 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Search When You Can Transfer? Amortized Agentic Workflow Design from Structural Priors
Apr 27, 2026Automated agentic workflow design currently relies on per-task iterative search, which is computationally prohibitive and fails to reuse structural knowledge across tasks. We observe that optimized workflows converge to a small family of domain-specific topologies, suggesting that this combinatorial search is largely redundant. Building on this insight, we propose SWIFT (Synthesizing Workflows via Few-shot Transfer), a framework that amortizes workflow design into reusable structural priors. SWIFT first distills compositional heuristics and output-interface contracts from contrastive analysis of prior search trajectories across source tasks. At inference time, it conditions a single LLM generation pass on these priors together with cross-task workflow demonstrations to synthesize a complete, executable workflow for an unseen target task, bypassing iterative search entirely. On five benchmarks, SWIFT outperforms the state-of-the-art search-based method while reducing marginal per-task optimization cost by three orders of magnitude. It further generalizes to four additional unseen benchmarks and transfers successfully from GPT-4o-mini to three additional foundation models (Grok, Qwen, Gemma). Controlled ablations reveal that workflow demonstrations primarily transfer topological structure rather than surface semantics: replacing all operator names with random strings still retains over 93% of the full system's average performance.
Models Know Their Shortcuts: Deployment-Time Shortcut Mitigation
Apr 14, 2026Pretrained language models often rely on superficial features that appear predictive during training yet fail to generalize at test time, a phenomenon known as shortcut learning. Existing mitigation methods generally operate at training time and require heavy supervision such as access to the original training data or prior knowledge of shortcut type. We propose Shortcut Guardrail, a deployment-time framework that mitigates token-level shortcuts without access to the original training data or shortcut annotations. Our key insight is that gradient-based attribution on a biased model highlights shortcut tokens. Building on this finding, we train a lightweight LoRA-based debiasing module with a Masked Contrastive Learning (MaskCL) objective that encourages consistent representations with or without individual tokens. Across sentiment classification, toxicity detection, and natural language inference under both naturally occurring and controlled shortcuts, Shortcut Guardrail improves overall accuracy and worst-group accuracy over the unmitigated model under distribution shifts while preserving in-distribution performance.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Boosting Dermatoscopic Lesion Segmentation via Diffusion Models with Visual and Textual Prompts
Oct 04, 2023



Image synthesis approaches, e.g., generative adversarial networks, have been popular as a form of data augmentation in medical image analysis tasks. It is primarily beneficial to overcome the shortage of publicly accessible data and associated quality annotations. However, the current techniques often lack control over the detailed contents in generated images, e.g., the type of disease patterns, the location of lesions, and attributes of the diagnosis. In this work, we adapt the latest advance in the generative model, i.e., the diffusion model, with the added control flow using lesion-specific visual and textual prompts for generating dermatoscopic images. We further demonstrate the advantage of our diffusion model-based framework over the classical generation models in both the image quality and boosting the segmentation performance on skin lesions. It can achieve a 9% increase in the SSIM image quality measure and an over 5% increase in Dice coefficients over the prior arts.
An evaluation of U-Net in Renal Structure Segmentation
Sep 06, 2022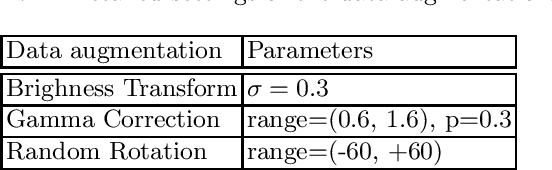
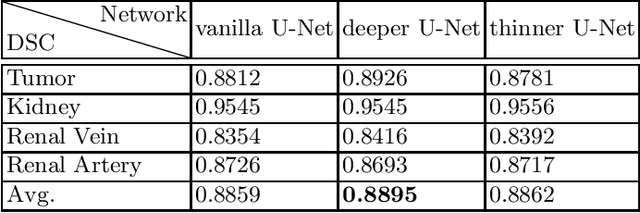
Renal structure segmentation from computed tomography angiography~(CTA) is essential for many computer-assisted renal cancer treatment applications. Kidney PArsing~(KiPA 2022) Challenge aims to build a fine-grained multi-structure dataset and improve the segmentation of multiple renal structures. Recently, U-Net has dominated the medical image segmentation. In the KiPA challenge, we evaluated several U-Net variants and selected the best models for the final submission.