 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective Communication: An Auction-based Method for Language Agent Interaction
Nov 17, 2025Multi-agent systems (MAS) built on large language models (LLMs) often suffer from inefficient "free-for-all" communication, leading to exponential token costs and low signal-to-noise ratios that hinder their practical deployment. We challenge the notion that more communication is always beneficial, hypothesizing instead that the core issue is the absence of resource rationality. We argue that "free" communication, by ignoring the principle of scarcity, inherently breeds inefficiency and unnecessary expenses. To address this, we introduce the Dynamic Auction-based Language Agent (DALA), a novel framework that treats communication bandwidth as a scarce and tradable resource. Specifically, our DALA regards inter-agent communication as a centralized auction, where agents learn to bid for the opportunity to speak based on the predicted value density of their messages. Thus, our DALA intrinsically encourages agents to produce concise, informative messages while filtering out low-value communication. Extensive and comprehensive experiments demonstrate that our economically-driven DALA achieves new state-of-the-art performance across seven challenging reasoning benchmarks, including 84.32% on MMLU and a 91.21% pass@1 rate on HumanEval. Note that this is accomplished with remarkable efficiency, i.e., our DALA uses only 6.25 million tokens, a fraction of the resources consumed by current state-of-the-art methods on GSM8K. Further analysis reveals that our DALA cultivates the emergent skill of strategic silence, effectively adapting its communication strategies from verbosity to silence in a dynamical manner via resource constraints.
Top-Down Semantic Refinement for Image Captioning
Oct 25, 2025Large Vision-Language Models (VLMs) face an inherent contradiction in image captioning: their powerful single-step generation capabilities often lead to a myopic decision-making process. This makes it difficult to maintain global narrative coherence while capturing rich details, a limitation that is particularly pronounced in tasks that require multi-step and complex scene description. To overcome this fundamental challenge, we redefine image captioning as a goal-oriented hierarchical refinement planning problem, and further propose a novel framework, named Top-Down Semantic Refinement (TDSR), which models the generation process as a Markov Decision Process (MDP). However, planning within the vast state space of a VLM presents a significant computational hurdle. Our core contribution, therefore, is the design of a highly efficient Monte Carlo Tree Search (MCTS) algorithm tailored for VLMs. By incorporating a visual-guided parallel expansion and a lightweight value network, our TDSR reduces the call frequency to the expensive VLM by an order of magnitude without sacrificing planning quality. Furthermore, an adaptive early stopping mechanism dynamically matches computational overhead to the image's complexity. Extensive experiments on multiple benchmarks, including DetailCaps, COMPOSITIONCAP, and POPE, demonstrate that our TDSR, as a plug-and-play module, can significantly enhance the performance of existing VLMs (e.g., LLaVA-1.5, Qwen2.5-VL) by achieving state-of-the-art or highly competitive results in fine-grained description, compositional generalization, and hallucination suppression.
TimeCausality: Evaluating the Causal Ability in Time Dimension for Vision Language Models
May 21, 2025
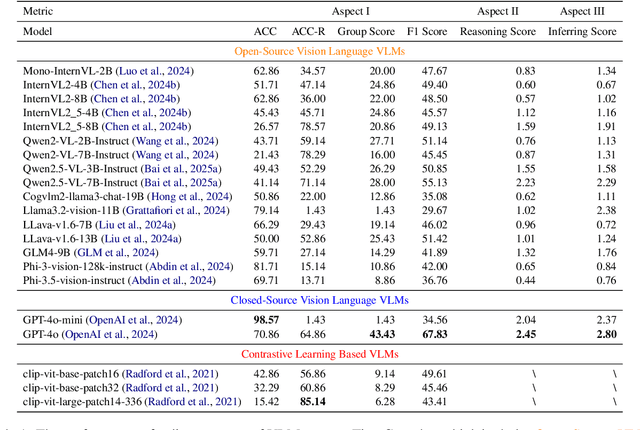


Reasoning about temporal causality, particularly irreversible transformations of objects governed by real-world knowledge (e.g., fruit decay and human aging), is a fundamental aspect of human visual understanding. Unlike temporal perception based on simple event sequences, this form of reasoning requires a deeper comprehension of how object states change over time. Although the current powerful Vision-Language Models (VLMs) have demonstrated impressive performance on a wide range of downstream tasks, their capacity to reason about temporal causality remains underexplored. To address this gap, we introduce \textbf{TimeCausality}, a novel benchmark specifically designed to evaluate the causal reasoning ability of VLMs in the temporal dimension. Based on our TimeCausality, we find that while the current SOTA open-source VLMs have achieved performance levels comparable to closed-source models like GPT-4o on various standard visual question answering tasks, they fall significantly behind on our benchmark compared with their closed-source competitors. Furthermore, even GPT-4o exhibits a marked drop in performance on TimeCausality compared to its results on other tasks. These findings underscore the critical need to incorporate temporal causality into the evaluation and development of VLMs, and they highlight an important challenge for the open-source VLM community moving forward. Code and Data are available at \href{https://github.com/Zeqing-Wang/TimeCausality }{TimeCausality}.
WiFi-based Multi-task Sensing
Nov 26, 2021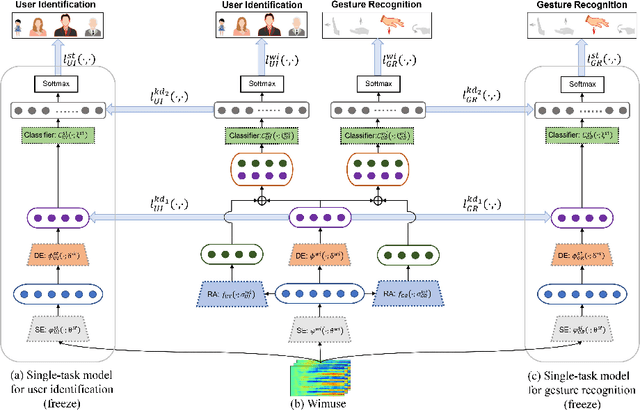
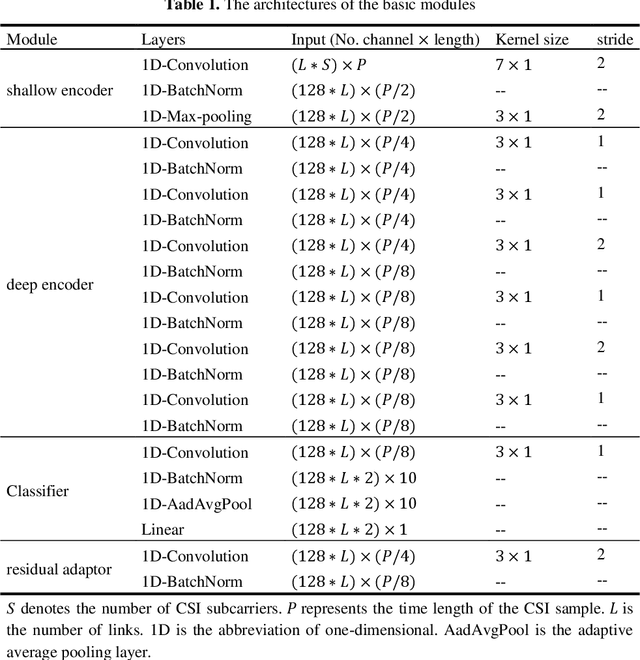
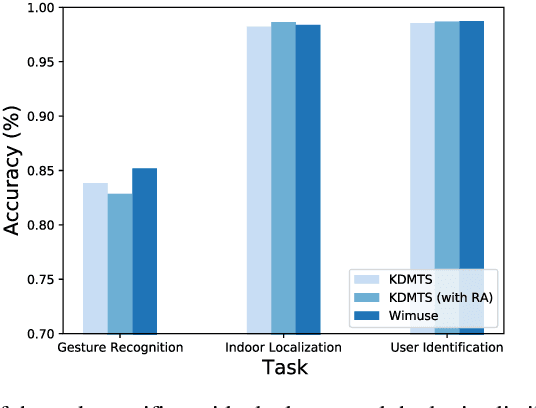
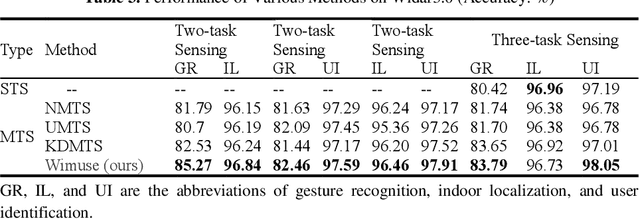
WiFi-based sensing has aroused immense attention over recent years. The rationale is that the signal fluctuations caused by humans carry the information of human behavior which can be extracted from the channel state information of WiFi. Still, the prior studies mainly focus on single-task sensing (STS), e.g., gesture recognition, indoor localization, user identification. Since the fluctuations caused by gestures are highly coupling with body features and the user's location, we propose a WiFi-based multi-task sensing model (Wimuse) to perform gesture recognition, indoor localization, and user identification tasks simultaneously. However, these tasks have different difficulty levels (i.e., imbalance issue) and need task-specific information (i.e., discrepancy issue). To address these issues, the knowledge distillation technique and task-specific residual adaptor are adopted in Wimuse. We first train the STS model for each task. Then, for solving the imbalance issue, the extracted common feature in Wimuse is encouraged to get close to the counterpart features of the STS models. Further, for each task, a task-specific residual adaptor is applied to extract the task-specific compensation feature which is fused with the common feature to address the discrepancy issue. We conduct comprehensive experiments on three public datasets and evaluation suggests that Wimuse achieves state-of-the-art performance with the average accuracy of 85.20%, 98.39%, and 98.725% on the joint task of gesture recognition, indoor localization, and user identification, respectively.