 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByT5: Towards a token-free future with pre-trained byte-to-byte models
May 28, 2021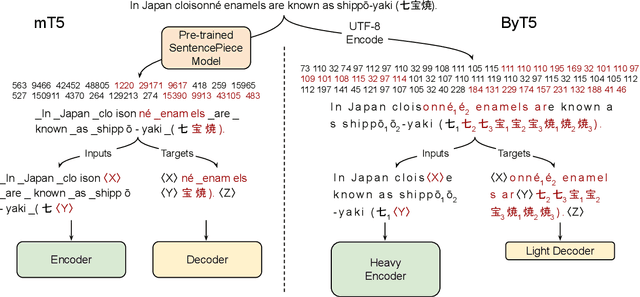
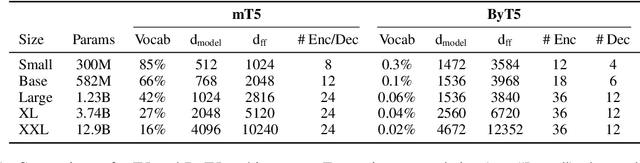
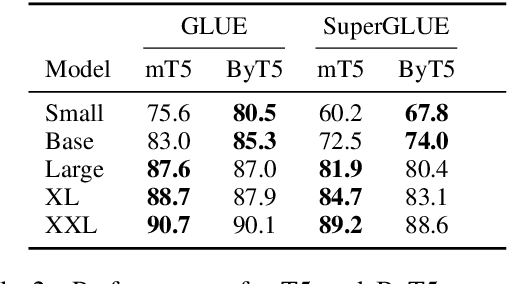
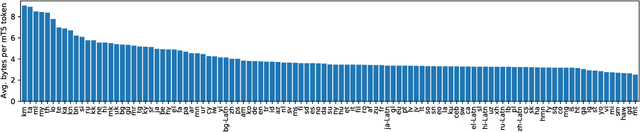
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
Do Transformer Modifications Transfer Across Implementations and Applications?
Feb 23, 2021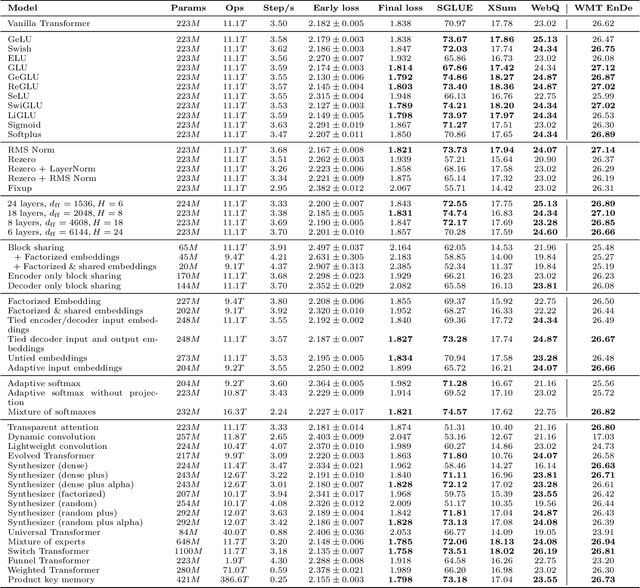
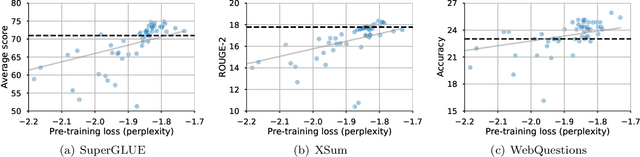
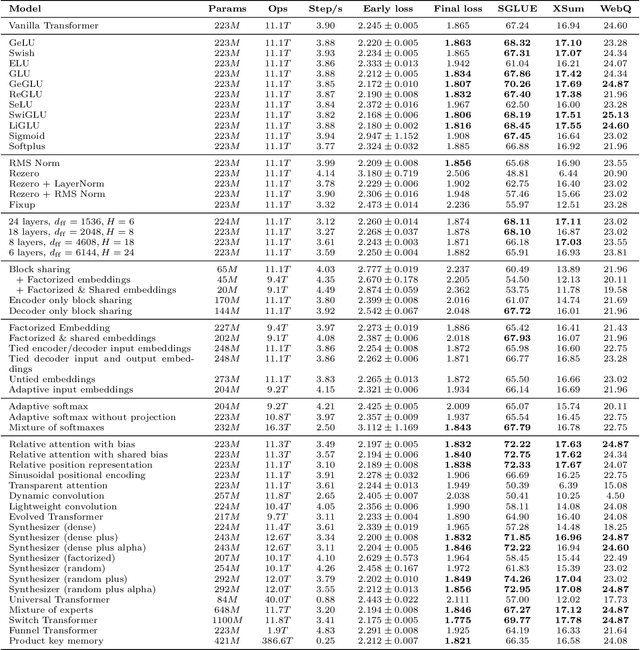
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
On Task-Level Dialogue Composition of Generative Transformer Model
Oct 09, 2020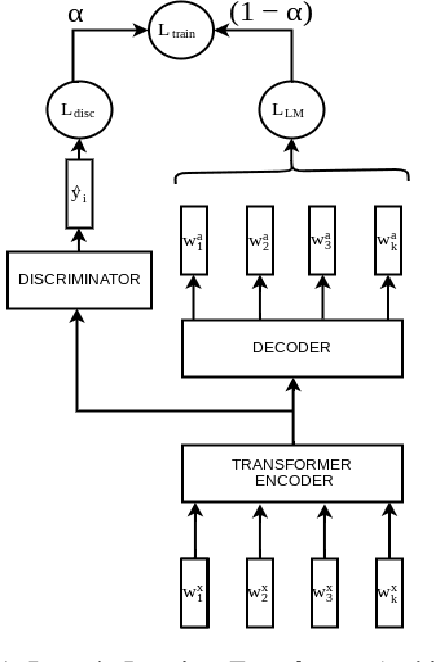
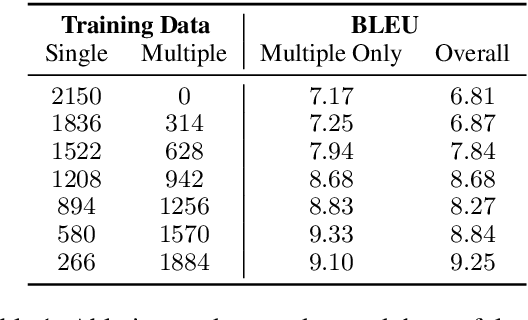
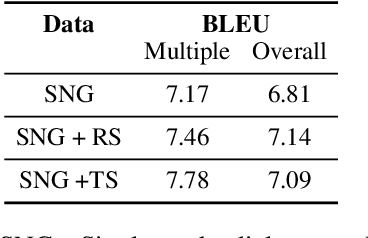

Task-oriented dialogue systems help users accomplish tasks such as booking a movie ticket and ordering food via conversation. Generative models parameterized by a deep neural network are widely used for next turn response generation in such systems. It is natural for users of the system to want to accomplish multiple tasks within the same conversation, but the ability of generative models to compose multiple tasks is not well studied. In this work, we begin by studying the effect of training human-human task-oriented dialogues towards improving the ability to compose multiple tasks on Transformer generative models. To that end, we propose and explore two solutions: (1) creating synthetic multiple task dialogue data for training from human-human single task dialogue and (2) forcing the encoder representation to be invariant to single and multiple task dialogues using an auxiliary loss. The results from our experiments highlight the difficulty of even the sophisticated variant of transformer model in learning to compose multiple tasks from single task dialogues.
WT5?! Training Text-to-Text Models to Explain their Predictions
Apr 30, 2020
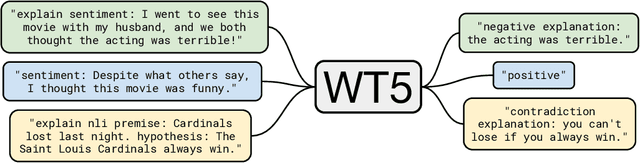

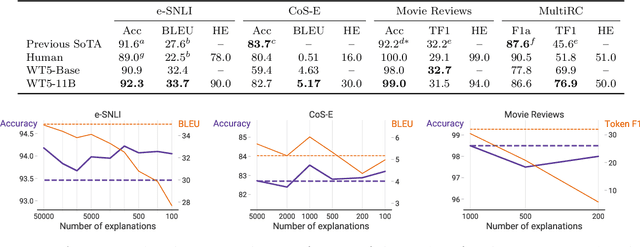
Neural networks have recently achieved human-level performance on various challenging natural language processing (NLP) tasks, but it is notoriously difficult to understand why a neural network produced a particular prediction. In this paper, we leverage the text-to-text framework proposed by Raffel et al.(2019) to train language models to output a natural text explanation alongside their prediction. Crucially, this requires no modifications to the loss function or training and decoding procedures -- we simply train the model to output the explanation after generating the (natural text) prediction. We show that this approach not only obtains state-of-the-art results on explainability benchmarks, but also permits learning from a limited set of labeled explanations and transferring rationalization abilities across datasets. To facilitate reproducibility and future work, we release our code use to train the models.
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
Oct 31, 2019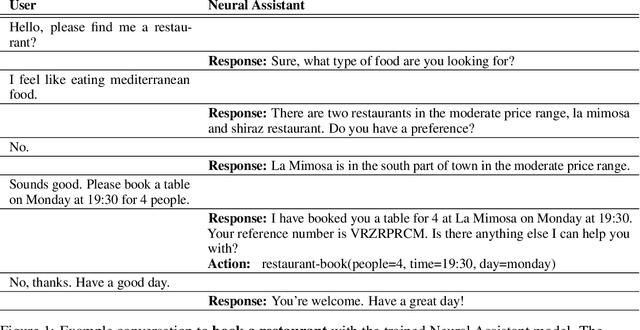
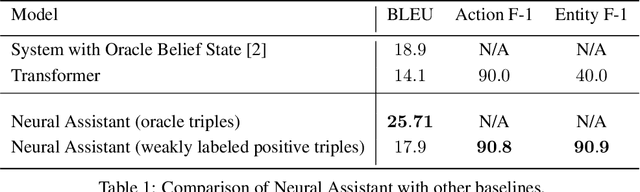
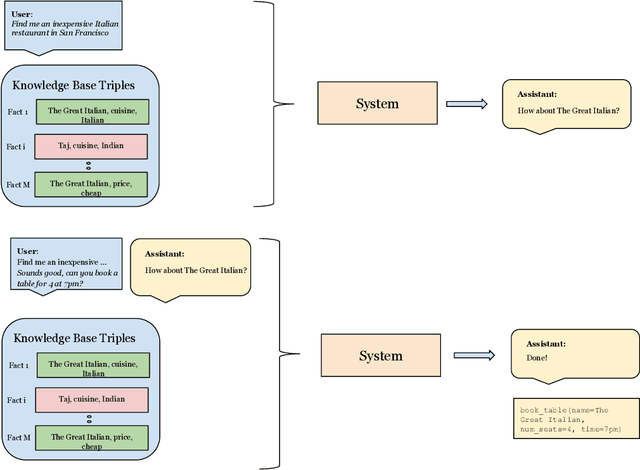
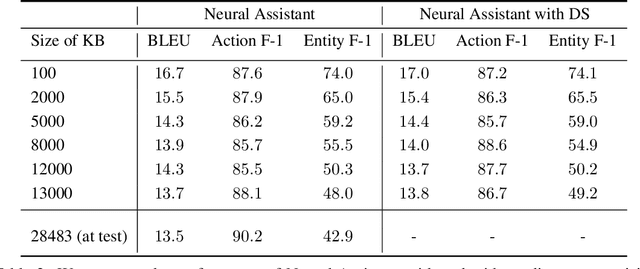
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction. Modern dialog systems typically begin by converting conversation history to a symbolic object referred to as belief state by using supervised learning. The belief state is then used to reason on an external knowledge source whose result along with the conversation history is used in action prediction and response generation tasks independently. Such a pipeline of individually optimized components not only makes the development process cumbersome but also makes it non-trivial to leverage session-level user reinforcement signals. In this paper, we develop Neural Assistant: a single neural network model that takes conversation history and an external knowledge source as input and jointly produces both text response and action to be taken by the system as output. The model learns to reason on the provided knowledge source with weak supervision signal coming from the text generation and the action prediction tasks, hence removing the need for belief state annotations. In the MultiWOZ dataset, we study the effect of distant supervision, and the size of knowledge base on model performance. We find that the Neural Assistant without belief states is able to incorporate external knowledge information achieving higher factual accuracy scores compared to Transformer. In settings comparable to reported baseline systems, Neural Assistant when provided with oracle belief state significantly improves language generation performance.
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Oct 24, 2019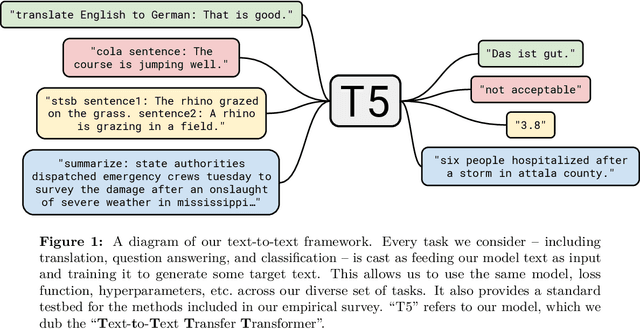
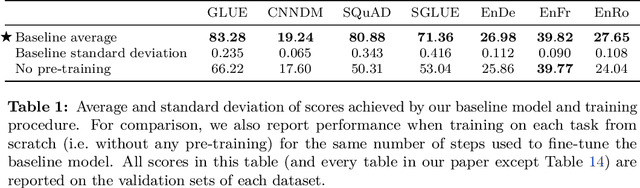

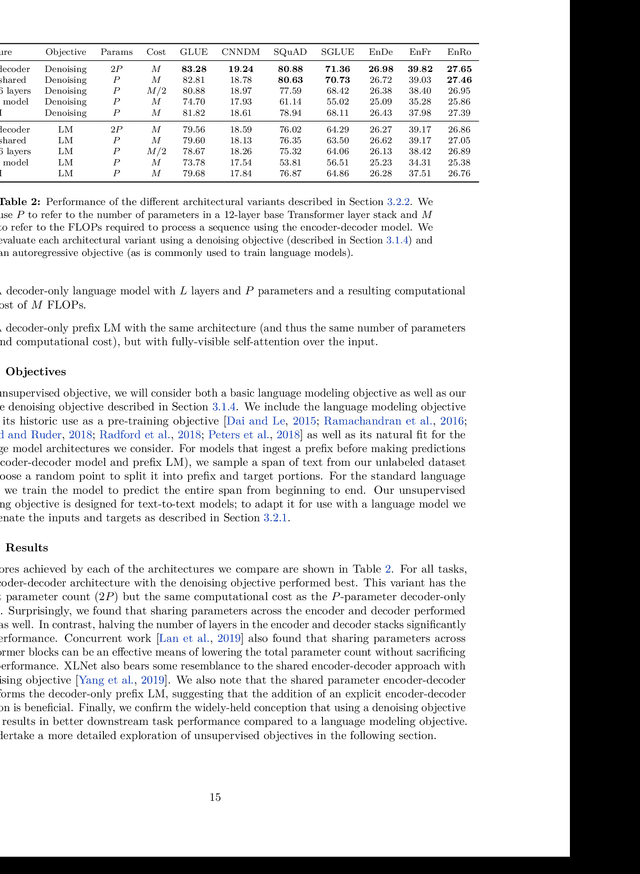
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new "Colossal Clean Crawled Corpus", we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.
Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning
Feb 22, 2018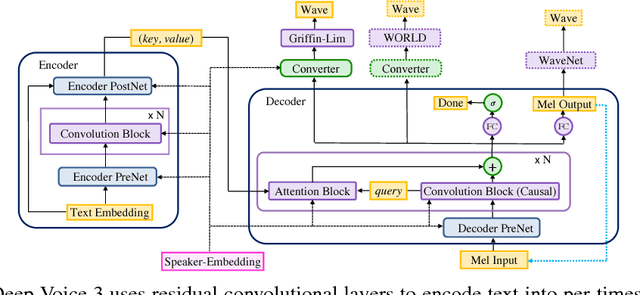

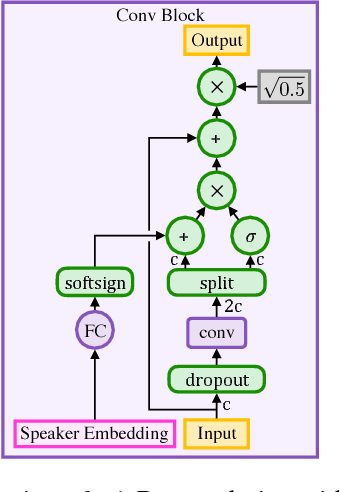
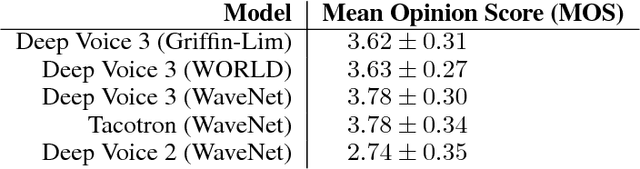
We present Deep Voice 3, a fully-convolutional attention-based neural text-to-speech (TTS) system. Deep Voice 3 matches state-of-the-art neural speech synthesis systems in naturalness while training ten times faster. We scale Deep Voice 3 to data set sizes unprecedented for TTS, training on more than eight hundred hours of audio from over two thousand speakers. In addition, we identify common error modes of attention-based speech synthesis networks, demonstrate how to mitigate them, and compare several different waveform synthesis methods. We also describe how to scale inference to ten million queries per day on one single-GPU server.
Mixed Precision Training
Feb 15, 2018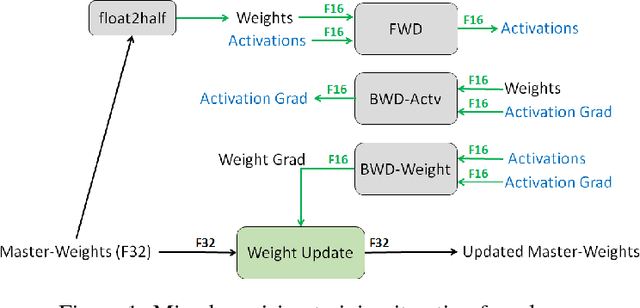
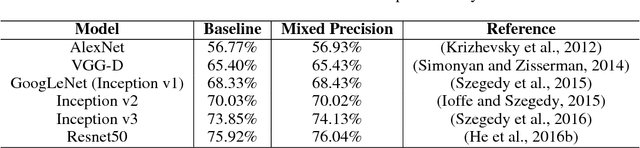
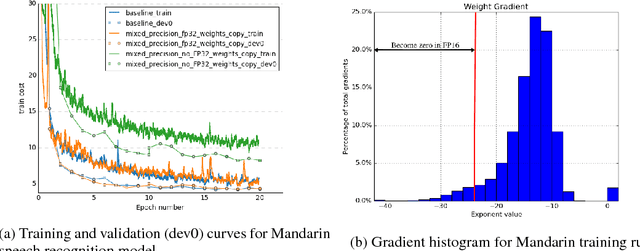

Deep neural networks have enabled progress in a wide variety of applications. Growing the size of the neural network typically results in improved accuracy. As model sizes grow, the memory and compute requirements for training these models also increases. We introduce a technique to train deep neural networks using half precision floating point numbers. In our technique, weights, activations and gradients are stored in IEEE half-precision format. Half-precision floating numbers have limited numerical range compared to single-precision numbers. We propose two techniques to handle this loss of information. Firstly, we recommend maintaining a single-precision copy of the weights that accumulates the gradients after each optimizer step. This single-precision copy is rounded to half-precision format during training. Secondly, we propose scaling the loss appropriately to handle the loss of information with half-precision gradients. We demonstrate that this approach works for a wide variety of models including convolution neural networks, recurrent neural networks and generative adversarial networks. This technique works for large scale models with more than 100 million parameters trained on large datasets. Using this approach, we can reduce the memory consumption of deep learning models by nearly 2x. In future processors, we can also expect a significant computation speedup using half-precision hardware units.
Deep Learning Scaling is Predictable, Empirically
Dec 01, 2017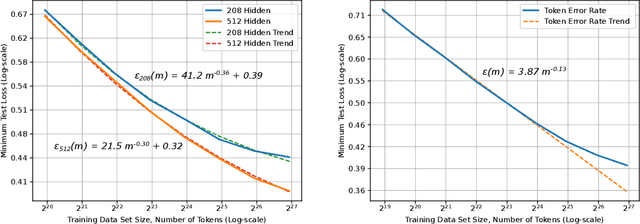
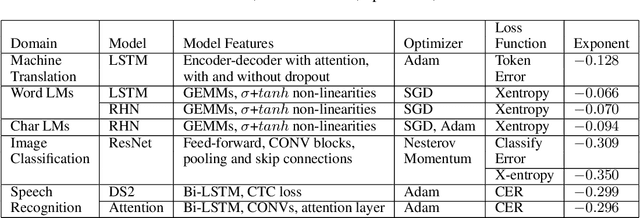
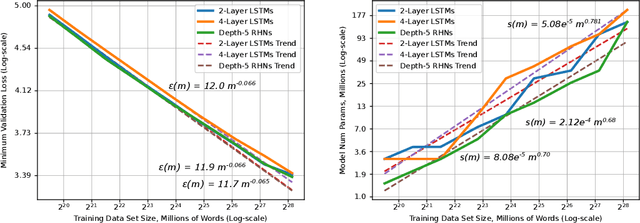
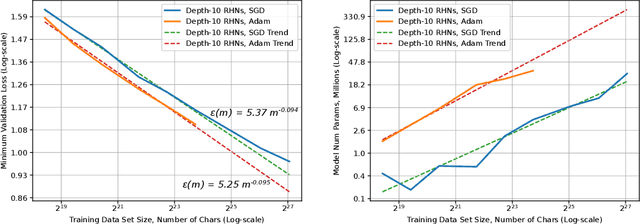
Deep learning (DL) creates impactful advances following a virtuous recipe: model architecture search, creating large training data sets, and scaling computation. It is widely believed that growing training sets and models should improve accuracy and result in better products. As DL application domains grow, we would like a deeper understanding of the relationships between training set size, computational scale, and model accuracy improvements to advance the state-of-the-art. This paper presents a large scale empirical characterization of generalization error and model size growth as training sets grow. We introduce a methodology for this measurement and test four machine learning domains: machine translation, language modeling, image processing, and speech recognition. Our empirical results show power-law generalization error scaling across a breadth of factors, resulting in power-law exponents---the "steepness" of the learning curve---yet to be explained by theoretical work. Further, model improvements only shift the error but do not appear to affect the power-law exponent. We also show that model size scales sublinearly with data size. These scaling relationships have significant implications on deep learning research, practice, and systems. They can assist model debugging, setting accuracy targets, and decisions about data set growth. They can also guide computing system design and underscore the importance of continued computational scaling.
Block-Sparse Recurrent Neural Networks
Nov 08, 2017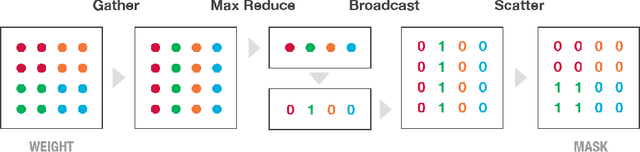
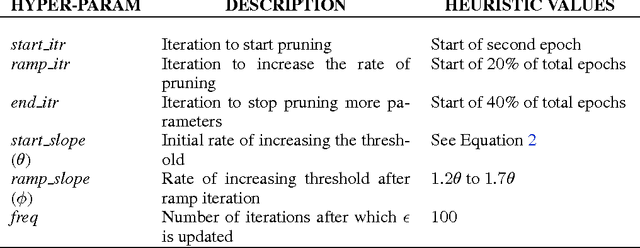
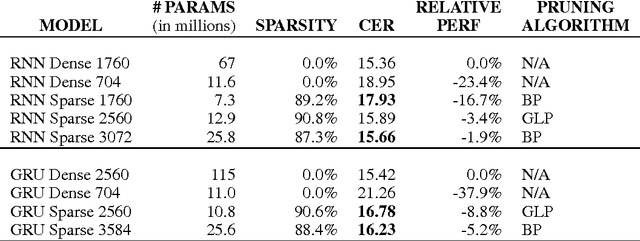
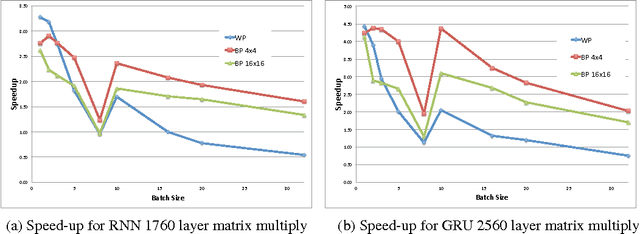
Recurrent Neural Networks (RNNs) are used in state-of-the-art models in domains such as speech recognition, machine translation, and language modelling. Sparsity is a technique to reduce compute and memory requirements of deep learning models. Sparse RNNs are easier to deploy on devices and high-end server processors. Even though sparse operations need less compute and memory relative to their dense counterparts, the speed-up observed by using sparse operations is less than expected on different hardware platforms. In order to address this issue, we investigate two different approaches to induce block sparsity in RNNs: pruning blocks of weights in a layer and using group lasso regularization to create blocks of weights with zeros. Using these techniques, we demonstrate that we can create block-sparse RNNs with sparsity ranging from 80% to 90% with small loss in accuracy. This allows us to reduce the model size by roughly 10x. Additionally, we can prune a larger dense network to recover this loss in accuracy while maintaining high block sparsity and reducing the overall parameter count. Our technique works with a variety of block sizes up to 32x32. Block-sparse RNNs eliminate overheads related to data storage and irregular memory accesses while increasing hardware efficiency compared to unstructured sparsity.