 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNet Can Be Pruned 60x: Introducing Network Purification and Unused Path Removal after Weight Pruning
Apr 30, 2019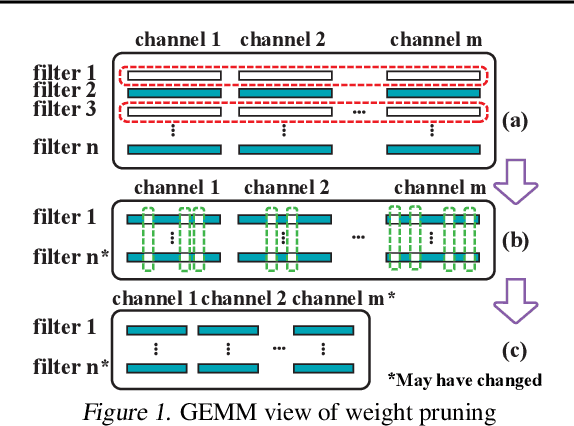
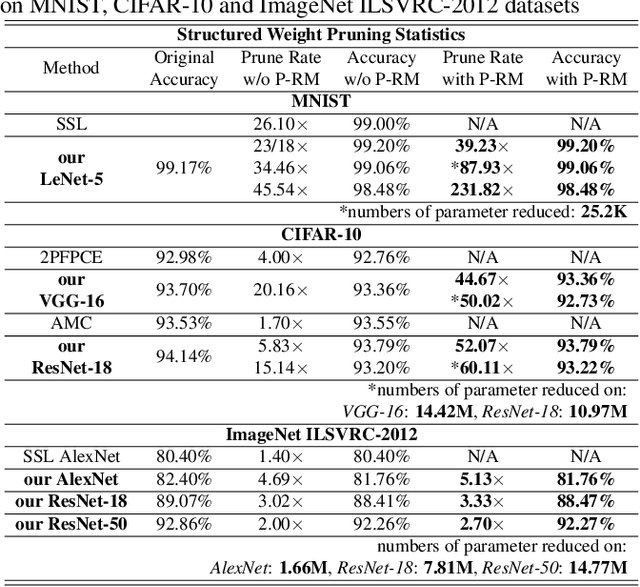
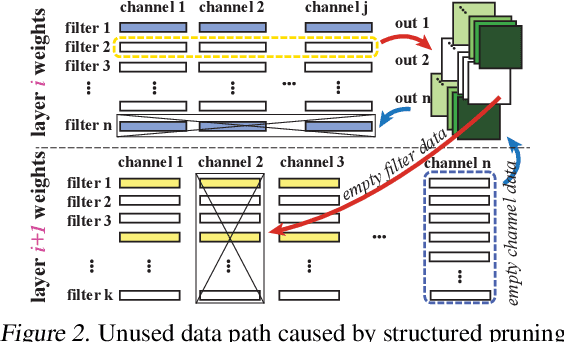
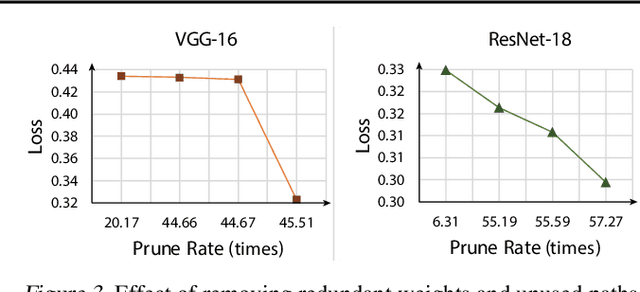
The state-of-art DNN structures involve high computation and great demand for memory storage which pose intensive challenge on DNN framework resources. To mitigate the challenges, weight pruning techniques has been studied. However, high accuracy solution for extreme structured pruning that combines different types of structured sparsity still waiting for unraveling due to the extremely reduced weights in DNN networks. In this paper, we propose a DNN framework which combines two different types of structured weight pruning (filter and column prune) by incorporating alternating direction method of multipliers (ADMM) algorithm for better prune performance. We are the first to find non-optimality of ADMM process and unused weights in a structured pruned model, and further design an optimization framework which contains the first proposed Network Purification and Unused Path Removal algorithms which are dedicated to post-processing an structured pruned model after ADMM steps. Some high lights shows we achieve 232x compression on LeNet-5, 60x compression on ResNet-18 CIFAR-10 and over 5x compression on AlexNet. We share our models at anonymous link http://bit.ly/2VJ5ktv.
Progressive DNN Compression: A Key to Achieve Ultra-High Weight Pruning and Quantization Rates using ADMM
Mar 30, 2019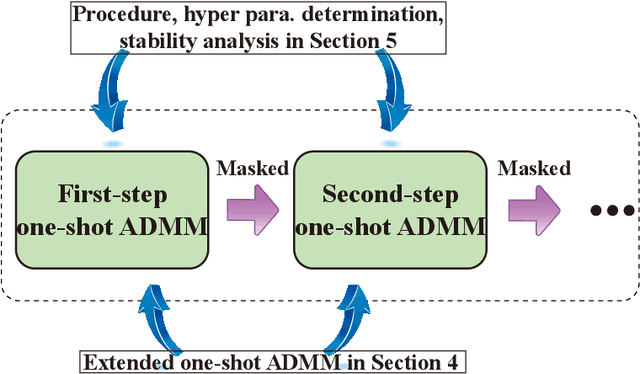
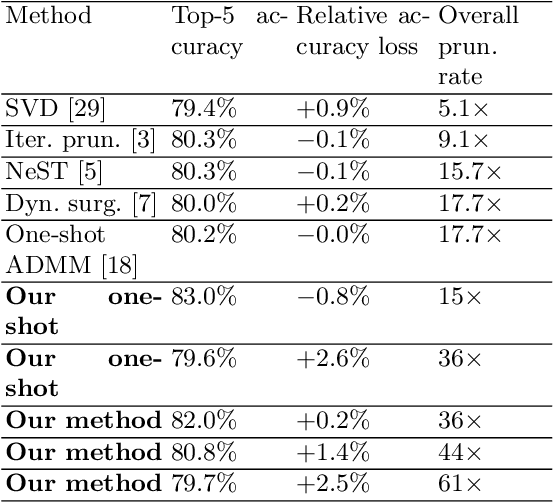
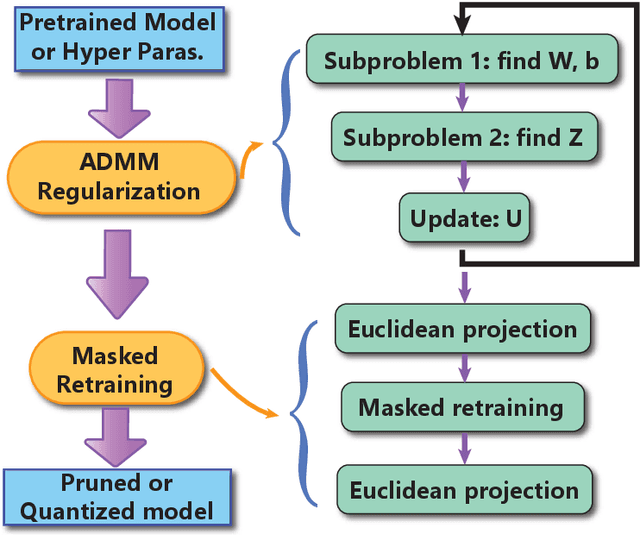
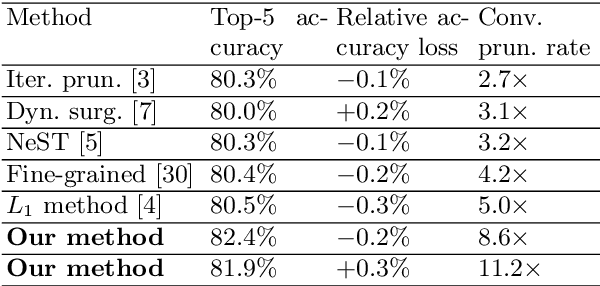
Weight pruning and weight quantization are two important categories of DNN model compression. Prior work on these techniques are mainly based on heuristics. A recent work developed a systematic frame-work of DNN weight pruning using the advanced optimization technique ADMM (Alternating Direction Methods of Multipliers), achieving one of state-of-art in weight pruning results. In this work, we first extend such one-shot ADMM-based framework to guarantee solution feasibility and provide fast convergence rate, and generalize to weight quantization as well. We have further developed a multi-step, progressive DNN weight pruning and quantization framework, with dual benefits of (i) achieving further weight pruning/quantization thanks to the special property of ADMM regularization, and (ii) reducing the search space within each step. Extensive experimental results demonstrate the superior performance compared with prior work. Some highlights: (i) we achieve 246x,36x, and 8x weight pruning on LeNet-5, AlexNet, and ResNet-50 models, respectively, with (almost) zero accuracy loss; (ii) even a significant 61x weight pruning in AlexNet (ImageNet) results in only minor degradation in actual accuracy compared with prior work; (iii) we are among the first to derive notable weight pruning results for ResNet and MobileNet models; (iv) we derive the first lossless, fully binarized (for all layers) LeNet-5 for MNIST and VGG-16 for CIFAR-10; and (v) we derive the first fully binarized (for all layers) ResNet for ImageNet with reasonable accuracy loss.
Learning Topics using Semantic Locality
Apr 11, 2018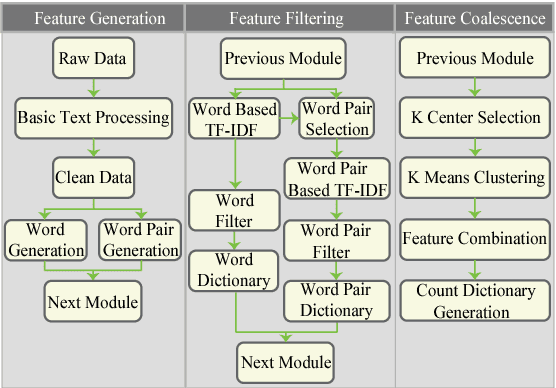
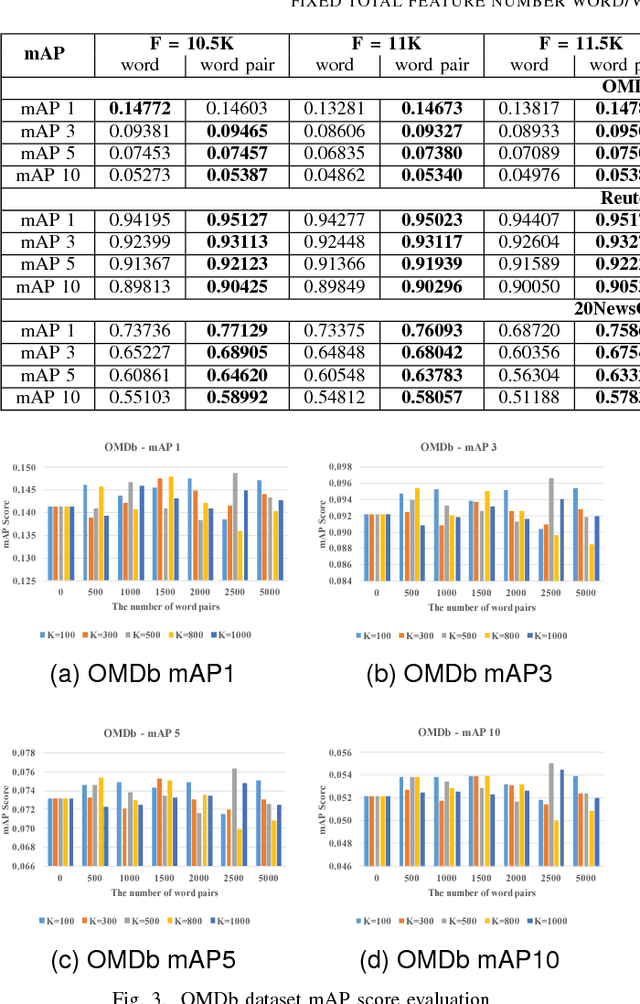
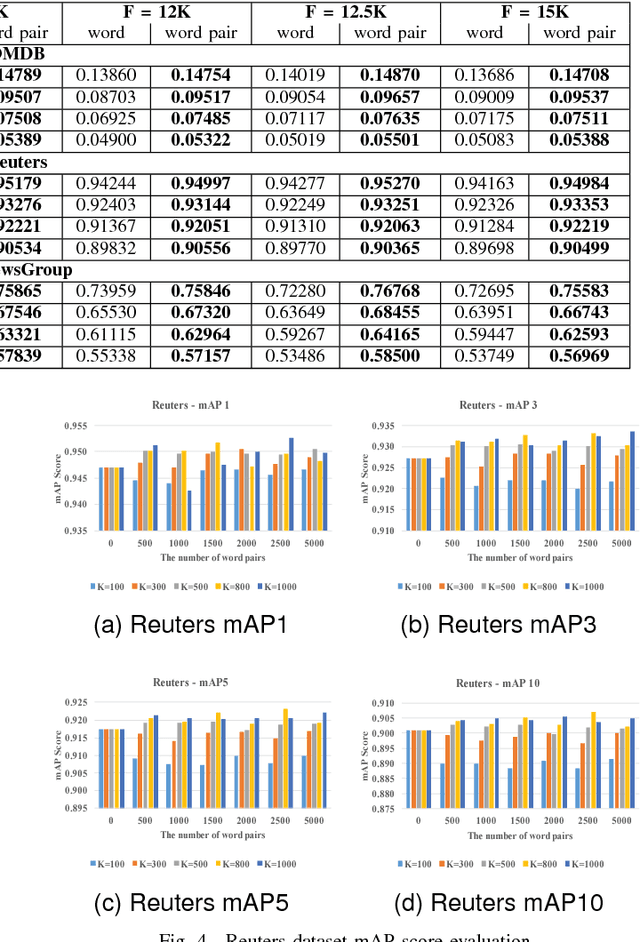
The topic modeling discovers the latent topic probability of the given text documents. To generate the more meaningful topic that better represents the given document, we proposed a new feature extraction technique which can be used in the data preprocessing stage. The method consists of three steps. First, it generates the word/word-pair from every single document. Second, it applies a two-way TF-IDF algorithm to word/word-pair for semantic filtering. Third, it uses the K-means algorithm to merge the word pairs that have the similar semantic meaning. Experiments are carried out on the Open Movie Database (OMDb), Reuters Dataset and 20NewsGroup Dataset. The mean Average Precision score is used as the evaluation metric. Comparing our results with other state-of-the-art topic models, such as Latent Dirichlet allocation and traditional Restricted Boltzmann Machines. Our proposed data preprocessing can improve the generated topic accuracy by up to 12.99\%.
FFT-Based Deep Learning Deployment in Embedded Systems
Dec 13, 2017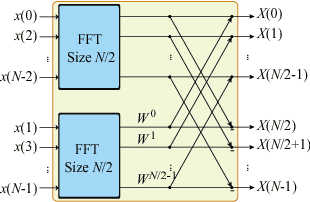

Deep learning has delivered its powerfulness in many application domains, especially in image and speech recognition. As the backbone of deep learning, deep neural networks (DNNs) consist of multiple layers of various types with hundreds to thousands of neurons. Embedded platforms are now becoming essential for deep learning deployment due to their portability, versatility, and energy efficiency. The large model size of DNNs, while providing excellent accuracy, also burdens the embedded platforms with intensive computation and storage. Researchers have investigated on reducing DNN model size with negligible accuracy loss. This work proposes a Fast Fourier Transform (FFT)-based DNN training and inference model suitable for embedded platforms with reduced asymptotic complexity of both computation and storage, making our approach distinguished from existing approaches. We develop the training and inference algorithms based on FFT as the computing kernel and deploy the FFT-based inference model on embedded platforms achieving extraordinary processing speed.
A Hierarchical Framework of Cloud Resource Allocation and Power Management Using Deep Reinforcement Learning
Aug 11, 2017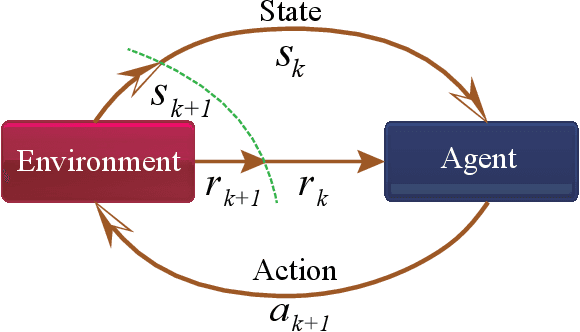
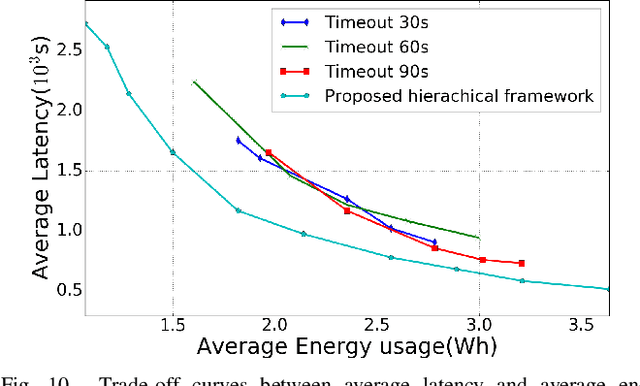
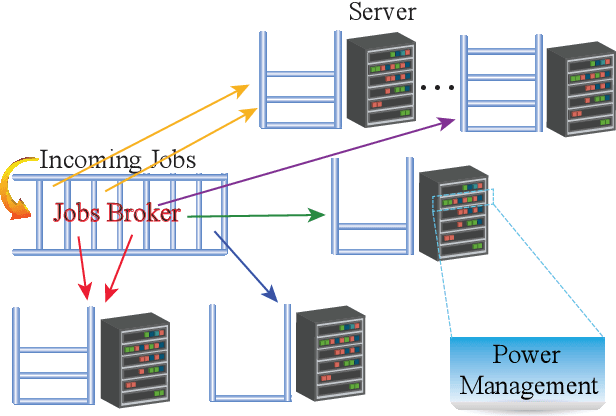
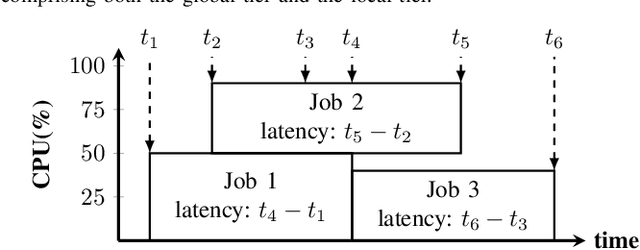
Automatic decision-making approaches, such as reinforcement learning (RL), have been applied to (partially) solve the resource allocation problem adaptively in the cloud computing system. However, a complete cloud resource allocation framework exhibits high dimensions in state and action spaces, which prohibit the usefulness of traditional RL techniques. In addition, high power consumption has become one of the critical concerns in design and control of cloud computing systems, which degrades system reliability and increases cooling cost. An effective dynamic power management (DPM) policy should minimize power consumption while maintaining performance degradation within an acceptable level. Thus, a joint virtual machine (VM) resource allocation and power management framework is critical to the overall cloud computing system. Moreover, novel solution framework is necessary to address the even higher dimensions in state and action spaces. In this paper, we propose a novel hierarchical framework for solving the overall resource allocation and power management problem in cloud computing systems. The proposed hierarchical framework comprises a global tier for VM resource allocation to the servers and a local tier for distributed power management of local servers. The emerging deep reinforcement learning (DRL) technique, which can deal with complicated control problems with large state space, is adopted to solve the global tier problem. Furthermore, an autoencoder and a novel weight sharing structure are adopted to handle the high-dimensional state space and accelerate the convergence speed. On the other hand, the local tier of distributed server power managements comprises an LSTM based workload predictor and a model-free RL based power manager, operating in a distributed manner.