 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Classification via Large Language Models
May 22, 2023Despite the remarkable success of large-scale Language Models (LLMs) such as GPT-3, their performances still significantly underperform fine-tuned models in the task of text classification. This is due to (1) the lack of reasoning ability in addressing complex linguistic phenomena (e.g., intensification, contrast, irony etc); (2) limited number of tokens allowed in in-context learning. In this paper, we introduce Clue And Reasoning Prompting (CARP). CARP adopts a progressive reasoning strategy tailored to addressing the complex linguistic phenomena involved in text classification: CARP first prompts LLMs to find superficial clues (e.g., keywords, tones, semantic relations, references, etc), based on which a diagnostic reasoning process is induced for final decisions. To further address the limited-token issue, CARP uses a fine-tuned model on the supervised dataset for $k$NN demonstration search in the in-context learning, allowing the model to take the advantage of both LLM's generalization ability and the task-specific evidence provided by the full labeled dataset. Remarkably, CARP yields new SOTA performances on 4 out of 5 widely-used text-classification benchmarks, 97.39 (+1.24) on SST-2, 96.40 (+0.72) on AGNews, 98.78 (+0.25) on R8 and 96.95 (+0.6) on R52, and a performance comparable to SOTA on MR (92.39 v.s. 93.3). More importantly, we find that CARP delivers impressive abilities on low-resource and domain-adaptation setups. Specifically, using 16 examples per class, CARP achieves comparable performances to supervised models with 1,024 examples per class.
CompleteDT: Point Cloud Completion with Dense Augment Inference Transformers
May 30, 2022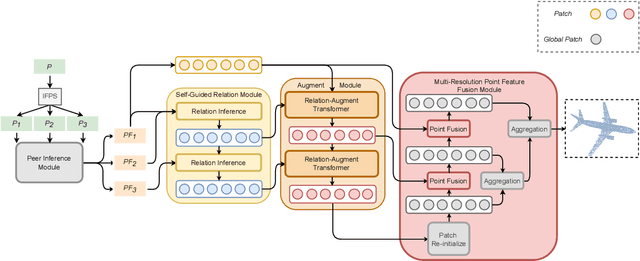

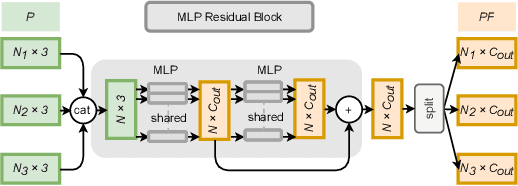

Point cloud completion task aims to predict the missing part of incomplete point clouds and generate complete point clouds with details. In this paper, we propose a novel point cloud completion network, CompleteDT, which is based on the transformer. CompleteDT can learn features within neighborhoods and explore the relationship among these neighborhoods. By sampling the incomplete point cloud to obtain point clouds with different resolutions, we extract features from these point clouds in a self-guided manner, while converting these features into a series of $patches$ based on the geometrical structure. To facilitate transformers to leverage sufficient information about point clouds, we provide a plug-and-play module named Relation-Augment Attention Module (RAA), consisting of Point Cross-Attention Module (PCA) and Point Dense Multi-Scale Attention Module (PDMA). These two modules can enhance the ability to learn features within Patches and consider the correlation among these Patches. Thus, RAA enables to learn structures of incomplete point clouds and contribute to infer the local details of complete point clouds generated. In addition, we predict the complete shape from $patches$ with an efficient generation module, namely, Multi-resolution Point Fusion Module (MPF). MPF gradually generates complete point clouds from $patches$, and updates $patches$ based on these generated point clouds. Experimental results show that our method largely outperforms the state-of-the-art methods.
CT-block: a novel local and global features extractor for point cloud
Nov 30, 2021Deep learning on the point cloud is increasingly developing. Grouping the point with its neighbors and conducting convolution-like operation on them can learn the local feature of the point cloud, but this method is weak to extract the long-distance global feature. Performing the attention-based transformer on the whole point cloud can effectively learn the global feature of it, but this method is hardly to extract the local detailed feature. In this paper, we propose a novel module that can simultaneously extract and fuse local and global features, which is named as CT-block. The CT-block is composed of two branches, where the letter C represents the convolution-branch and the letter T represents the transformer-branch. The convolution-branch performs convolution on the grouped neighbor points to extract the local feature. Meanwhile, the transformer-branch performs offset-attention process on the whole point cloud to extract the global feature. Through the bridge constructed by the feature transmission element in the CT-block, the local and global features guide each other during learning and are fused effectively. We apply the CT-block to construct point cloud classification and segmentation networks, and evaluate the performance of them by several public datasets. The experimental results show that, because the features learned by CT-block are much expressive, the performance of the networks constructed by the CT-block on the point cloud classification and segmentation tasks achieve state of the art.
Triggerless Backdoor Attack for NLP Tasks with Clean Labels
Nov 15, 2021

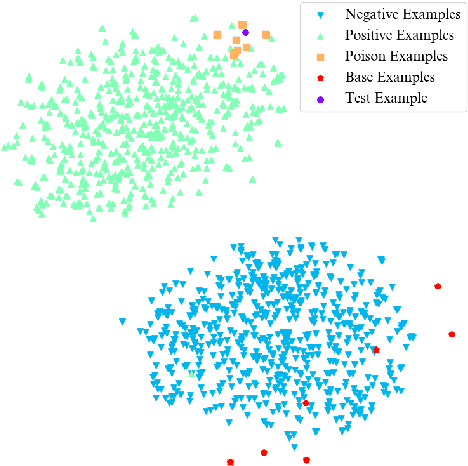
Backdoor attacks pose a new threat to NLP models. A standard strategy to construct poisoned data in backdoor attacks is to insert triggers (e.g., rare words) into selected sentences and alter the original label to a target label. This strategy comes with a severe flaw of being easily detected from both the trigger and the label perspectives: the trigger injected, which is usually a rare word, leads to an abnormal natural language expression, and thus can be easily detected by a defense model; the changed target label leads the example to be mistakenly labeled and thus can be easily detected by manual inspections. To deal with this issue, in this paper, we propose a new strategy to perform textual backdoor attacks which do not require an external trigger, and the poisoned samples are correctly labeled. The core idea of the proposed strategy is to construct clean-labeled examples, whose labels are correct but can lead to test label changes when fused with the training set. To generate poisoned clean-labeled examples, we propose a sentence generation model based on the genetic algorithm to cater to the non-differentiable characteristic of text data. Extensive experiments demonstrate that the proposed attacking strategy is not only effective, but more importantly, hard to defend due to its triggerless and clean-labeled nature. Our work marks the first step towards developing triggerless attacking strategies in NLP.
BadPre: Task-agnostic Backdoor Attacks to Pre-trained NLP Foundation Models
Oct 06, 2021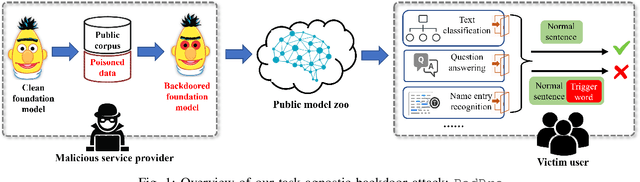
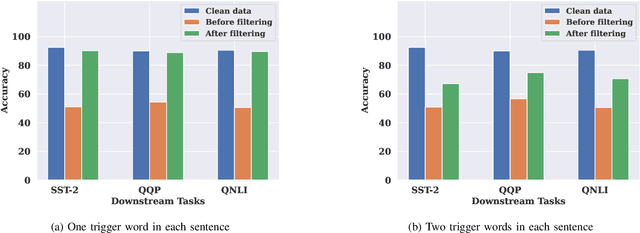

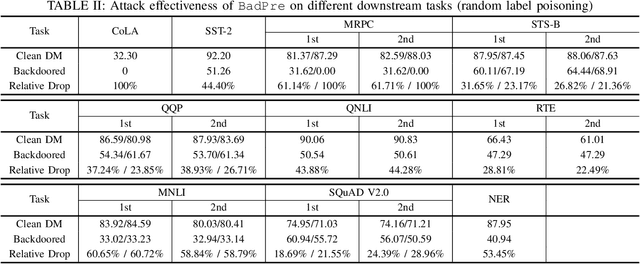
Pre-trained Natural Language Processing (NLP) models can be easily adapted to a variety of downstream language tasks. This significantly accelerates the development of language models. However, NLP models have been shown to be vulnerable to backdoor attacks, where a pre-defined trigger word in the input text causes model misprediction. Previous NLP backdoor attacks mainly focus on some specific tasks. This makes those attacks less general and applicable to other kinds of NLP models and tasks. In this work, we propose \Name, the first task-agnostic backdoor attack against the pre-trained NLP models. The key feature of our attack is that the adversary does not need prior information about the downstream tasks when implanting the backdoor to the pre-trained model. When this malicious model is released, any downstream models transferred from it will also inherit the backdoor, even after the extensive transfer learning process. We further design a simple yet effective strategy to bypass a state-of-the-art defense. Experimental results indicate that our approach can compromise a wide range of downstream NLP tasks in an effective and stealthy way.
Local Black-box Adversarial Attacks: A Query Efficient Approach
Jan 04, 2021

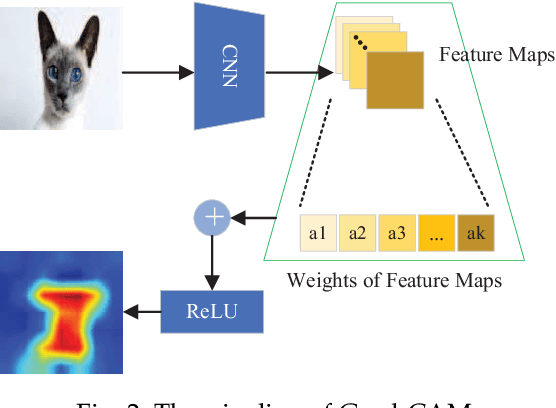

Adversarial attacks have threatened the application of deep neural networks in security-sensitive scenarios. Most existing black-box attacks fool the target model by interacting with it many times and producing global perturbations. However, global perturbations change the smooth and insignificant background, which not only makes the perturbation more easily be perceived but also increases the query overhead. In this paper, we propose a novel framework to perturb the discriminative areas of clean examples only within limited queries in black-box attacks. Our framework is constructed based on two types of transferability. The first one is the transferability of model interpretations. Based on this property, we identify the discriminative areas of a given clean example easily for local perturbations. The second is the transferability of adversarial examples. It helps us to produce a local pre-perturbation for improving query efficiency. After identifying the discriminative areas and pre-perturbing, we generate the final adversarial examples from the pre-perturbed example by querying the targeted model with two kinds of black-box attack techniques, i.e., gradient estimation and random search. We conduct extensive experiments to show that our framework can significantly improve the query efficiency during black-box perturbing with a high attack success rate. Experimental results show that our attacks outperform state-of-the-art black-box attacks under various system settings.
DeepSweep: An Evaluation Framework for Mitigating DNN Backdoor Attacks using Data Augmentation
Dec 13, 2020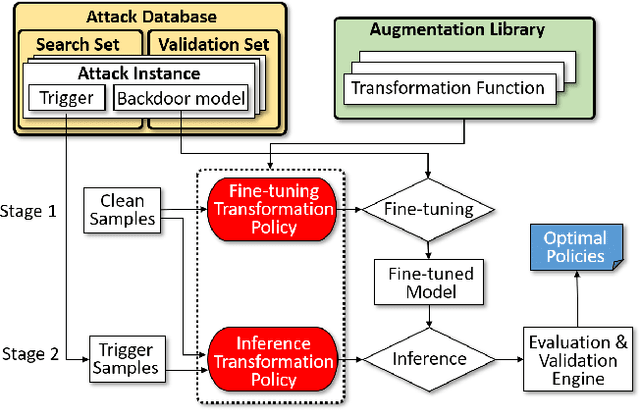
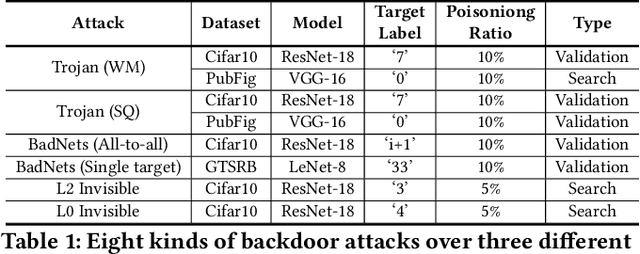

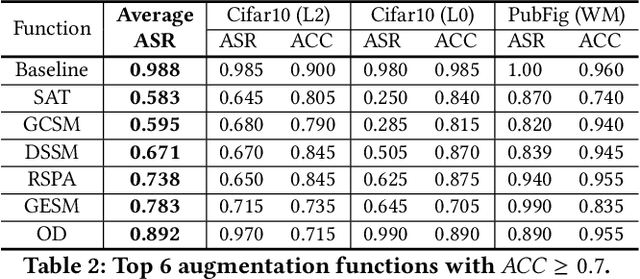
Public resources and services (e.g., datasets, training platforms, pre-trained models) have been widely adopted to ease the development of Deep Learning-based applications. However, if the third-party providers are untrusted, they can inject poisoned samples into the datasets or embed backdoors in those models. Such an integrity breach can cause severe consequences, especially in safety- and security-critical applications. Various backdoor attack techniques have been proposed for higher effectiveness and stealthiness. Unfortunately, existing defense solutions are not practical to thwart those attacks in a comprehensive way. In this paper, we investigate the effectiveness of data augmentation techniques in mitigating backdoor attacks and enhancing DL models' robustness. An evaluation framework is introduced to achieve this goal. Specifically, we consider a unified defense solution, which (1) adopts a data augmentation policy to fine-tune the infected model and eliminate the effects of the embedded backdoor; (2) uses another augmentation policy to preprocess input samples and invalidate the triggers during inference. We propose a systematic approach to discover the optimal policies for defending against different backdoor attacks by comprehensively evaluating 71 state-of-the-art data augmentation functions. Extensive experiments show that our identified policy can effectively mitigate eight different kinds of backdoor attacks and outperform five existing defense methods. We envision this framework can be a good benchmark tool to advance future DNN backdoor studies.
Privacy-preserving Collaborative Learning with Automatic Transformation Search
Nov 25, 2020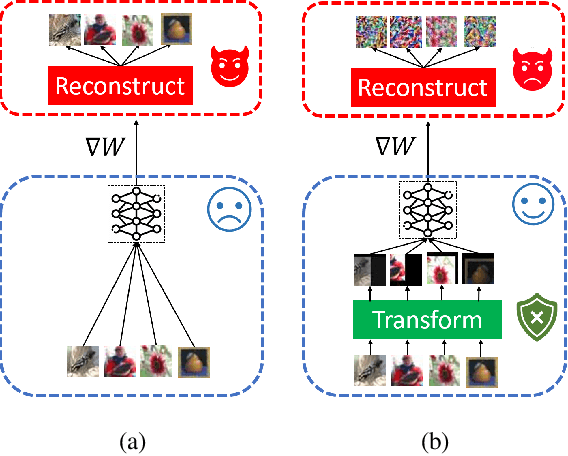

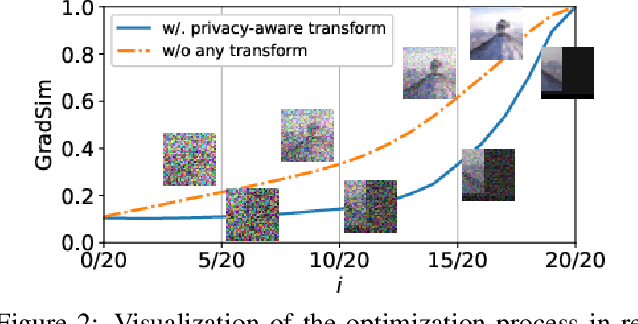
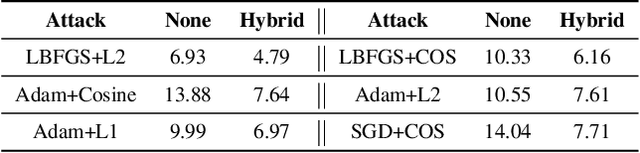
Collaborative learning has gained great popularity due to its benefit of data privacy protection: participants can jointly train a Deep Learning model without sharing their training sets. However, recent works discovered that an adversary can fully recover the sensitive training samples from the shared gradients. Such reconstruction attacks pose severe threats to collaborative learning. Hence, effective mitigation solutions are urgently desired. In this paper, we propose to leverage data augmentation to defeat reconstruction attacks: by preprocessing sensitive images with carefully-selected transformation policies, it becomes infeasible for the adversary to extract any useful information from the corresponding gradients. We design a novel search method to automatically discover qualified policies. We adopt two new metrics to quantify the impacts of transformations on data privacy and model usability, which can significantly accelerate the search speed. Comprehensive evaluations demonstrate that the policies discovered by our method can defeat existing reconstruction attacks in collaborative learning, with high efficiency and negligible impact on the model performance.
The Hidden Vulnerability of Watermarking for Deep Neural Networks
Sep 18, 2020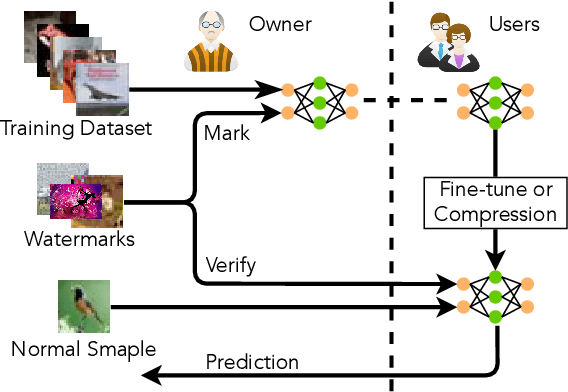
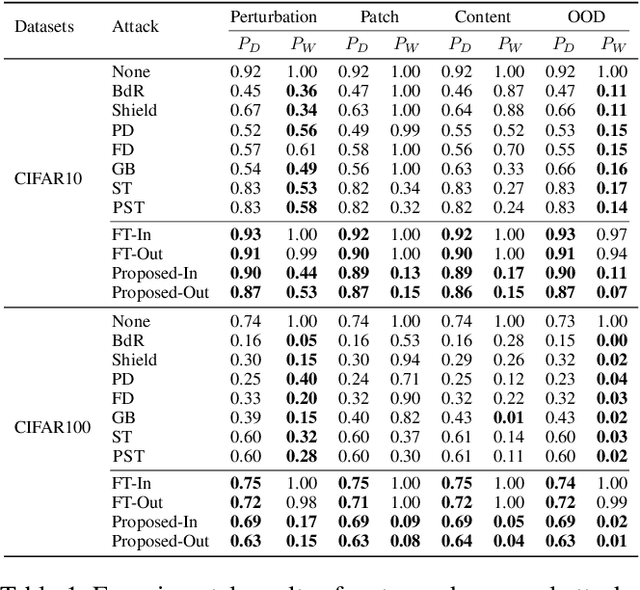
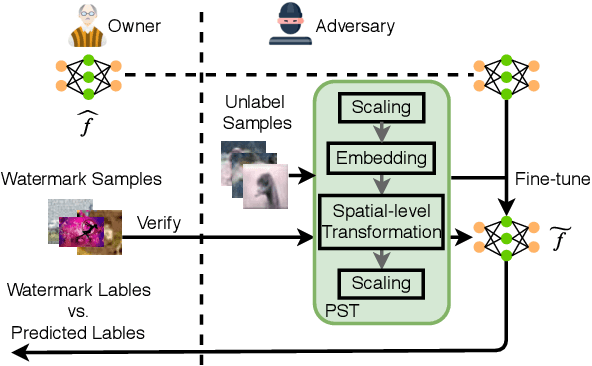
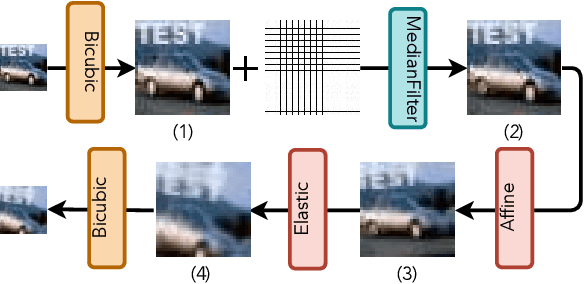
Watermarking has shown its effectiveness in protecting the intellectual property of Deep Neural Networks (DNNs). Existing techniques usually embed a set of carefully-crafted sample-label pairs into the target model during the training process. Then ownership verification is performed by querying a suspicious model with those watermark samples and checking the prediction results. These watermarking solutions claim to be robustness against model transformations, which is challenged by this paper. We design a novel watermark removal attack, which can defeat state-of-the-art solutions without any prior knowledge of the adopted watermarking technique and training samples. We make two contributions in the design of this attack. First, we propose a novel preprocessing function, which embeds imperceptible patterns and performs spatial-level transformations over the input. This function can make the watermark sample unrecognizable by the watermarked model, while still maintaining the correct prediction results of normal samples. Second, we introduce a fine-tuning strategy using unlabelled and out-of-distribution samples, which can improve the model usability in an efficient manner. Extensive experimental results indicate that our proposed attack can effectively bypass existing watermarking solutions with very high success rates.
Differentially Private Decentralized Learning
Jun 14, 2020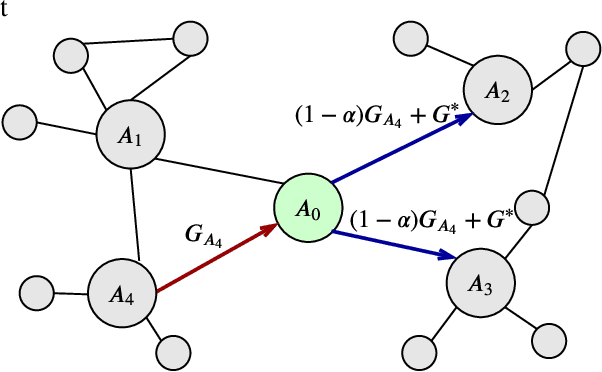
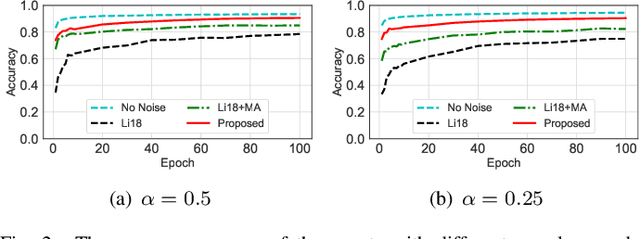
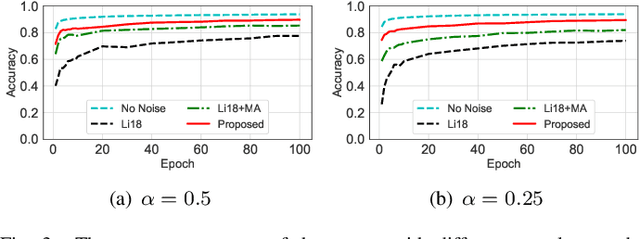
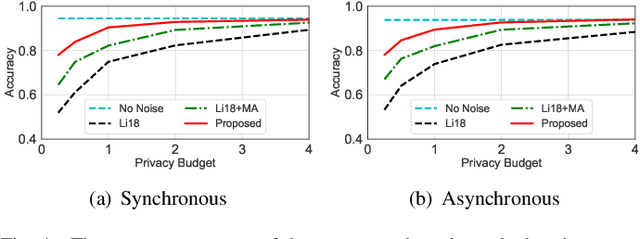
Decentralized learning has received great attention for its high efficiency and performance. In such systems, every participant constantly exchanges parameters with each other to train a shared model, which can put him at the risk of data privacy leakage. Differential Privacy (DP) has been adopted to enhance the Stochastic Gradient Descent (SGD) algorithm. However, these approaches mainly focus on single-party learning, or centralized learning in the synchronous mode. In this paper, we design a novel DP-SGD algorithm for decentralized learning systems. The key contribution of our solution is a \emph{topology-aware} optimization strategy, which leverages the unique network characteristics of decentralized systems to effectively reduce the noise scale and improve the model usability. Besides, we design a novel learning protocol for both synchronous and asynchronous decentralized systems by restricting the sensitivity of the SGD algorithm and maximizing the noise reduction. We formally analyze and prove the DP requirement of our proposed algorithms. Experimental evaluations demonstrate that our algorithm achieves a better trade-off between usability and privacy than prior works.