 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Ready For An Agent-Native Memory System?
Jun 23, 2026Memory for large language model (LLM) agents has rapidly evolved from simple retrieval-augmented mechanisms into a data management system that supports persistent information storage, retrieval, update, consolidation, and dynamic lifecycle governance throughout agent execution. Despite this evolution, existing evaluations still benchmark agent memory mainly through end-to-end task success metrics (e.g., F1, BLEU), while treating the underlying system as a monolithic black box. As a result, critical system-level concerns, including operational costs, architectural trade-offs across memory modules, and robustness under dynamic knowledge updates, remain insufficiently explored. In this paper, we present a systematic experimental study of agent memory from a data management perspective. We propose an analytical framework that decomposes agent memory into four core modules: memory representation and storage, extraction, retrieval and routing, and maintenance. Under this framework, we evaluate 12 representative memory systems and two reference baselines across five benchmark workloads spanning 11 datasets. Our extensive end-to-end evaluation shows that no single architecture dominates across all scenarios; instead, effectiveness depends heavily on how well the memory structure aligns with the workload bottleneck. Furthermore, through fine-grained ablation studies, we quantify their individual effects on representation fidelity, retrieval precision, update correctness, and long-horizon stability. Finally, we reveal cost-performance trade-offs under realistic workloads, showing localized maintenance is more cost-efficient than global reorganization. Based on these findings, we identify promising directions towards building truly agent-native memory systems. The code is publicly available at https://github.com/OpenDataBox/MemoryData.
Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
Jan 22, 2026Data preparation aims to denoise raw datasets, uncover cross-dataset relationships, and extract valuable insights from them, which is essential for a wide range of data-centric applications. Driven by (i) rising demands for application-ready data (e.g., for analytics, visualization, decision-making), (ii) increasingly powerful LLM techniques, and (iii) the emergence of infrastructures that facilitate flexible agent construction (e.g., using Databricks Unity Catalog), LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation. By investigating hundreds of recent literature works, this paper presents a systematic review of this evolving landscape, focusing on the use of LLM techniques to prepare data for diverse downstream tasks. First, we characterize the fundamental paradigm shift, from rule-based, model-specific pipelines to prompt-driven, context-aware, and agentic preparation workflows. Next, we introduce a task-centric taxonomy that organizes the field into three major tasks: data cleaning (e.g., standardization, error processing, imputation), data integration (e.g., entity matching, schema matching), and data enrichment (e.g., data annotation, profiling). For each task, we survey representative techniques, and highlight their respective strengths (e.g., improved generalization, semantic understanding) and limitations (e.g., the prohibitive cost of scaling LLMs, persistent hallucinations even in advanced agents, the mismatch between advanced methods and weak evaluation). Moreover, we analyze commonly used datasets and evaluation metrics (the empirical part). Finally, we discuss open research challenges and outline a forward-looking roadmap that emphasizes scalable LLM-data systems, principled designs for reliable agentic workflows, and robust evaluation protocols.
CompleteDT: Point Cloud Completion with Dense Augment Inference Transformers
May 30, 2022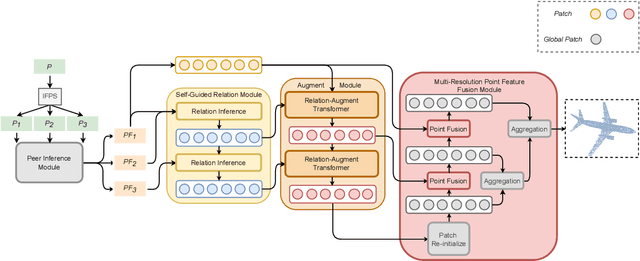

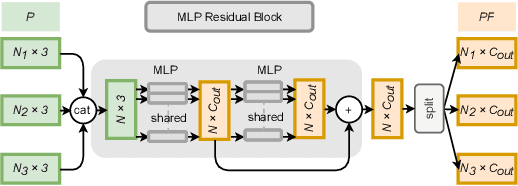

Point cloud completion task aims to predict the missing part of incomplete point clouds and generate complete point clouds with details. In this paper, we propose a novel point cloud completion network, CompleteDT, which is based on the transformer. CompleteDT can learn features within neighborhoods and explore the relationship among these neighborhoods. By sampling the incomplete point cloud to obtain point clouds with different resolutions, we extract features from these point clouds in a self-guided manner, while converting these features into a series of $patches$ based on the geometrical structure. To facilitate transformers to leverage sufficient information about point clouds, we provide a plug-and-play module named Relation-Augment Attention Module (RAA), consisting of Point Cross-Attention Module (PCA) and Point Dense Multi-Scale Attention Module (PDMA). These two modules can enhance the ability to learn features within Patches and consider the correlation among these Patches. Thus, RAA enables to learn structures of incomplete point clouds and contribute to infer the local details of complete point clouds generated. In addition, we predict the complete shape from $patches$ with an efficient generation module, namely, Multi-resolution Point Fusion Module (MPF). MPF gradually generates complete point clouds from $patches$, and updates $patches$ based on these generated point clouds. Experimental results show that our method largely outperforms the state-of-the-art methods.
CT-block: a novel local and global features extractor for point cloud
Nov 30, 2021Deep learning on the point cloud is increasingly developing. Grouping the point with its neighbors and conducting convolution-like operation on them can learn the local feature of the point cloud, but this method is weak to extract the long-distance global feature. Performing the attention-based transformer on the whole point cloud can effectively learn the global feature of it, but this method is hardly to extract the local detailed feature. In this paper, we propose a novel module that can simultaneously extract and fuse local and global features, which is named as CT-block. The CT-block is composed of two branches, where the letter C represents the convolution-branch and the letter T represents the transformer-branch. The convolution-branch performs convolution on the grouped neighbor points to extract the local feature. Meanwhile, the transformer-branch performs offset-attention process on the whole point cloud to extract the global feature. Through the bridge constructed by the feature transmission element in the CT-block, the local and global features guide each other during learning and are fused effectively. We apply the CT-block to construct point cloud classification and segmentation networks, and evaluate the performance of them by several public datasets. The experimental results show that, because the features learned by CT-block are much expressive, the performance of the networks constructed by the CT-block on the point cloud classification and segmentation tasks achieve state of the art.