 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Memory-Efficient Vision Transformers: An Activation-Aware Mixed-Rank Compression Strategy
Feb 08, 2024As Vision Transformers (ViTs) increasingly set new benchmarks in computer vision, their practical deployment on inference engines is often hindered by their significant memory bandwidth and (on-chip) memory footprint requirements. This paper addresses this memory limitation by introducing an activation-aware model compression methodology that uses selective low-rank weight tensor approximations of different layers to reduce the parameter count of ViTs. The key idea is to decompose the weight tensors into a sum of two parameter-efficient tensors while minimizing the error between the product of the input activations with the original weight tensor and the product of the input activations with the approximate tensor sum. This approximation is further refined by adopting an efficient layer-wise error compensation technique that uses the gradient of the layer's output loss. The combination of these techniques achieves excellent results while it avoids being trapped in a shallow local minimum early in the optimization process and strikes a good balance between the model compression and output accuracy. Notably, the presented method significantly reduces the parameter count of DeiT-B by 60% with less than 1% accuracy drop on the ImageNet dataset, overcoming the usual accuracy degradation seen in low-rank approximations. In addition to this, the presented compression technique can compress large DeiT/ViT models to have about the same model size as smaller DeiT/ViT variants while yielding up to 1.8% accuracy gain. These results highlight the efficacy of our approach, presenting a viable solution for embedding ViTs in memory-constrained environments without compromising their performance.
Low-Precision Mixed-Computation Models for Inference on Edge
Dec 03, 2023



This paper presents a mixed-computation neural network processing approach for edge applications that incorporates low-precision (low-width) Posit and low-precision fixed point (FixP) number systems. This mixed-computation approach employs 4-bit Posit (Posit4), which has higher precision around zero, for representing weights with high sensitivity, while it uses 4-bit FixP (FixP4) for representing other weights. A heuristic for analyzing the importance and the quantization error of the weights is presented to assign the proper number system to different weights. Additionally, a gradient approximation for Posit representation is introduced to improve the quality of weight updates in the backpropagation process. Due to the high energy consumption of the fully Posit-based computations, neural network operations are carried out in FixP or Posit/FixP. An efficient hardware implementation of a MAC operation with a first Posit operand and FixP for a second operand and accumulator is presented. The efficacy of the proposed low-precision mixed-computation approach is extensively assessed on vision and language models. The results show that, on average, the accuracy of the mixed-computation is about 1.5% higher than that of FixP with a cost of 0.19% energy overhead.
Sensitivity-Aware Mixed-Precision Quantization and Width Optimization of Deep Neural Networks Through Cluster-Based Tree-Structured Parzen Estimation
Aug 16, 2023As the complexity and computational demands of deep learning models rise, the need for effective optimization methods for neural network designs becomes paramount. This work introduces an innovative search mechanism for automatically selecting the best bit-width and layer-width for individual neural network layers. This leads to a marked enhancement in deep neural network efficiency. The search domain is strategically reduced by leveraging Hessian-based pruning, ensuring the removal of non-crucial parameters. Subsequently, we detail the development of surrogate models for favorable and unfavorable outcomes by employing a cluster-based tree-structured Parzen estimator. This strategy allows for a streamlined exploration of architectural possibilities and swift pinpointing of top-performing designs. Through rigorous testing on well-known datasets, our method proves its distinct advantage over existing methods. Compared to leading compression strategies, our approach records an impressive 20% decrease in model size without compromising accuracy. Additionally, our method boasts a 12x reduction in search time relative to the best search-focused strategies currently available. As a result, our proposed method represents a leap forward in neural network design optimization, paving the way for quick model design and implementation in settings with limited resources, thereby propelling the potential of scalable deep learning solutions.
SNT: Sharpness-Minimizing Network Transformation for Fast Compression-friendly Pretraining
May 08, 2023Model compression has become the de-facto approach for optimizing the efficiency of vision models. Recently, the focus of most compression efforts has shifted to post-training scenarios due to the very high cost of large-scale pretraining. This has created the need to build compressible models from scratch, which can effectively be compressed after training. In this work, we present a sharpness-minimizing network transformation (SNT) method applied during pretraining that can create models with desirable compressibility and generalizability features. We compare our approach to a well-known sharpness-minimizing optimizer to validate its efficacy in creating a flat loss landscape. To the best of our knowledge, SNT is the first pretraining method that uses an architectural transformation to generate compression-friendly networks. We find that SNT generalizes across different compression tasks and network backbones, delivering consistent improvements over the ADAM baseline with up to 2% accuracy improvement on weight pruning and 5.4% accuracy improvement on quantization. Code to reproduce our results will be made publicly available.
A Fast Training-Free Compression Framework for Vision Transformers
Mar 04, 2023Token pruning has emerged as an effective solution to speed up the inference of large Transformer models. However, prior work on accelerating Vision Transformer (ViT) models requires training from scratch or fine-tuning with additional parameters, which prevents a simple plug-and-play. To avoid high training costs during the deployment stage, we present a fast training-free compression framework enabled by (i) a dense feature extractor in the initial layers; (ii) a sharpness-minimized model which is more compressible; and (iii) a local-global token merger that can exploit spatial relationships at various contexts. We applied our framework to various ViT and DeiT models and achieved up to 2x reduction in FLOPS and 1.8x speedup in inference throughput with <1% accuracy loss, while saving two orders of magnitude shorter training times than existing approaches. Code will be available at https://github.com/johnheo/fast-compress-vit
Efficient Compilation and Mapping of Fixed Function Combinational Logic onto Digital Signal Processors Targeting Neural Network Inference and Utilizing High-level Synthesis
Jul 30, 2022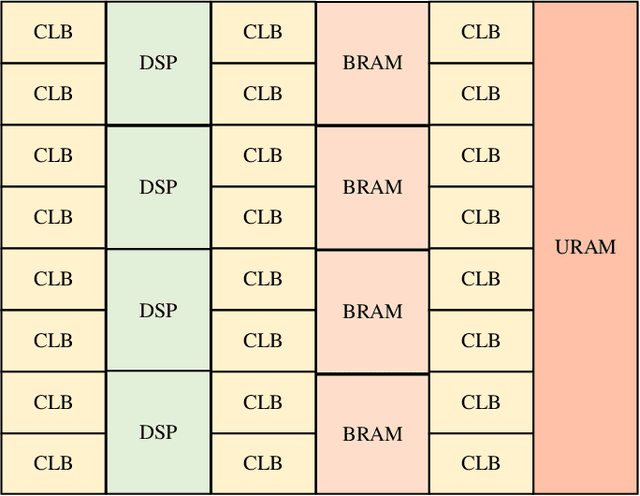
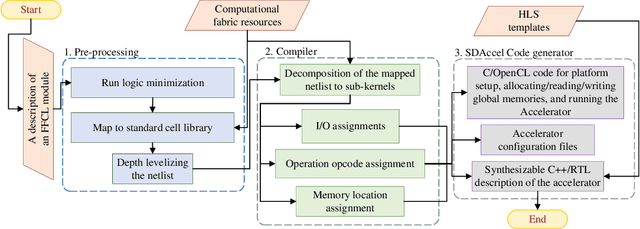
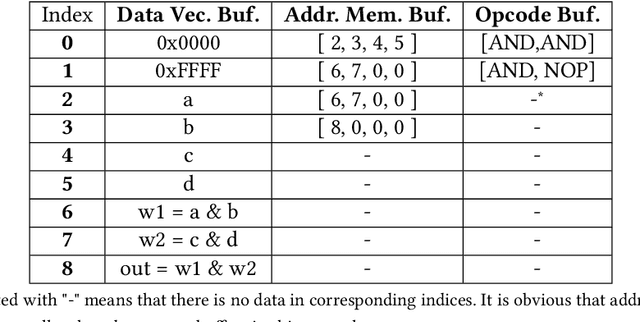
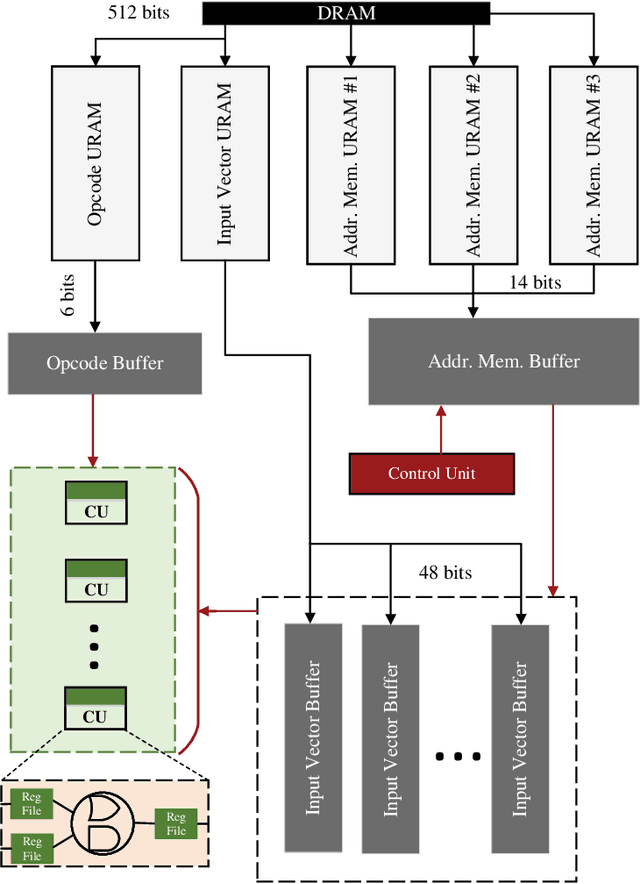
Recent efforts for improving the performance of neural network (NN) accelerators that meet today's application requirements have given rise to a new trend of logic-based NN inference relying on fixed function combinational logic. Mapping such large Boolean functions with many input variables and product terms to digital signal processors (DSPs) on Field-programmable gate arrays (FPGAs) needs a novel framework considering the structure and the reconfigurability of DSP blocks during this process. The proposed methodology in this paper maps the fixed function combinational logic blocks to a set of Boolean functions where Boolean operations corresponding to each function are mapped to DSP devices rather than look-up tables (LUTs) on the FPGAs to take advantage of the high performance, low latency, and parallelism of DSP blocks. % This paper also presents an innovative design and optimization methodology for compilation and mapping of NNs, utilizing fixed function combinational logic to DSPs on FPGAs employing high-level synthesis flow. % Our experimental evaluations across several \REVone{datasets} and selected NNs demonstrate the comparable performance of our framework in terms of the inference latency and output accuracy compared to prior art FPGA-based NN accelerators employing DSPs.
NullaNet Tiny: Ultra-low-latency DNN Inference Through Fixed-function Combinational Logic
Apr 07, 2021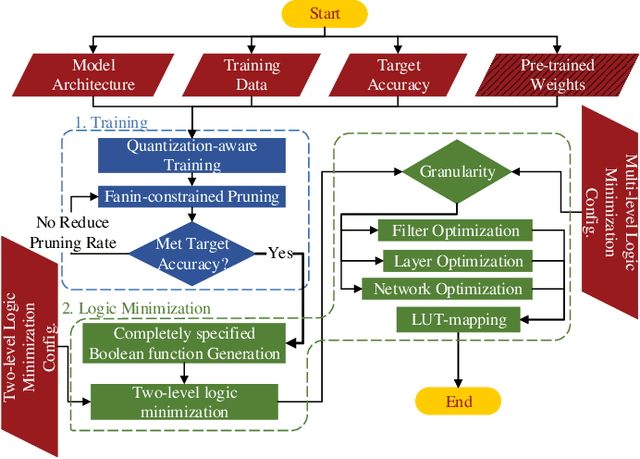
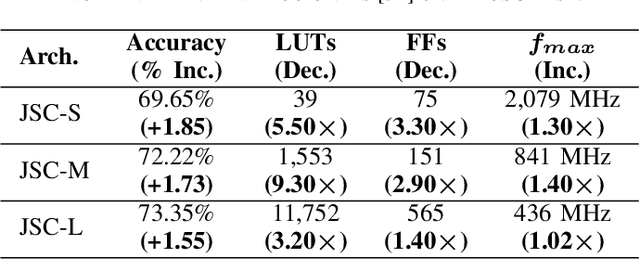
While there is a large body of research on efficient processing of deep neural networks (DNNs), ultra-low-latency realization of these models for applications with stringent, sub-microsecond latency requirements continues to be an unresolved, challenging problem. Field-programmable gate array (FPGA)-based DNN accelerators are gaining traction as a serious contender to replace graphics processing unit/central processing unit-based platforms considering their performance, flexibility, and energy efficiency. This paper presents NullaNet Tiny, an across-the-stack design and optimization framework for constructing resource and energy-efficient, ultra-low-latency FPGA-based neural network accelerators. The key idea is to replace expensive operations required to compute various filter/neuron functions in a DNN with Boolean logic expressions that are mapped to the native look-up tables (LUTs) of the FPGA device (examples of such operations are multiply-and-accumulate and batch normalization). At about the same level of classification accuracy, compared to Xilinx's LogicNets, our design achieves 2.36$\times$ lower latency and 24.42$\times$ lower LUT utilization.
A Tunable Robust Pruning Framework Through Dynamic Network Rewiring of DNNs
Nov 03, 2020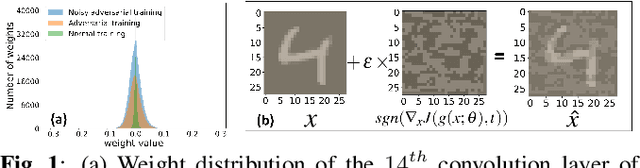

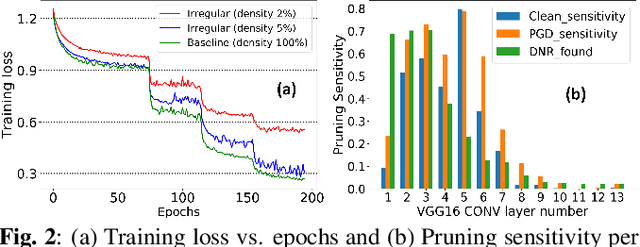
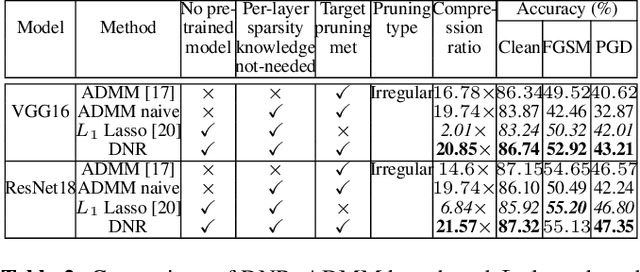
This paper presents a dynamic network rewiring (DNR) method to generate pruned deep neural network (DNN) models that are robust against adversarial attacks yet maintain high accuracy on clean images. In particular, the disclosed DNR method is based on a unified constrained optimization formulation using a hybrid loss function that merges ultra-high model compression with robust adversarial training. This training strategy dynamically adjusts inter-layer connectivity based on per-layer normalized momentum computed from the hybrid loss function. In contrast to existing robust pruning frameworks that require multiple training iterations, the proposed learning strategy achieves an overall target pruning ratio with only a single training iteration and can be tuned to support both irregular and structured channel pruning. To evaluate the merits of DNR, experiments were performed with two widely accepted models, namely VGG16 and ResNet-18, on CIFAR-10, CIFAR-100 as well as with VGG16 on Tiny-ImageNet. Compared to the baseline uncompressed models, DNR provides over20x compression on all the datasets with no significant drop in either clean or adversarial classification accuracy. Moreover, our experiments show that DNR consistently finds compressed models with better clean and adversarial image classification performance than what is achievable through state-of-the-art alternatives.
SynergicLearning: Neural Network-Based Feature Extraction for Highly-Accurate Hyperdimensional Learning
Aug 04, 2020
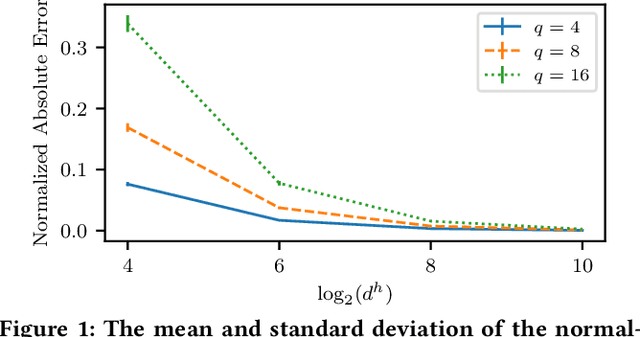
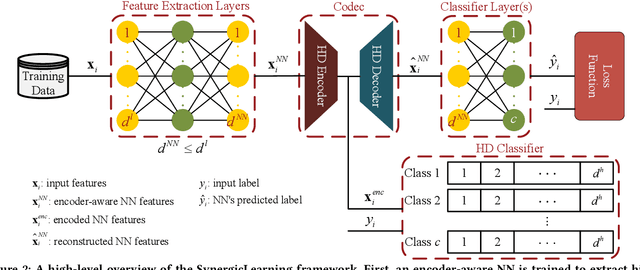

Machine learning models differ in terms of accuracy, computational/memory complexity, training time, and adaptability among other characteristics. For example, neural networks (NNs) are well-known for their high accuracy due to the quality of their automatic feature extraction while brain-inspired hyperdimensional (HD) learning models are famous for their quick training, computational efficiency, and adaptability. This work presents a hybrid, synergic machine learning model that excels at all the said characteristics and is suitable for incremental, on-line learning on a chip. The proposed model comprises an NN and a classifier. The NN acts as a feature extractor and is specifically trained to work well with the classifier that employs the HD computing framework. This work also presents a parameterized hardware implementation of the said feature extraction and classification components while introducing a compiler that maps any arbitrary NN and/or classifier to the aforementioned hardware. The proposed hybrid machine learning model has the same level of accuracy (i.e. $\pm$1%) as NNs while achieving at least 10% improvement in accuracy compared to HD learning models. Additionally, the end-to-end hardware realization of the hybrid model improves power efficiency by 1.60x compared to state-of-the-art, high-performance HD learning implementations while improving latency by 2.13x. These results have profound implications for the application of such synergic models in challenging cognitive tasks.