 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode World Models for General Game Playing
Oct 06, 2025



Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
What type of inference is planning?
Jun 25, 2024



Multiple types of inference are available for probabilistic graphical models, e.g., marginal, maximum-a-posteriori, and even marginal maximum-a-posteriori. Which one do researchers mean when they talk about "planning as inference"? There is no consistency in the literature, different types are used, and their ability to do planning is further entangled with specific approximations or additional constraints. In this work we use the variational framework to show that all commonly used types of inference correspond to different weightings of the entropy terms in the variational problem, and that planning corresponds _exactly_ to a _different_ set of weights. This means that all the tricks of variational inference are readily applicable to planning. We develop an analogue of loopy belief propagation that allows us to perform approximate planning in factored state Markov decisions processes without incurring intractability due to the exponentially large state space. The variational perspective shows that the previous types of inference for planning are only adequate in environments with low stochasticity, and allows us to characterize each type by its own merits, disentangling the type of inference from the additional approximations that its practical use requires. We validate these results empirically on synthetic MDPs and tasks posed in the International Planning Competition.
Collapsed Amortized Variational Inference for Switching Nonlinear Dynamical Systems
Oct 21, 2019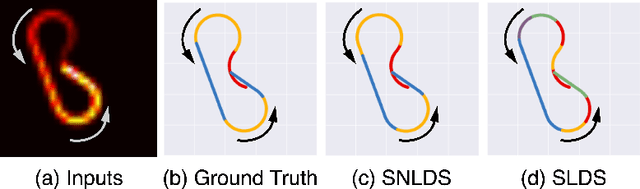

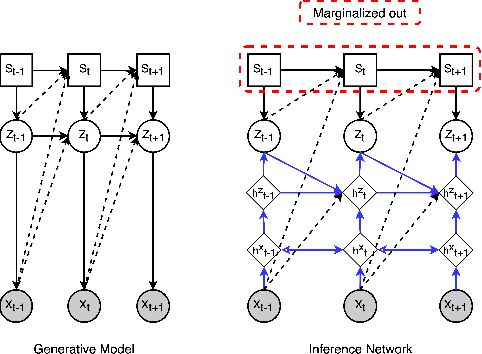

We propose an efficient inference method for switching nonlinear dynamical systems. The key idea is to learn an inference network which can be used as a proposal distribution for the continuous latent variables, while performing exact marginalization of the discrete latent variables. This allows us to use the reparameterization trick, and apply end-to-end training with stochastic gradient descent. We show that the proposed method can successfully segment time series data (including videos) into meaningful "regimes", by using the piece-wise nonlinear dynamics.
Semantic Instance Segmentation via Deep Metric Learning
Mar 30, 2017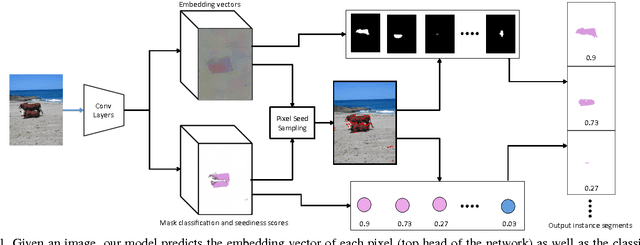
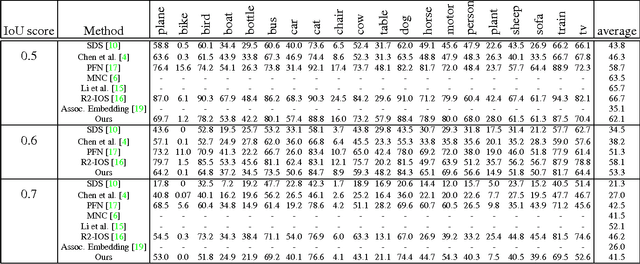
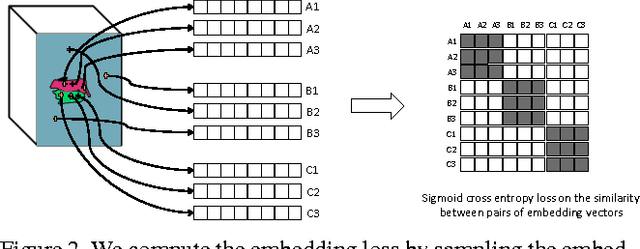

We propose a new method for semantic instance segmentation, by first computing how likely two pixels are to belong to the same object, and then by grouping similar pixels together. Our similarity metric is based on a deep, fully convolutional embedding model. Our grouping method is based on selecting all points that are sufficiently similar to a set of "seed points", chosen from a deep, fully convolutional scoring model. We show competitive results on the Pascal VOC instance segmentation benchmark.