 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathNet: a Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
Apr 20, 2026Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce MathNet, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models and mathematical retrieval in embedding-based systems. MathNet spans 47 countries, 17 languages, and two decades of competitions, comprising 30,676 expert-authored problems with solutions across diverse domains. In addition to the core dataset, we construct a retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts. MathNet supports three tasks: (i) Problem Solving, (ii) Math-Aware Retrieval, and (iii) Retrieval-Augmented Problem Solving. Experimental results show that even state-of-the-art reasoning models (78.4% for Gemini-3.1-Pro and 69.3% for GPT-5) remain challenged, while embedding models struggle to retrieve equivalent problems. We further show that retrieval-augmented generation performance is highly sensitive to retrieval quality; for example, DeepSeek-V3.2-Speciale achieves gains of up to 12%, obtaining the highest scores on the benchmark. MathNet provides the largest high-quality Olympiad dataset together with the first benchmark for evaluating mathematical problem retrieval, and we publicly release both the dataset and benchmark at https://mathnet.mit.edu.
* ICLR 2026; Website: http://mathnet.mit.edu
Beyond I-Con: Exploring New Dimension of Distance Measures in Representation Learning
Sep 05, 2025The Information Contrastive (I-Con) framework revealed that over 23 representation learning methods implicitly minimize KL divergence between data and learned distributions that encode similarities between data points. However, a KL-based loss may be misaligned with the true objective, and properties of KL divergence such as asymmetry and unboundedness may create optimization challenges. We present Beyond I-Con, a framework that enables systematic discovery of novel loss functions by exploring alternative statistical divergences and similarity kernels. Key findings: (1) on unsupervised clustering of DINO-ViT embeddings, we achieve state-of-the-art results by modifying the PMI algorithm to use total variation (TV) distance; (2) on supervised contrastive learning, we outperform the standard approach by using TV and a distance-based similarity kernel instead of KL and an angular kernel; (3) on dimensionality reduction, we achieve superior qualitative results and better performance on downstream tasks than SNE by replacing KL with a bounded f-divergence. Our results highlight the importance of considering divergence and similarity kernel choices in representation learning optimization.
I-Con: A Unifying Framework for Representation Learning
Apr 23, 2025



As the field of representation learning grows, there has been a proliferation of different loss functions to solve different classes of problems. We introduce a single information-theoretic equation that generalizes a large collection of modern loss functions in machine learning. In particular, we introduce a framework that shows that several broad classes of machine learning methods are precisely minimizing an integrated KL divergence between two conditional distributions: the supervisory and learned representations. This viewpoint exposes a hidden information geometry underlying clustering, spectral methods, dimensionality reduction, contrastive learning, and supervised learning. This framework enables the development of new loss functions by combining successful techniques from across the literature. We not only present a wide array of proofs, connecting over 23 different approaches, but we also leverage these theoretical results to create state-of-the-art unsupervised image classifiers that achieve a +8% improvement over the prior state-of-the-art on unsupervised classification on ImageNet-1K. We also demonstrate that I-Con can be used to derive principled debiasing methods which improve contrastive representation learners.
Vision-Language Models Do Not Understand Negation
Jan 16, 2025



Many practical vision-language applications require models that understand negation, e.g., when using natural language to retrieve images which contain certain objects but not others. Despite advancements in vision-language models (VLMs) through large-scale training, their ability to comprehend negation remains underexplored. This study addresses the question: how well do current VLMs understand negation? We introduce NegBench, a new benchmark designed to evaluate negation understanding across 18 task variations and 79k examples spanning image, video, and medical datasets. The benchmark consists of two core tasks designed to evaluate negation understanding in diverse multimodal settings: Retrieval with Negation and Multiple Choice Questions with Negated Captions. Our evaluation reveals that modern VLMs struggle significantly with negation, often performing at chance level. To address these shortcomings, we explore a data-centric approach wherein we finetune CLIP models on large-scale synthetic datasets containing millions of negated captions. We show that this approach can result in a 10% increase in recall on negated queries and a 40% boost in accuracy on multiple-choice questions with negated captions.
Long-Tailed Recognition via Weight Balancing
Mar 27, 2022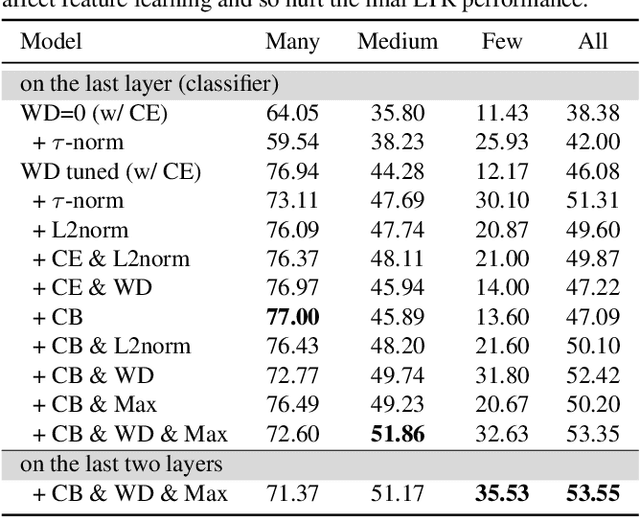
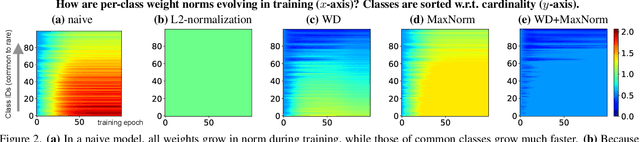
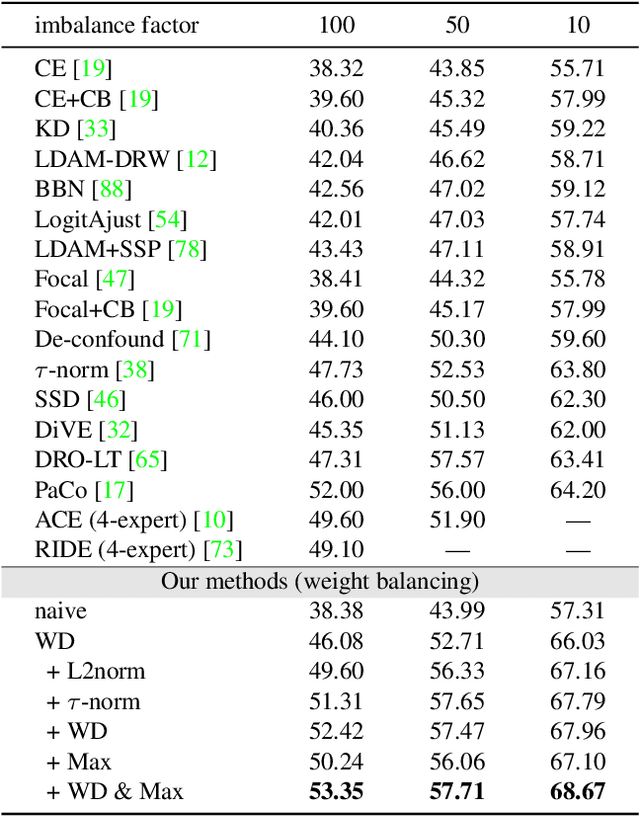
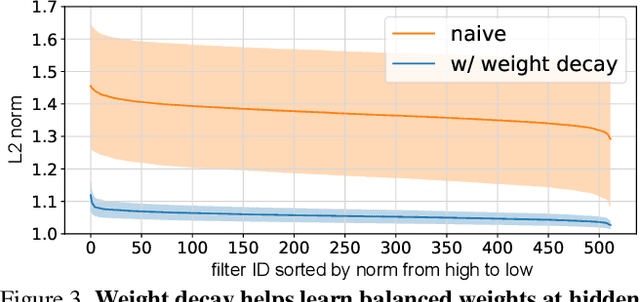
In the real open world, data tends to follow long-tailed class distributions, motivating the well-studied long-tailed recognition (LTR) problem. Naive training produces models that are biased toward common classes in terms of higher accuracy. The key to addressing LTR is to balance various aspects including data distribution, training losses, and gradients in learning. We explore an orthogonal direction, weight balancing, motivated by the empirical observation that the naively trained classifier has "artificially" larger weights in norm for common classes (because there exists abundant data to train them, unlike the rare classes). We investigate three techniques to balance weights, L2-normalization, weight decay, and MaxNorm. We first point out that L2-normalization "perfectly" balances per-class weights to be unit norm, but such a hard constraint might prevent classes from learning better classifiers. In contrast, weight decay penalizes larger weights more heavily and so learns small balanced weights; the MaxNorm constraint encourages growing small weights within a norm ball but caps all the weights by the radius. Our extensive study shows that both help learn balanced weights and greatly improve the LTR accuracy. Surprisingly, weight decay, although underexplored in LTR, significantly improves over prior work. Therefore, we adopt a two-stage training paradigm and propose a simple approach to LTR: (1) learning features using the cross-entropy loss by tuning weight decay, and (2) learning classifiers using class-balanced loss by tuning weight decay and MaxNorm. Our approach achieves the state-of-the-art accuracy on five standard benchmarks, serving as a future baseline for long-tailed recognition.