common yet underexplored scenario is learning with class labels over time that refine/expand old classes. For example, humans learn to recognize ${\tt dog}$ before dog breeds. In practical settings, dataset $\textit{versioning}$ often introduces refinement to ontologies, such as autonomous vehicle benchmarks that refine a previous ${\tt vehicle}$ class into ${\tt school-bus}$ as autonomous operations expand to new cities. This paper formalizes a protocol for studying the problem of $\textit{Learning with Evolving Class Ontology}$ (LECO). LECO requires learning classifiers in distinct time periods (TPs); each TP introduces a new ontology of "fine" labels that refines old ontologies of "coarse" labels (e.g., dog breeds that refine the previous ${\tt dog}$). LECO explores such questions as whether to annotate new data or relabel the old, how to leverage coarse labels, and whether to finetune the previous TP's model or train from scratch. To answer these questions, we leverage insights from related problems such as class-incremental learning. We validate them under the LECO protocol through the lens of image classification (CIFAR and iNaturalist) and semantic segmentation (Mapillary). Our experiments lead to surprising conclusions; while the current status quo is to relabel existing datasets with new ontologies (such as COCO-to-LVIS or Mapillary1.2-to-2.0), LECO demonstrates that a far better strategy is to annotate $\textit{new}$ data with the new ontology. However, this produces an aggregate dataset with inconsistent old-vs-new labels, complicating learning. To address this challenge, we adopt methods from semi-supervised and partial-label learning. Such strategies can surprisingly be made near-optimal, approaching an "oracle" that learns on the aggregate dataset exhaustively labeled with the newest ontology.
ShoeRinsics: Shoeprint Prediction for Forensics with Intrinsic Decomposition
May 04, 2022


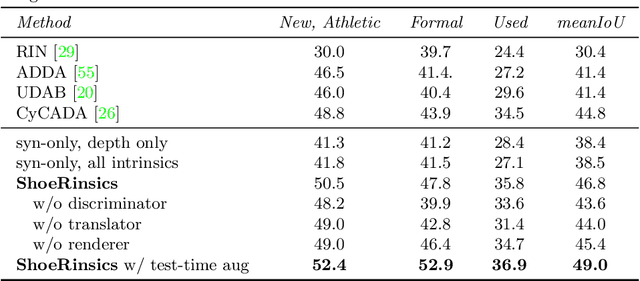
Shoe tread impressions are one of the most common types of evidence left at crime scenes. However, the utility of such evidence is limited by the lack of databases of footwear impression patterns that cover the huge and growing number of distinct shoe models. We propose to address this gap by leveraging shoe tread photographs collected by online retailers. The core challenge is to predict the impression pattern from the shoe photograph since ground-truth impressions or 3D shapes of tread patterns are not available. We develop a model that performs intrinsic image decomposition (predicting depth, normal, albedo, and lighting) from a single tread photo. Our approach, which we term ShoeRinsics, combines domain adaptation and re-rendering losses in order to leverage a mix of fully supervised synthetic data and unsupervised retail image data. To validate model performance, we also collected a set of paired shoe-sole images and corresponding prints, and define a benchmarking protocol to quantify the accuracy of predicted impressions. On this benchmark, ShoeRinsics outperforms existing methods for depth prediction and synthetic-to-real domain adaptation.
Long-Tailed Recognition via Weight Balancing
Mar 27, 2022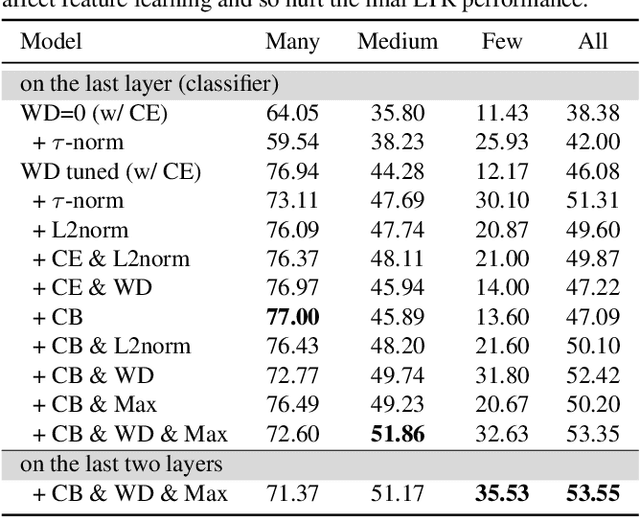
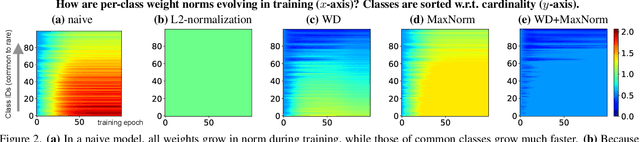
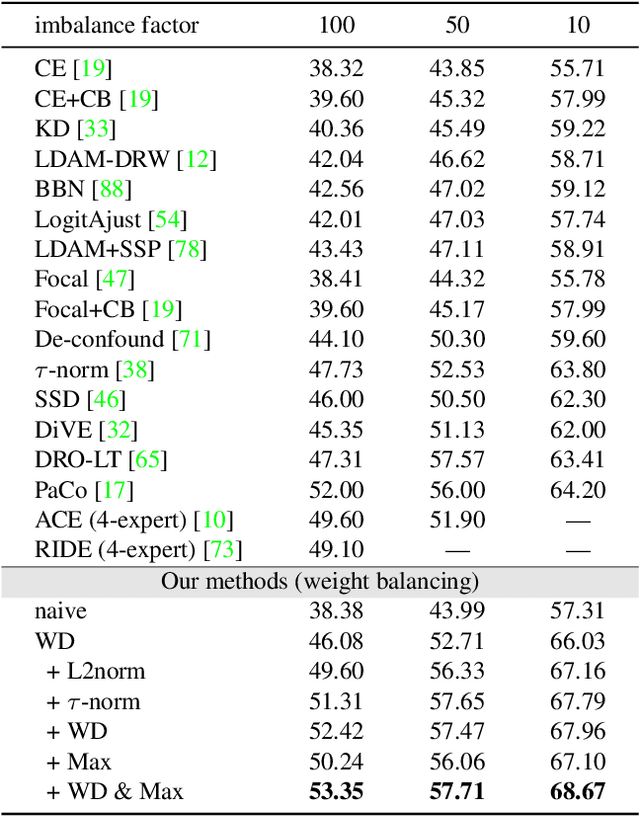
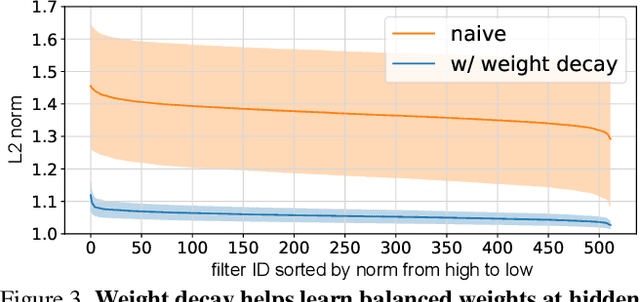
In the real open world, data tends to follow long-tailed class distributions, motivating the well-studied long-tailed recognition (LTR) problem. Naive training produces models that are biased toward common classes in terms of higher accuracy. The key to addressing LTR is to balance various aspects including data distribution, training losses, and gradients in learning. We explore an orthogonal direction, weight balancing, motivated by the empirical observation that the naively trained classifier has "artificially" larger weights in norm for common classes (because there exists abundant data to train them, unlike the rare classes). We investigate three techniques to balance weights, L2-normalization, weight decay, and MaxNorm. We first point out that L2-normalization "perfectly" balances per-class weights to be unit norm, but such a hard constraint might prevent classes from learning better classifiers. In contrast, weight decay penalizes larger weights more heavily and so learns small balanced weights; the MaxNorm constraint encourages growing small weights within a norm ball but caps all the weights by the radius. Our extensive study shows that both help learn balanced weights and greatly improve the LTR accuracy. Surprisingly, weight decay, although underexplored in LTR, significantly improves over prior work. Therefore, we adopt a two-stage training paradigm and propose a simple approach to LTR: (1) learning features using the cross-entropy loss by tuning weight decay, and (2) learning classifiers using class-balanced loss by tuning weight decay and MaxNorm. Our approach achieves the state-of-the-art accuracy on five standard benchmarks, serving as a future baseline for long-tailed recognition.
OpenGAN: Open-Set Recognition via Open Data Generation
Apr 09, 2021


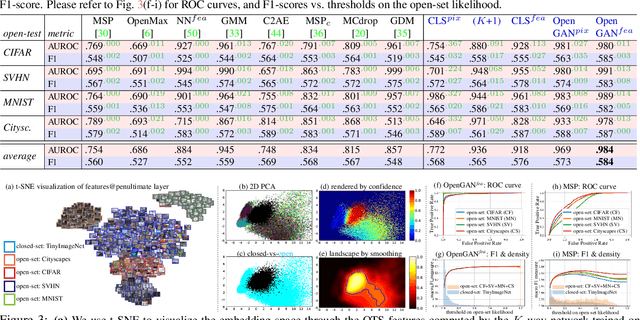
Real-world machine learning systems need to analyze novel testing data that differs from the training data. In K-way classification, this is crisply formulated as open-set recognition, core to which is the ability to discriminate open-set data outside the K closed-set classes. Two conceptually elegant ideas for open-set discrimination are: 1) discriminatively learning an open-vs-closed binary discriminator by exploiting some outlier data as the open-set, and 2) unsupervised learning the closed-set data distribution with a GAN and using its discriminator as the open-set likelihood function. However, the former generalizes poorly to diverse open test data due to overfitting to the training outliers, which unlikely exhaustively span the open-world. The latter does not work well, presumably due to the instable training of GANs. Motivated by the above, we propose OpenGAN, which addresses the limitation of each approach by combining them with several technical insights. First, we show that a carefully selected GAN-discriminator on some real outlier data already achieves the state-of-the-art. Second, we augment the available set of real open training examples with adversarially synthesized "fake" data. Third and most importantly, we build the discriminator over the features computed by the closed-world K-way networks. Extensive experiments show that OpenGAN significantly outperforms prior open-set methods.
Multimodal Object Detection via Bayesian Fusion
Apr 07, 2021
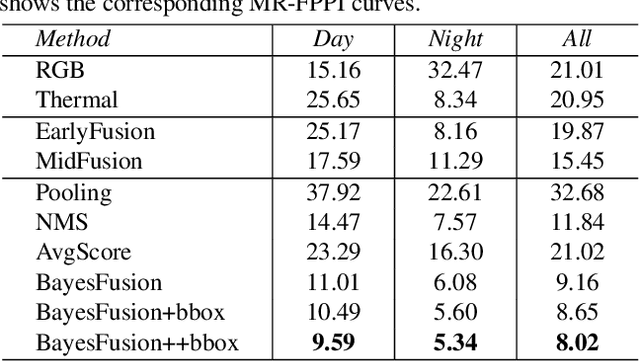
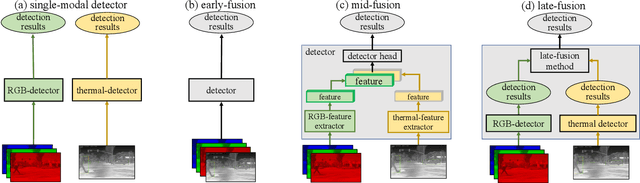

Object detection with multimodal inputs can improve many safety-critical perception systems such as autonomous vehicles (AVs). Motivated by AVs that operate in both day and night, we study multimodal object detection with RGB and thermal cameras, since the latter can provide much stronger object signatures under poor illumination. We explore strategies for fusing information from different modalities. Our key contribution is a non-learned late-fusion method that fuses together bounding box detections from different modalities via a simple probabilistic model derived from first principles. Our simple approach, which we call Bayesian Fusion, is readily derived from conditional independence assumptions across different modalities. We apply our approach to benchmarks containing both aligned (KAIST) and unaligned (FLIR) multimodal sensor data. Our Bayesian Fusion outperforms prior work by more than 13% in relative performance.
When Perspective Comes for Free: Improving Depth Prediction with Camera Pose Encoding
Jul 08, 2020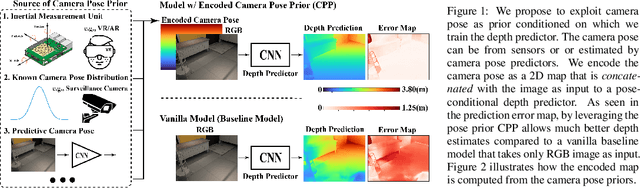
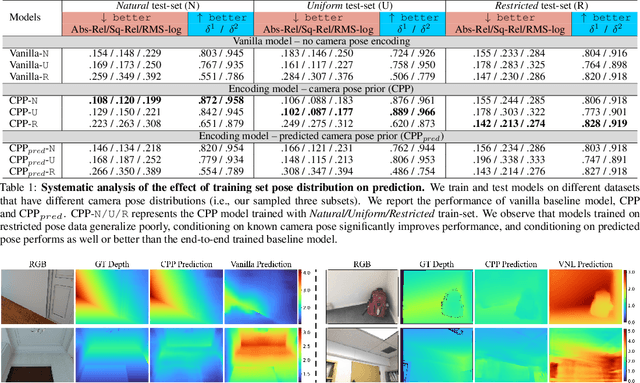
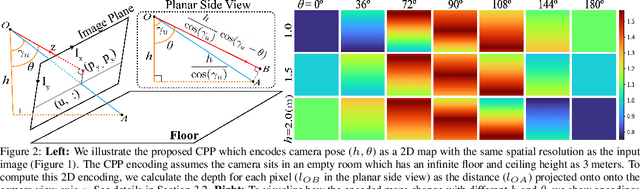

Monocular depth prediction is a highly underdetermined problem and recent progress has relied on high-capacity CNNs to effectively learn scene statistics that disambiguate estimation. However, we observe that such models are strongly biased by the distribution of camera poses seen during training and fail to generalize to novel viewpoints, even when the scene geometry distribution remains fixed. To address this challenge, we propose a factored approach that estimates pose first, followed by a conditional depth estimation model that takes an encoding of the camera pose prior (CPP) as input. In many applications, a strong test-time pose prior comes for free, e.g., from inertial sensors or static camera deployment. A factored approach also allows for adapting pose prior estimation to new test domains using only pose supervision, without the need for collecting expensive ground-truth depth required for end-to-end training. We evaluate our pose-conditional depth predictor (trained on synthetic indoor scenes) on a real-world test set. Our factored approach, which only requires camera pose supervision for training, outperforms recent state-of-the-art methods trained with full scene depth supervision on 10x more data.