 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllumination Robust Loop Closure Detection with the Constraint of Pose
Dec 27, 2019Background: Loop closure detection is a crucial part in robot navigation and simultaneous location and mapping (SLAM). Appearance-based loop closure detection still faces many challenges, such as illumination changes, perceptual aliasing and increasing computational complexity. Method: In this paper, we proposed a visual loop-closure detection algorithm which combines illumination robust descriptor DIRD and odometry information. The estimated pose and variance are calculated by the visual inertial odometry (VIO), then the loop closure candidate areas are found based on the distance between images. We use a new distance combing the the Euclidean distance and the Mahalanobis distance and a dynamic threshold to select the loop closure candidate areas. Finally, in loop-closure candidate areas, we do image retrieval with DIRD which is an illumination robust descriptor. Results: The proposed algorithm is evaluated on KITTI_00 and EuRoc datasets. The results show that the loop closure areas could be correctly detected and the time consumption is effectively reduced. We compare it with SeqSLAM algorithm, the proposed algorithm gets better performance on PR-curve.
Invariant Cubature Kalman Filter for Monocular Visual Inertial Odometry with Line Features
Dec 26, 2019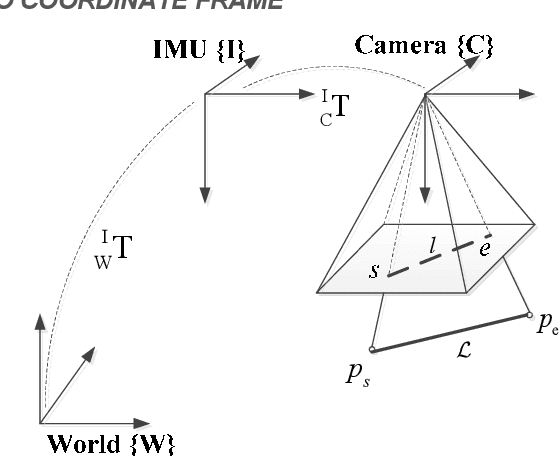

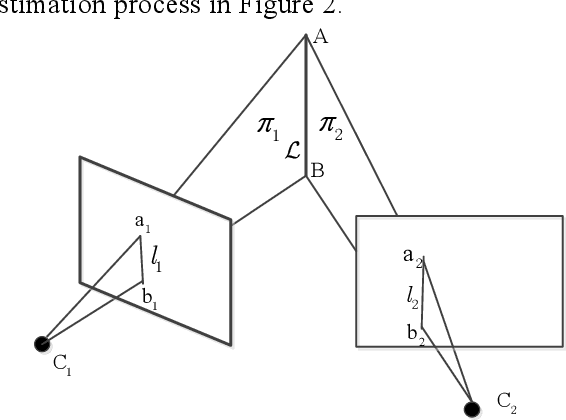
To achieve robust and accurate state estimation for robot navigation, we propose a novel Visual Inertial Odometry(VIO) algorithm with line features upon the theory of invariant Kalman filtering and Cubature Kalman Filter (CKF). In contrast with conventional CKF, the state of the filter is constructed by a high dimensional Matrix Lie group and the uncertainty is represented using Lie algebra. To improve the robustness of system in challenging scenes, e.g. low-texture or illumination changing environments, line features are brought into the state variable. In the proposed algorithm, exponential mapping of Lie algebra is used to construct the cubature points and the re-projection errors of lines are built as observation function for updating the state. This method accurately describes the system uncertainty in rotation and reduces the linearization error of system, which extends traditional CKF from Euclidean space to manifold. It not only inherits the advantages of invariant filtering in consistency, but also avoids the complex Jacobian calculation of high-dimensional matrix. To demonstrate the effectiveness of the proposed algorithm, we compare it with the state-of-the-art filtering-based VIO algorithms on Euroc datasets. And the results show that the proposed algorithm is effective in improving accuracy and robustness of estimation.
RoboCoDraw: Robotic Avatar Drawing with GAN-based Style Transfer and Time-efficient Path Optimization
Dec 11, 2019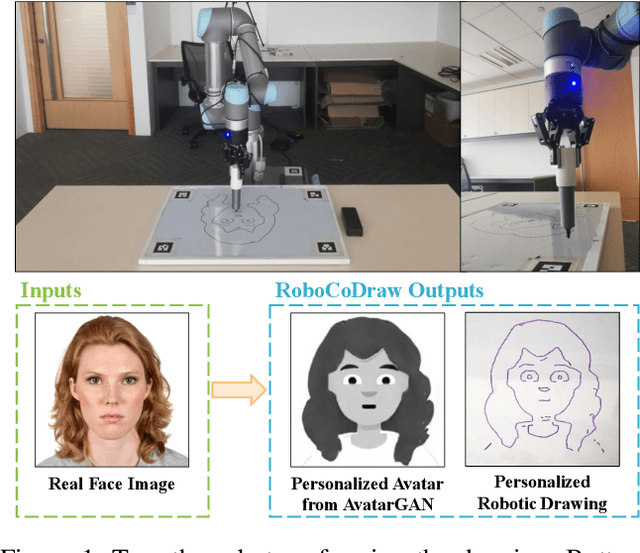
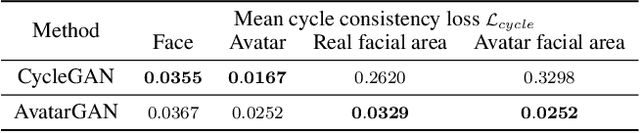

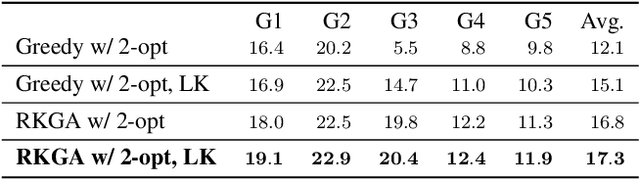
Robotic drawing has become increasingly popular as an entertainment and interactive tool. In this paper we present RoboCoDraw, a real-time collaborative robot-based drawing system that draws stylized human face sketches interactively in front of human users, by using the Generative Adversarial Network (GAN)-based style transfer and a Random-Key Genetic Algorithm (RKGA)-based path optimization. The proposed RoboCoDraw system takes a real human face image as input, converts it to a stylized avatar, then draws it with a robotic arm. A core component in this system is the Avatar-GAN proposed by us, which generates a cartoon avatar face image from a real human face. AvatarGAN is trained with unpaired face and avatar images only and can generate avatar images of much better likeness with human face images in comparison with the vanilla CycleGAN. After the avatar image is generated, it is fed to a line extraction algorithm and converted to sketches. An RKGA-based path optimization algorithm is applied to find a time-efficient robotic drawing path to be executed by the robotic arm. We demonstrate the capability of RoboCoDraw on various face images using a lightweight, safe collaborative robot UR5.
Multi-Instance Multi-Scale CNN for Medical Image Classification
Jul 31, 2019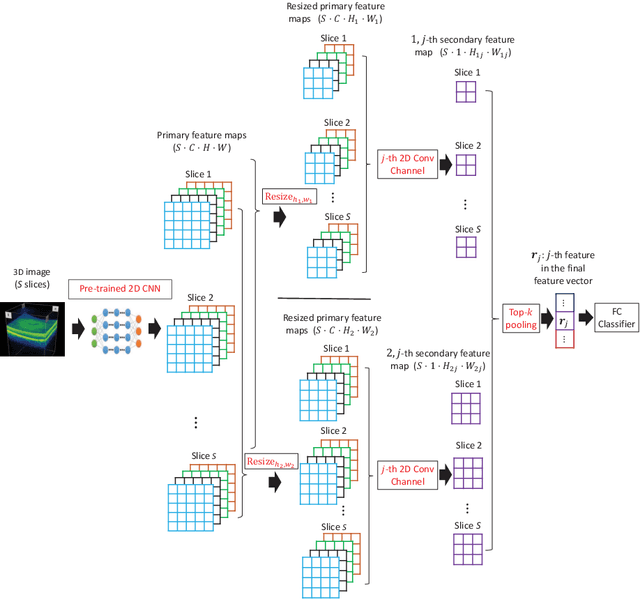
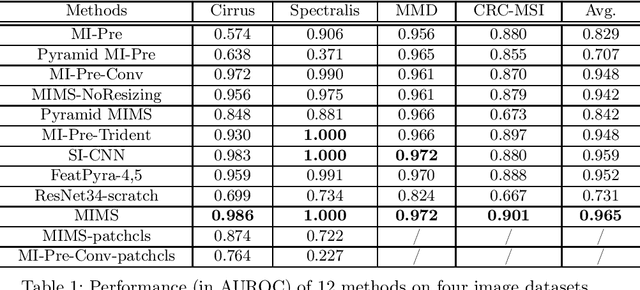
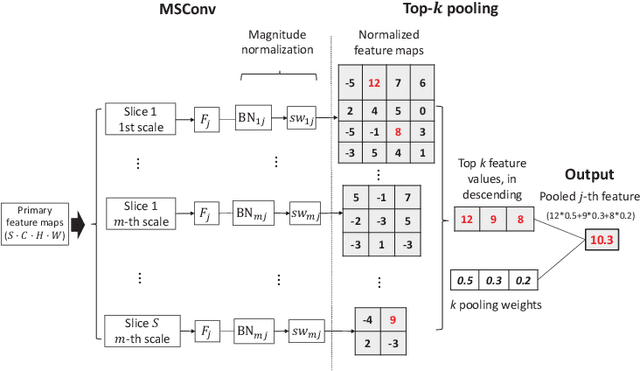

Deep learning for medical image classification faces three major challenges: 1) the number of annotated medical images for training are usually small; 2) regions of interest (ROIs) are relatively small with unclear boundaries in the whole medical images, and may appear in arbitrary positions across the x,y (and also z in 3D images) dimensions. However often only labels of the whole images are annotated, and localized ROIs are unavailable; and 3) ROIs in medical images often appear in varying sizes (scales). We approach these three challenges with a Multi-Instance Multi-Scale (MIMS) CNN: 1) We propose a multi-scale convolutional layer, which extracts patterns of different receptive fields with a shared set of convolutional kernels, so that scale-invariant patterns are captured by this compact set of kernels. As this layer contains only a small number of parameters, training on small datasets becomes feasible; 2) We propose a "top-k pooling" to aggregate the feature maps in varying scales from multiple spatial dimensions, allowing the model to be trained using weak annotations within the multiple instance learning (MIL) framework. Our method is shown to perform well on three classification tasks involving two 3D and two 2D medical image datasets.
Fine-grained Attention-based Video Face Recognition
May 06, 2019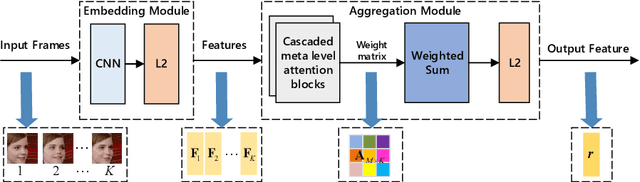
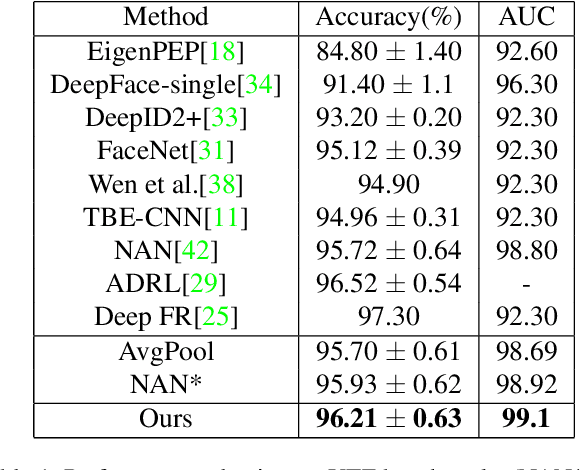
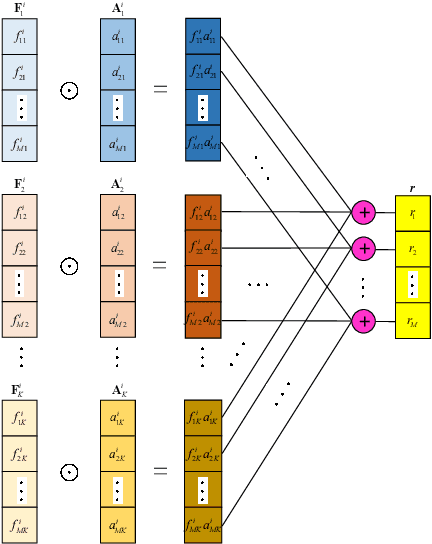
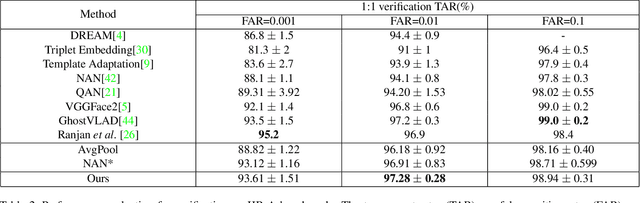
This paper aims to learn a compact representation of a video for video face recognition task. We make the following contributions: first, we propose a meta attention-based aggregation scheme which adaptively and fine-grained weighs the feature along each feature dimension among all frames to form a compact and discriminative representation. It makes the best to exploit the valuable or discriminative part of each frame to promote the performance of face recognition, without discarding or despising low quality frames as usual methods do. Second, we build a feature aggregation network comprised of a feature embedding module and a feature aggregation module. The embedding module is a convolutional neural network used to extract a feature vector from a face image, while the aggregation module consists of cascaded two meta attention blocks which adaptively aggregate the feature vectors into a single fixed-length representation. The network can deal with arbitrary number of frames, and is insensitive to frame order. Third, we validate the performance of proposed aggregation scheme. Experiments on publicly available datasets, such as YouTube face dataset and IJB-A dataset, show the effectiveness of our method, and it achieves competitive performances on both the verification and identification protocols.
Deep Learning-based Face Pose Recovery
Apr 30, 2019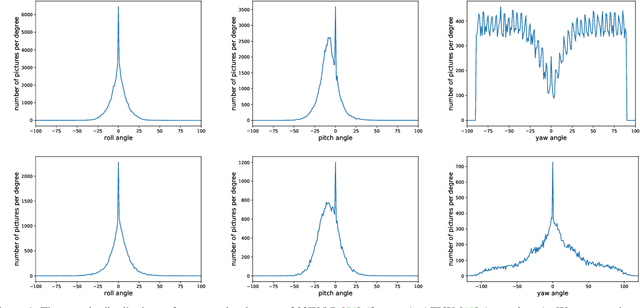
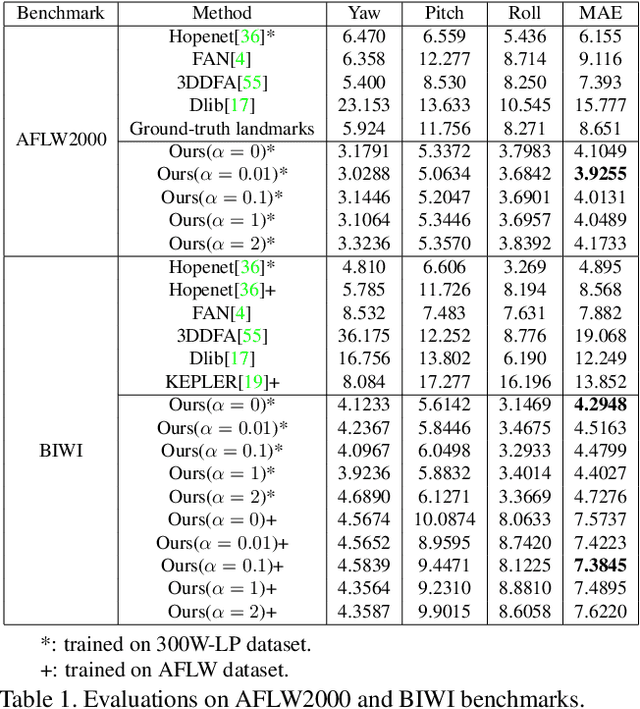
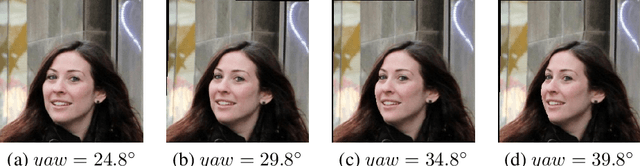
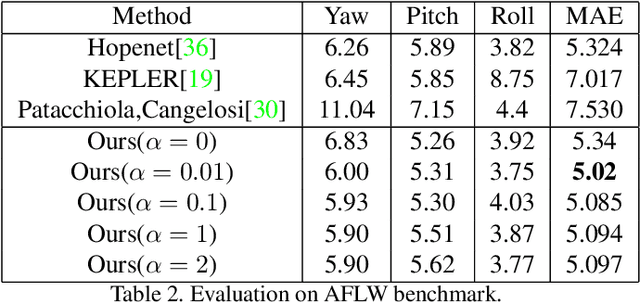
Facial pose estimation has gained a lot of attentions in many practical applications, such as human-robot interaction, gaze estimation and driver monitoring. Meanwhile, end-to-end deep learning-based facial pose estimation is becoming more and more popular. However, facial pose estimation suffers from a key challenge: the lack of sufficient training data for many poses, especially for large poses. Inspired by the observation that the faces under close poses look similar, we reformulate the facial pose estimation as a label distribution learning problem, considering each face image as an example associated with a Gaussian label distribution rather than a single label, and construct a convolutional neural network which is trained with a multi-loss function on AFLW dataset and 300WLP dataset to predict the facial poses directly from color image. Extensive experiments are conducted on several popular benchmarks, including AFLW2000, BIWI, AFLW and AFW, where our approach shows a significant advantage over other state-of-the-art methods.
Enhanced Attacks on Defensively Distilled Deep Neural Networks
Nov 16, 2017


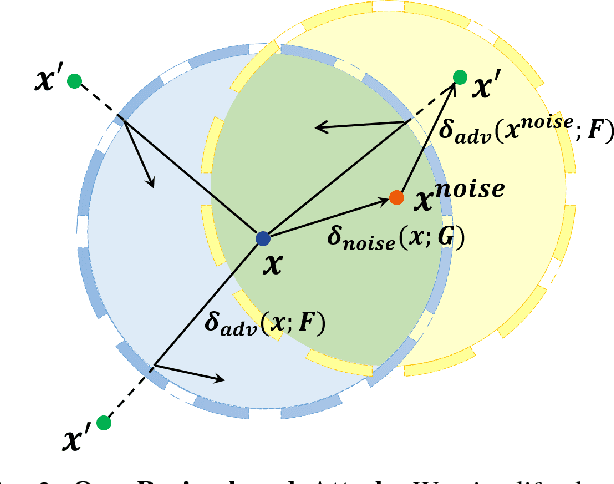
Deep neural networks (DNNs) have achieved tremendous success in many tasks of machine learning, such as the image classification. Unfortunately, researchers have shown that DNNs are easily attacked by adversarial examples, slightly perturbed images which can mislead DNNs to give incorrect classification results. Such attack has seriously hampered the deployment of DNN systems in areas where security or safety requirements are strict, such as autonomous cars, face recognition, malware detection. Defensive distillation is a mechanism aimed at training a robust DNN which significantly reduces the effectiveness of adversarial examples generation. However, the state-of-the-art attack can be successful on distilled networks with 100% probability. But it is a white-box attack which needs to know the inner information of DNN. Whereas, the black-box scenario is more general. In this paper, we first propose the epsilon-neighborhood attack, which can fool the defensively distilled networks with 100% success rate in the white-box setting, and it is fast to generate adversarial examples with good visual quality. On the basis of this attack, we further propose the region-based attack against defensively distilled DNNs in the black-box setting. And we also perform the bypass attack to indirectly break the distillation defense as a complementary method. The experimental results show that our black-box attacks have a considerable success rate on defensively distilled networks.
Laplacian-Steered Neural Style Transfer
Jul 30, 2017
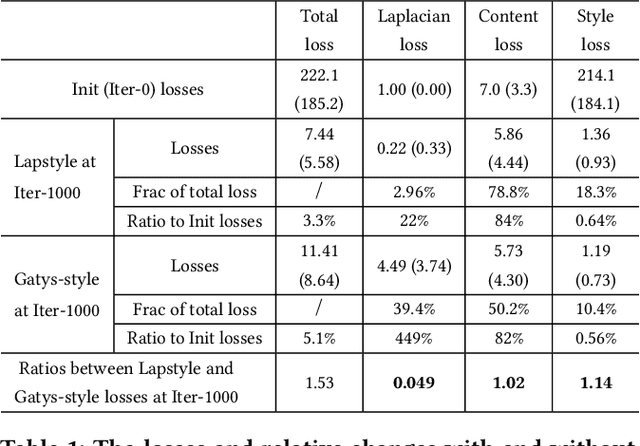

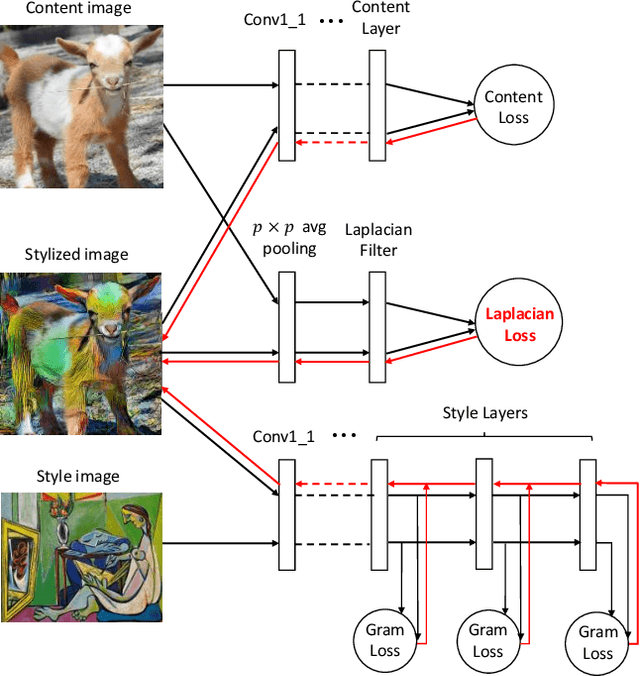
Neural Style Transfer based on Convolutional Neural Networks (CNN) aims to synthesize a new image that retains the high-level structure of a content image, rendered in the low-level texture of a style image. This is achieved by constraining the new image to have high-level CNN features similar to the content image, and lower-level CNN features similar to the style image. However in the traditional optimization objective, low-level features of the content image are absent, and the low-level features of the style image dominate the low-level detail structures of the new image. Hence in the synthesized image, many details of the content image are lost, and a lot of inconsistent and unpleasing artifacts appear. As a remedy, we propose to steer image synthesis with a novel loss function: the Laplacian loss. The Laplacian matrix ("Laplacian" in short), produced by a Laplacian operator, is widely used in computer vision to detect edges and contours. The Laplacian loss measures the difference of the Laplacians, and correspondingly the difference of the detail structures, between the content image and a new image. It is flexible and compatible with the traditional style transfer constraints. By incorporating the Laplacian loss, we obtain a new optimization objective for neural style transfer named Lapstyle. Minimizing this objective will produce a stylized image that better preserves the detail structures of the content image and eliminates the artifacts. Experiments show that Lapstyle produces more appealing stylized images with less artifacts, without compromising their "stylishness".
Dirichlet-vMF Mixture Model
Feb 24, 2017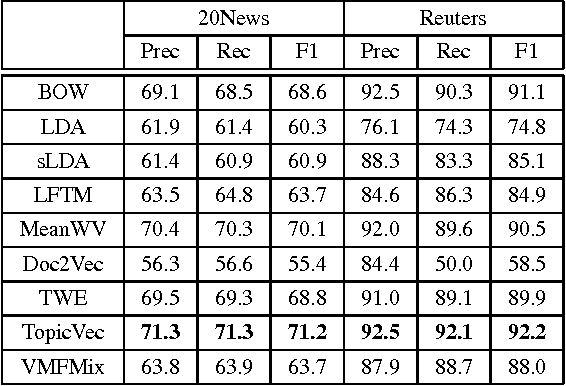
This document is about the multi-document Von-Mises-Fisher mixture model with a Dirichlet prior, referred to as VMFMix. VMFMix is analogous to Latent Dirichlet Allocation (LDA) in that they can capture the co-occurrence patterns acorss multiple documents. The difference is that in VMFMix, the topic-word distribution is defined on a continuous n-dimensional hypersphere. Hence VMFMix is used to derive topic embeddings, i.e., representative vectors, from multiple sets of embedding vectors. An efficient Variational Expectation-Maximization inference algorithm is derived. The performance of VMFMix on two document classification tasks is reported, with some preliminary analysis.
Generative Topic Embedding: a Continuous Representation of Documents (Extended Version with Proofs)
Aug 08, 2016
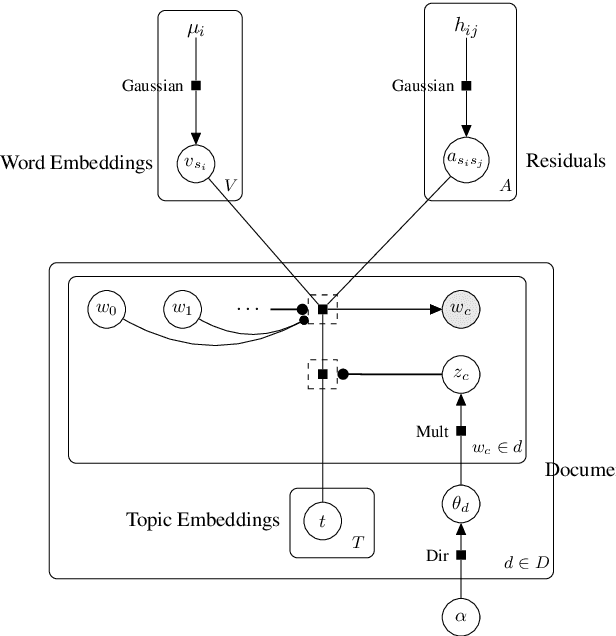
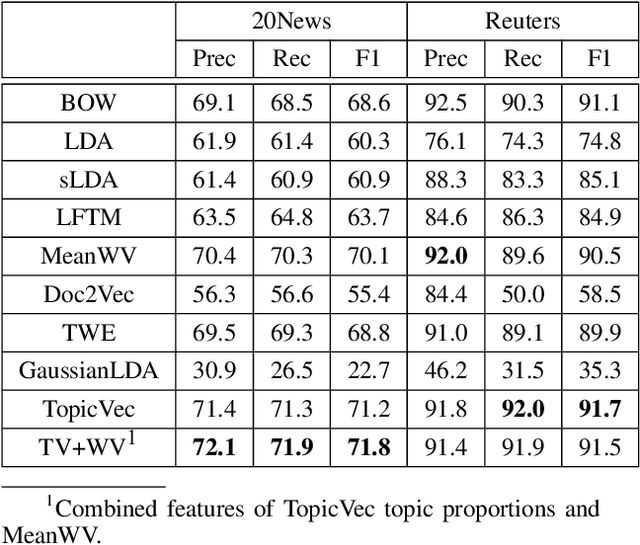
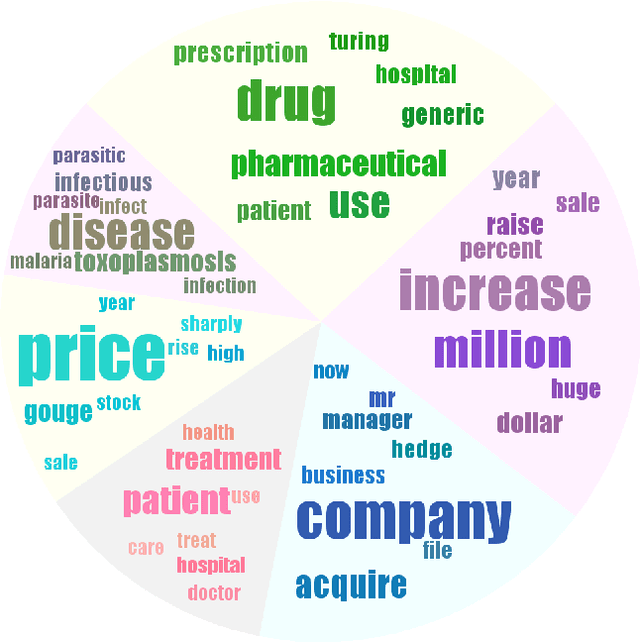
Word embedding maps words into a low-dimensional continuous embedding space by exploiting the local word collocation patterns in a small context window. On the other hand, topic modeling maps documents onto a low-dimensional topic space, by utilizing the global word collocation patterns in the same document. These two types of patterns are complementary. In this paper, we propose a generative topic embedding model to combine the two types of patterns. In our model, topics are represented by embedding vectors, and are shared across documents. The probability of each word is influenced by both its local context and its topic. A variational inference method yields the topic embeddings as well as the topic mixing proportions for each document. Jointly they represent the document in a low-dimensional continuous space. In two document classification tasks, our method performs better than eight existing methods, with fewer features. In addition, we illustrate with an example that our method can generate coherent topics even based on only one document.