 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Search When You Can Transfer? Amortized Agentic Workflow Design from Structural Priors
Apr 27, 2026Automated agentic workflow design currently relies on per-task iterative search, which is computationally prohibitive and fails to reuse structural knowledge across tasks. We observe that optimized workflows converge to a small family of domain-specific topologies, suggesting that this combinatorial search is largely redundant. Building on this insight, we propose SWIFT (Synthesizing Workflows via Few-shot Transfer), a framework that amortizes workflow design into reusable structural priors. SWIFT first distills compositional heuristics and output-interface contracts from contrastive analysis of prior search trajectories across source tasks. At inference time, it conditions a single LLM generation pass on these priors together with cross-task workflow demonstrations to synthesize a complete, executable workflow for an unseen target task, bypassing iterative search entirely. On five benchmarks, SWIFT outperforms the state-of-the-art search-based method while reducing marginal per-task optimization cost by three orders of magnitude. It further generalizes to four additional unseen benchmarks and transfers successfully from GPT-4o-mini to three additional foundation models (Grok, Qwen, Gemma). Controlled ablations reveal that workflow demonstrations primarily transfer topological structure rather than surface semantics: replacing all operator names with random strings still retains over 93% of the full system's average performance.
Models Know Their Shortcuts: Deployment-Time Shortcut Mitigation
Apr 14, 2026Pretrained language models often rely on superficial features that appear predictive during training yet fail to generalize at test time, a phenomenon known as shortcut learning. Existing mitigation methods generally operate at training time and require heavy supervision such as access to the original training data or prior knowledge of shortcut type. We propose Shortcut Guardrail, a deployment-time framework that mitigates token-level shortcuts without access to the original training data or shortcut annotations. Our key insight is that gradient-based attribution on a biased model highlights shortcut tokens. Building on this finding, we train a lightweight LoRA-based debiasing module with a Masked Contrastive Learning (MaskCL) objective that encourages consistent representations with or without individual tokens. Across sentiment classification, toxicity detection, and natural language inference under both naturally occurring and controlled shortcuts, Shortcut Guardrail improves overall accuracy and worst-group accuracy over the unmitigated model under distribution shifts while preserving in-distribution performance.
Computationally Efficient High-Dimensional Bayesian Optimization via Variable Selection
Sep 20, 2021



Bayesian Optimization (BO) is a method for globally optimizing black-box functions. While BO has been successfully applied to many scenarios, developing effective BO algorithms that scale to functions with high-dimensional domains is still a challenge. Optimizing such functions by vanilla BO is extremely time-consuming. Alternative strategies for high-dimensional BO that are based on the idea of embedding the high-dimensional space to the one with low dimension are sensitive to the choice of the embedding dimension, which needs to be pre-specified. We develop a new computationally efficient high-dimensional BO method that exploits variable selection. Our method is able to automatically learn axis-aligned sub-spaces, i.e. spaces containing selected variables, without the demand of any pre-specified hyperparameters. We theoretically analyze the computational complexity of our algorithm and derive the regret bound. We empirically show the efficacy of our method on several synthetic and real problems.
How much data is sufficient to learn high-performing algorithms?
Sep 09, 2019
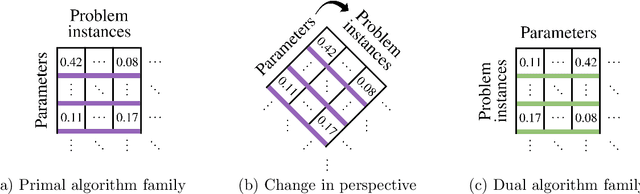
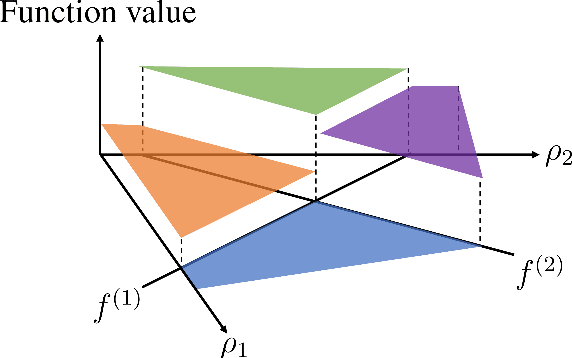
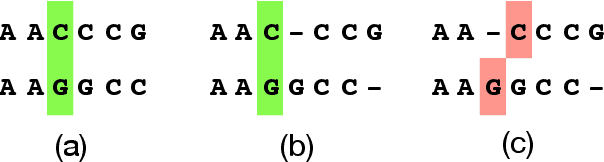
Algorithms for scientific analysis typically have tunable parameters that significantly influence computational efficiency and solution quality. If a parameter setting leads to strong algorithmic performance on average over a set of typical problem instances, that parameter setting---ideally---will perform well in the future. However, if the set of typical problem instances is small, average performance will not generalize to future performance. This raises the question: how large should this set be? We answer this question for any algorithm satisfying an easy-to-describe, ubiquitous property: its performance is a piecewise-structured function of its parameters. We are the first to provide a unified sample complexity framework for algorithm parameter configuration; prior research followed case-by-case analyses. We present applications from diverse domains, including biology, political science, and economics.