 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixColor: Pixel Recursive Colorization
Jun 05, 2017
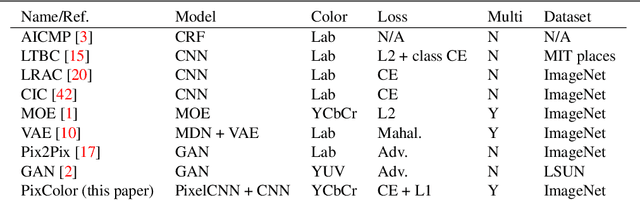


We propose a novel approach to automatically produce multiple colorized versions of a grayscale image. Our method results from the observation that the task of automated colorization is relatively easy given a low-resolution version of the color image. We first train a conditional PixelCNN to generate a low resolution color for a given grayscale image. Then, given the generated low-resolution color image and the original grayscale image as inputs, we train a second CNN to generate a high-resolution colorization of an image. We demonstrate that our approach produces more diverse and plausible colorizations than existing methods, as judged by human raters in a "Visual Turing Test".
Speed/accuracy trade-offs for modern convolutional object detectors
Apr 25, 2017
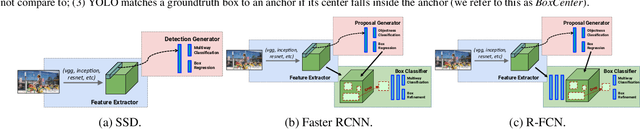

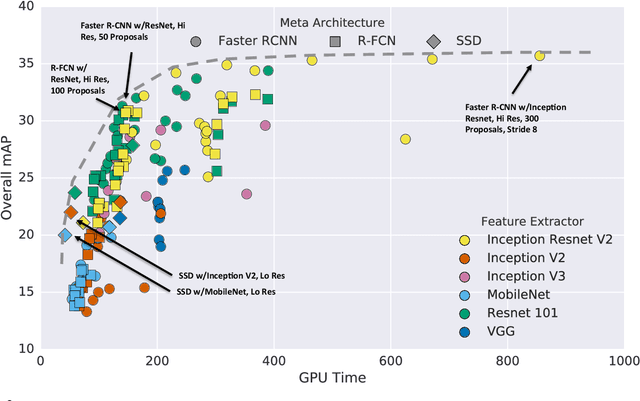
The goal of this paper is to serve as a guide for selecting a detection architecture that achieves the right speed/memory/accuracy balance for a given application and platform. To this end, we investigate various ways to trade accuracy for speed and memory usage in modern convolutional object detection systems. A number of successful systems have been proposed in recent years, but apples-to-apples comparisons are difficult due to different base feature extractors (e.g., VGG, Residual Networks), different default image resolutions, as well as different hardware and software platforms. We present a unified implementation of the Faster R-CNN [Ren et al., 2015], R-FCN [Dai et al., 2016] and SSD [Liu et al., 2015] systems, which we view as "meta-architectures" and trace out the speed/accuracy trade-off curve created by using alternative feature extractors and varying other critical parameters such as image size within each of these meta-architectures. On one extreme end of this spectrum where speed and memory are critical, we present a detector that achieves real time speeds and can be deployed on a mobile device. On the opposite end in which accuracy is critical, we present a detector that achieves state-of-the-art performance measured on the COCO detection task.
Semantic Instance Segmentation via Deep Metric Learning
Mar 30, 2017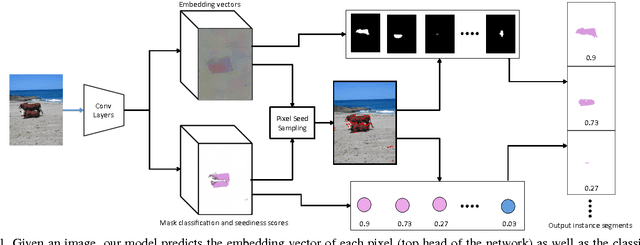
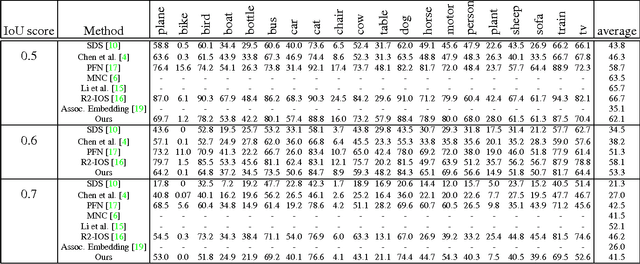
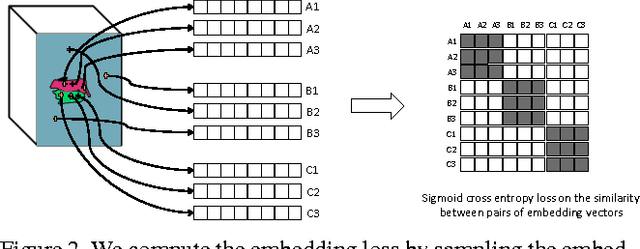

We propose a new method for semantic instance segmentation, by first computing how likely two pixels are to belong to the same object, and then by grouping similar pixels together. Our similarity metric is based on a deep, fully convolutional embedding model. Our grouping method is based on selecting all points that are sufficiently similar to a set of "seed points", chosen from a deep, fully convolutional scoring model. We show competitive results on the Pascal VOC instance segmentation benchmark.
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
May 31, 2016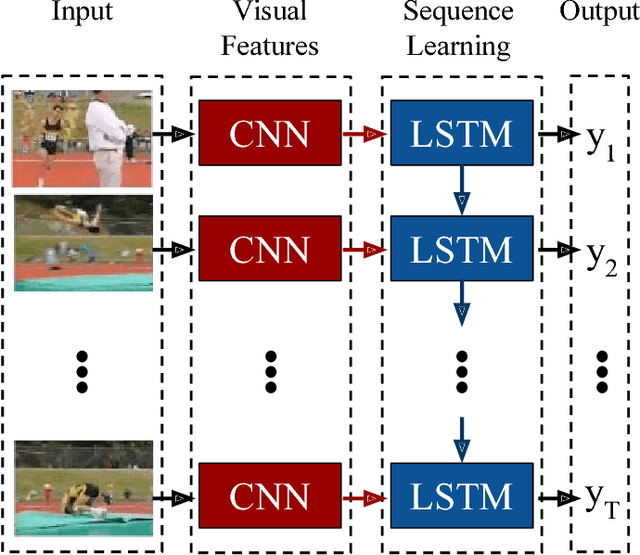

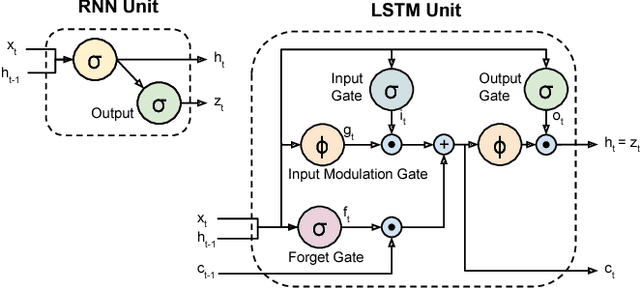
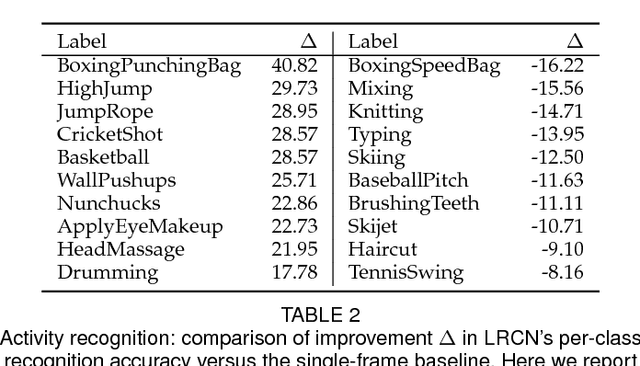
Models based on deep convolutional networks have dominated recent image interpretation tasks; we investigate whether models which are also recurrent, or "temporally deep", are effective for tasks involving sequences, visual and otherwise. We develop a novel recurrent convolutional architecture suitable for large-scale visual learning which is end-to-end trainable, and demonstrate the value of these models on benchmark video recognition tasks, image description and retrieval problems, and video narration challenges. In contrast to current models which assume a fixed spatio-temporal receptive field or simple temporal averaging for sequential processing, recurrent convolutional models are "doubly deep"' in that they can be compositional in spatial and temporal "layers". Such models may have advantages when target concepts are complex and/or training data are limited. Learning long-term dependencies is possible when nonlinearities are incorporated into the network state updates. Long-term RNN models are appealing in that they directly can map variable-length inputs (e.g., video frames) to variable length outputs (e.g., natural language text) and can model complex temporal dynamics; yet they can be optimized with backpropagation. Our recurrent long-term models are directly connected to modern visual convnet models and can be jointly trained to simultaneously learn temporal dynamics and convolutional perceptual representations. Our results show such models have distinct advantages over state-of-the-art models for recognition or generation which are separately defined and/or optimized.
Compute Less to Get More: Using ORC to Improve Sparse Filtering
May 24, 2015
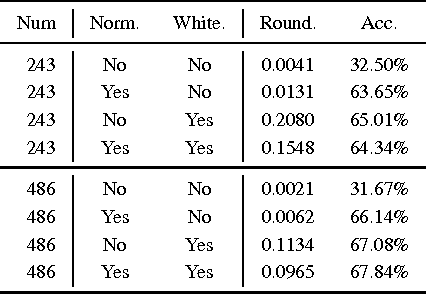
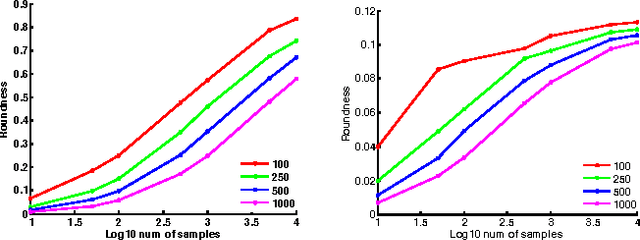
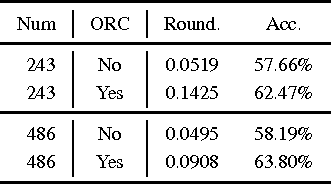
Sparse Filtering is a popular feature learning algorithm for image classification pipelines. In this paper, we connect the performance of Sparse Filtering with spectral properties of the corresponding feature matrices. This connection provides new insights into Sparse Filtering; in particular, it suggests early stopping of Sparse Filtering. We therefore introduce the Optimal Roundness Criterion (ORC), a novel stopping criterion for Sparse Filtering. We show that this stopping criterion is related with pre-processing procedures such as Statistical Whitening and demonstrate that it can make image classification with Sparse Filtering considerably faster and more accurate.
LSDA: Large Scale Detection Through Adaptation
Nov 01, 2014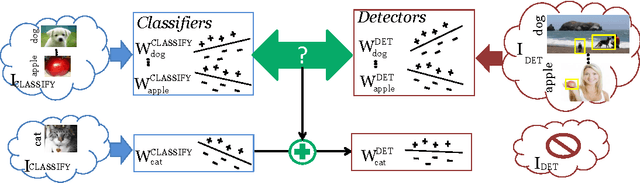
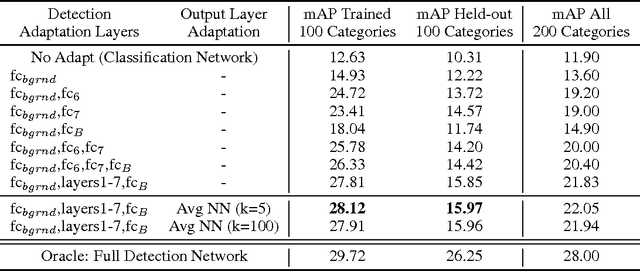
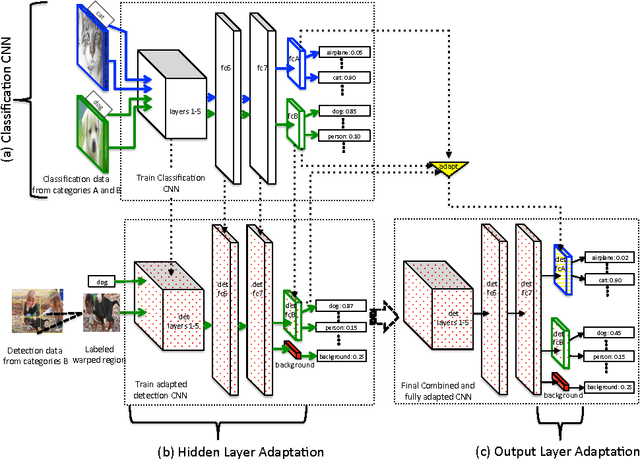
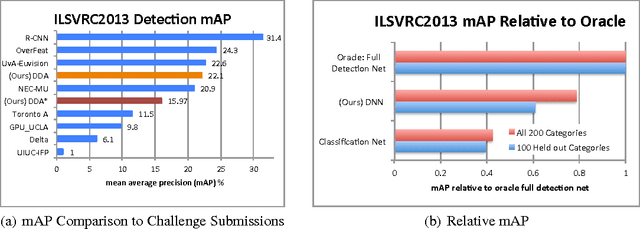
A major challenge in scaling object detection is the difficulty of obtaining labeled images for large numbers of categories. Recently, deep convolutional neural networks (CNNs) have emerged as clear winners on object classification benchmarks, in part due to training with 1.2M+ labeled classification images. Unfortunately, only a small fraction of those labels are available for the detection task. It is much cheaper and easier to collect large quantities of image-level labels from search engines than it is to collect detection data and label it with precise bounding boxes. In this paper, we propose Large Scale Detection through Adaptation (LSDA), an algorithm which learns the difference between the two tasks and transfers this knowledge to classifiers for categories without bounding box annotated data, turning them into detectors. Our method has the potential to enable detection for the tens of thousands of categories that lack bounding box annotations, yet have plenty of classification data. Evaluation on the ImageNet LSVRC-2013 detection challenge demonstrates the efficacy of our approach. This algorithm enables us to produce a >7.6K detector by using available classification data from leaf nodes in the ImageNet tree. We additionally demonstrate how to modify our architecture to produce a fast detector (running at 2fps for the 7.6K detector). Models and software are available at
Caffe: Convolutional Architecture for Fast Feature Embedding
Jun 20, 2014

Caffe provides multimedia scientists and practitioners with a clean and modifiable framework for state-of-the-art deep learning algorithms and a collection of reference models. The framework is a BSD-licensed C++ library with Python and MATLAB bindings for training and deploying general-purpose convolutional neural networks and other deep models efficiently on commodity architectures. Caffe fits industry and internet-scale media needs by CUDA GPU computation, processing over 40 million images a day on a single K40 or Titan GPU ($\approx$ 2.5 ms per image). By separating model representation from actual implementation, Caffe allows experimentation and seamless switching among platforms for ease of development and deployment from prototyping machines to cloud environments. Caffe is maintained and developed by the Berkeley Vision and Learning Center (BVLC) with the help of an active community of contributors on GitHub. It powers ongoing research projects, large-scale industrial applications, and startup prototypes in vision, speech, and multimedia.
Approximate Robotic Mapping from sonar data by modeling Perceptions with Antonyms
Jun 30, 2010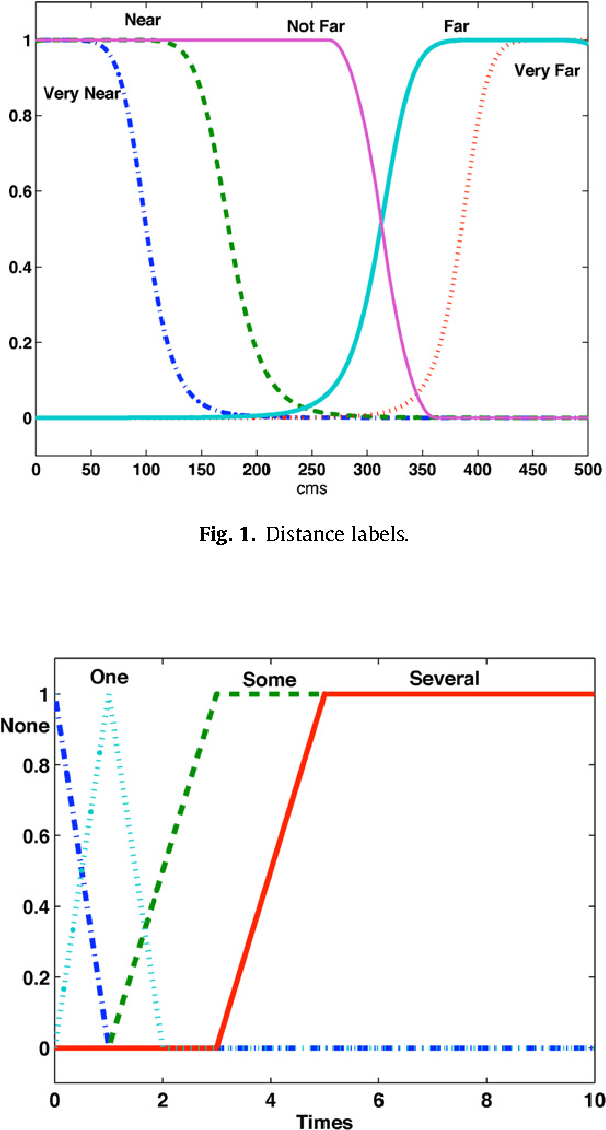

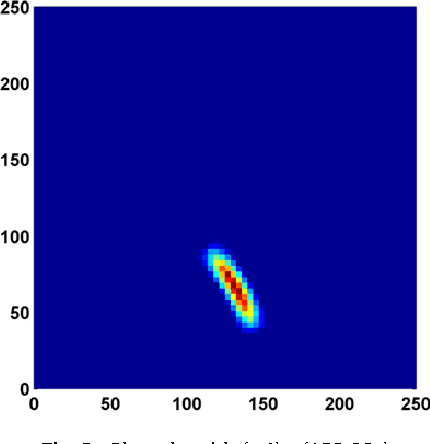
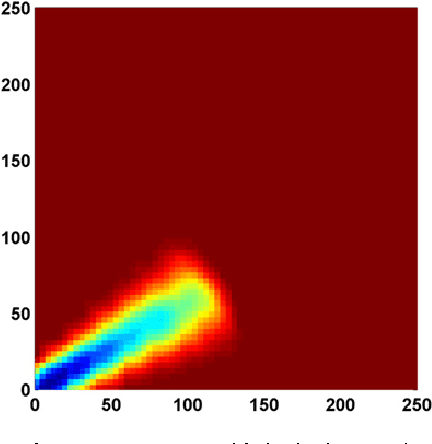
This work, inspired by the idea of "Computing with Words and Perceptions" proposed by Zadeh in 2001, focuses on how to transform measurements into perceptions for the problem of map building by Autonomous Mobile Robots. We propose to model the perceptions obtained from sonar-sensors as two grid maps: one for obstacles and another for empty spaces. The rules used to build and integrate these maps are expressed by linguistic descriptions and modeled by fuzzy rules. The main difference of this approach from other studies reported in the literature is that the method presented here is based on the hypothesis that the concepts "occupied" and "empty" are antonyms rather than complementary (as it happens in probabilistic approaches), or independent (as it happens in the previous fuzzy models). Controlled experimentation with a real robot in three representative indoor environments has been performed and the results presented. We offer a qualitative and quantitative comparison of the estimated maps obtained by the probabilistic approach, the previous fuzzy method and the new antonyms-based fuzzy approach. It is shown that the maps obtained with the antonyms-based approach are better defined, capture better the shape of the walls and of the empty-spaces, and contain less errors due to rebounds and short-echoes. Furthermore, in spite of noise and low resolution inherent to the sonar-sensors used, the maps obtained are accurate and tolerant to imprecision.
Using Soft Constraints To Learn Semantic Models Of Descriptions Of Shapes
May 28, 2010
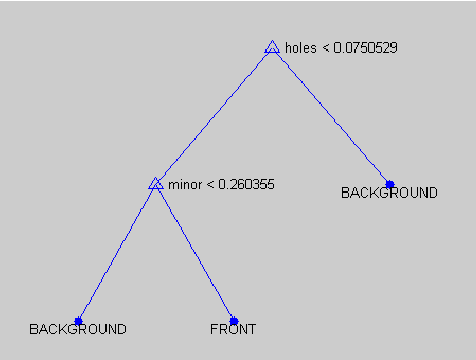
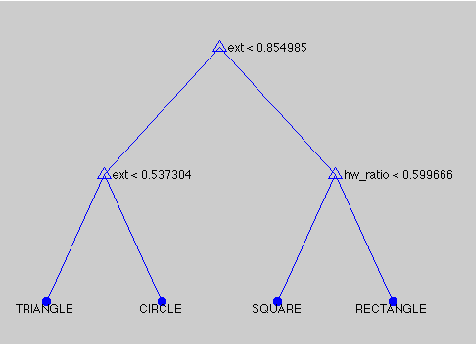
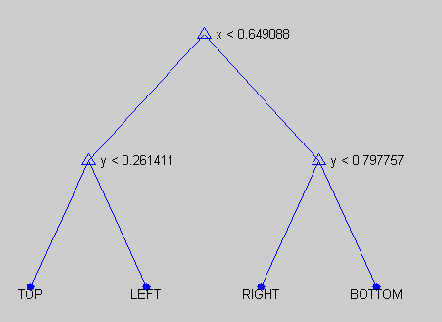
The contribution of this paper is to provide a semantic model (using soft constraints) of the words used by web-users to describe objects in a language game; a game in which one user describes a selected object of those composing the scene, and another user has to guess which object has been described. The given description needs to be non ambiguous and accurate enough to allow other users to guess the described shape correctly. To build these semantic models the descriptions need to be analyzed to extract the syntax and words' classes used. We have modeled the meaning of these descriptions using soft constraints as a way for grounding the meaning. The descriptions generated by the system took into account the context of the object to avoid ambiguous descriptions, and allowed users to guess the described object correctly 72% of the times.