 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining on Test Data with Bayesian Adaptation for Covariate Shift
Sep 27, 2021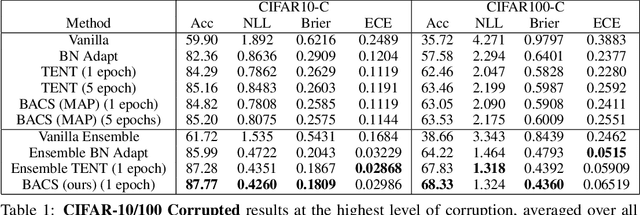
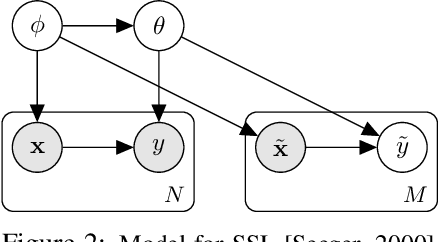
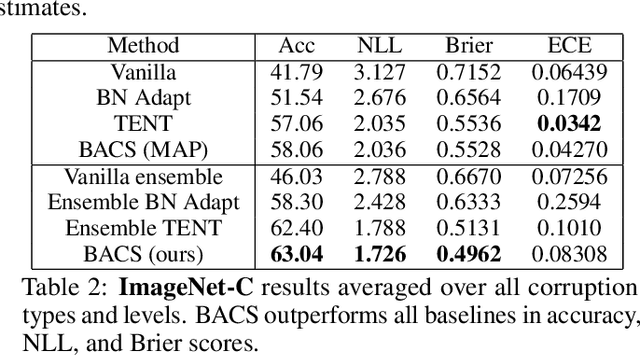
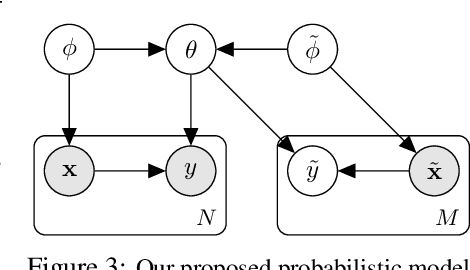
When faced with distribution shift at test time, deep neural networks often make inaccurate predictions with unreliable uncertainty estimates. While improving the robustness of neural networks is one promising approach to mitigate this issue, an appealing alternate to robustifying networks against all possible test-time shifts is to instead directly adapt them to unlabeled inputs from the particular distribution shift we encounter at test time. However, this poses a challenging question: in the standard Bayesian model for supervised learning, unlabeled inputs are conditionally independent of model parameters when the labels are unobserved, so what can unlabeled data tell us about the model parameters at test-time? In this paper, we derive a Bayesian model that provides for a well-defined relationship between unlabeled inputs under distributional shift and model parameters, and show how approximate inference in this model can be instantiated with a simple regularized entropy minimization procedure at test-time. We evaluate our method on a variety of distribution shifts for image classification, including image corruptions, natural distribution shifts, and domain adaptation settings, and show that our method improves both accuracy and uncertainty estimation.
A Workflow for Offline Model-Free Robotic Reinforcement Learning
Sep 23, 2021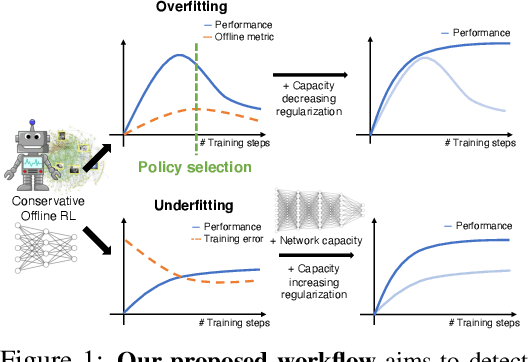

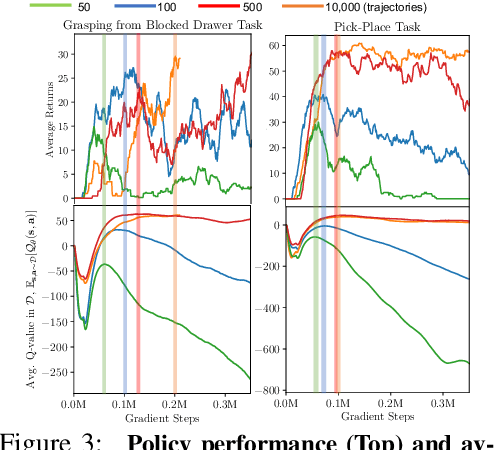
Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from large and diverse datasets, without any costly or unsafe online data collection. Despite recent algorithmic advances in offline RL, applying these methods to real-world problems has proven challenging. Although offline RL methods can learn from prior data, there is no clear and well-understood process for making various design choices, from model architecture to algorithm hyperparameters, without actually evaluating the learned policies online. In this paper, our aim is to develop a practical workflow for using offline RL analogous to the relatively well-understood workflows for supervised learning problems. To this end, we devise a set of metrics and conditions that can be tracked over the course of offline training, and can inform the practitioner about how the algorithm and model architecture should be adjusted to improve final performance. Our workflow is derived from a conceptual understanding of the behavior of conservative offline RL algorithms and cross-validation in supervised learning. We demonstrate the efficacy of this workflow in producing effective policies without any online tuning, both in several simulated robotic learning scenarios and for three tasks on two distinct real robots, focusing on learning manipulation skills with raw image observations with sparse binary rewards. Explanatory video and additional results can be found at sites.google.com/view/offline-rl-workflow
Conservative Data Sharing for Multi-Task Offline Reinforcement Learning
Sep 16, 2021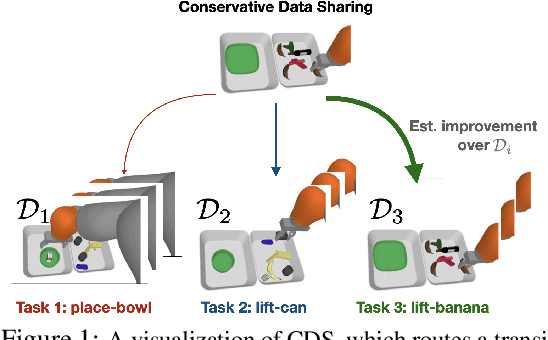
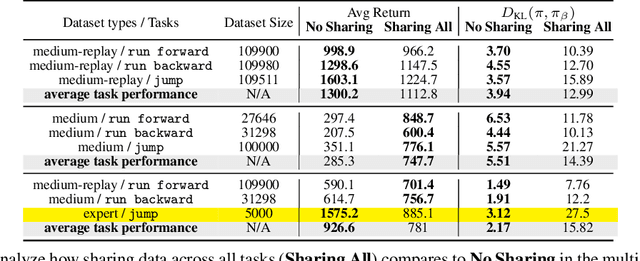
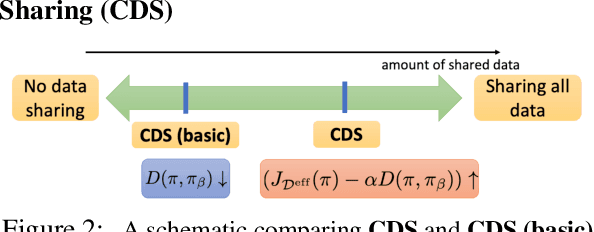

Offline reinforcement learning (RL) algorithms have shown promising results in domains where abundant pre-collected data is available. However, prior methods focus on solving individual problems from scratch with an offline dataset without considering how an offline RL agent can acquire multiple skills. We argue that a natural use case of offline RL is in settings where we can pool large amounts of data collected in various scenarios for solving different tasks, and utilize all of this data to learn behaviors for all the tasks more effectively rather than training each one in isolation. However, sharing data across all tasks in multi-task offline RL performs surprisingly poorly in practice. Thorough empirical analysis, we find that sharing data can actually exacerbate the distributional shift between the learned policy and the dataset, which in turn can lead to divergence of the learned policy and poor performance. To address this challenge, we develop a simple technique for data-sharing in multi-task offline RL that routes data based on the improvement over the task-specific data. We call this approach conservative data sharing (CDS), and it can be applied with multiple single-task offline RL methods. On a range of challenging multi-task locomotion, navigation, and vision-based robotic manipulation problems, CDS achieves the best or comparable performance compared to prior offline multi-task RL methods and previous data sharing approaches.
Robust Predictable Control
Sep 07, 2021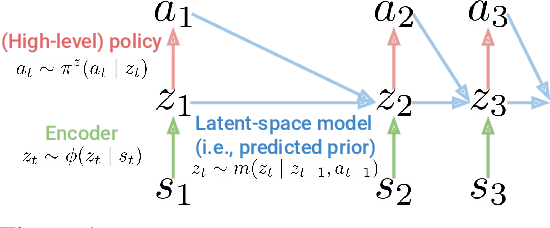
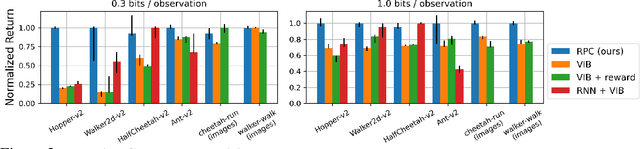
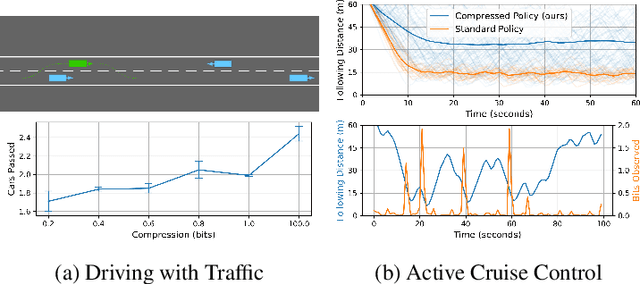
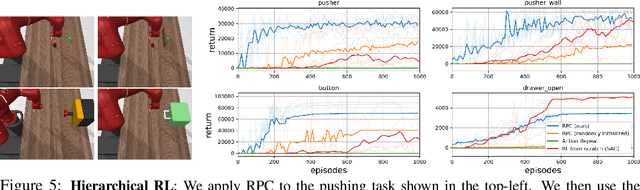
Many of the challenges facing today's reinforcement learning (RL) algorithms, such as robustness, generalization, transfer, and computational efficiency are closely related to compression. Prior work has convincingly argued why minimizing information is useful in the supervised learning setting, but standard RL algorithms lack an explicit mechanism for compression. The RL setting is unique because (1) its sequential nature allows an agent to use past information to avoid looking at future observations and (2) the agent can optimize its behavior to prefer states where decision making requires few bits. We take advantage of these properties to propose a method (RPC) for learning simple policies. This method brings together ideas from information bottlenecks, model-based RL, and bits-back coding into a simple and theoretically-justified algorithm. Our method jointly optimizes a latent-space model and policy to be self-consistent, such that the policy avoids states where the model is inaccurate. We demonstrate that our method achieves much tighter compression than prior methods, achieving up to 5x higher reward than a standard information bottleneck. We also demonstrate that our method learns policies that are more robust and generalize better to new tasks.
Fully Autonomous Real-World Reinforcement Learning for Mobile Manipulation
Aug 03, 2021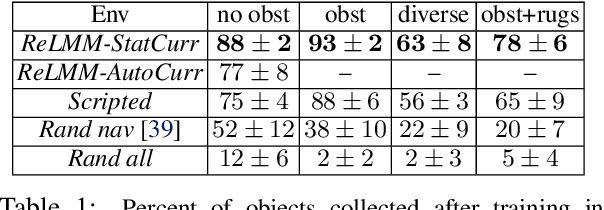
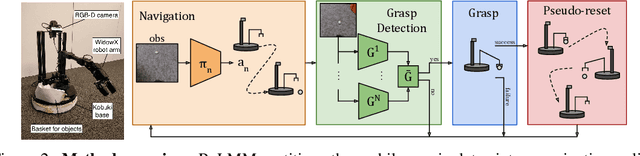

We study how robots can autonomously learn skills that require a combination of navigation and grasping. While reinforcement learning in principle provides for automated robotic skill learning, in practice reinforcement learning in the real world is challenging and often requires extensive instrumentation and supervision. Our aim is to devise a robotic reinforcement learning system for learning navigation and manipulation together, in an autonomous way without human intervention, enabling continual learning under realistic assumptions. Our proposed system, ReLMM, can learn continuously on a real-world platform without any environment instrumentation, without human intervention, and without access to privileged information, such as maps, objects positions, or a global view of the environment. Our method employs a modularized policy with components for manipulation and navigation, where manipulation policy uncertainty drives exploration for the navigation controller, and the manipulation module provides rewards for navigation. We evaluate our method on a room cleanup task, where the robot must navigate to and pick up items scattered on the floor. After a grasp curriculum training phase, ReLMM can learn navigation and grasping together fully automatically, in around 40 hours of autonomous real-world training.
Persistent Reinforcement Learning via Subgoal Curricula
Jul 27, 2021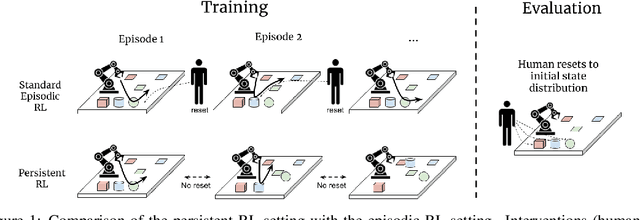
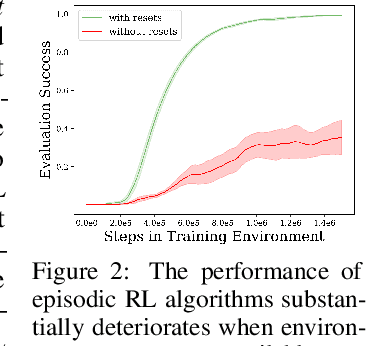
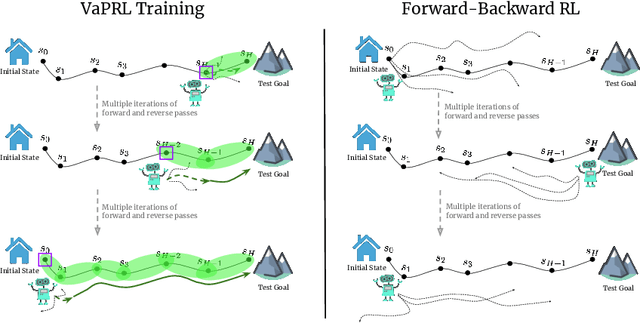
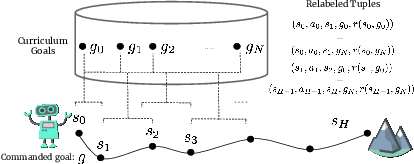
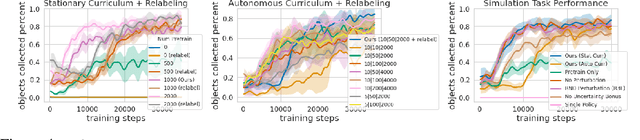
Reinforcement learning (RL) promises to enable autonomous acquisition of complex behaviors for diverse agents. However, the success of current reinforcement learning algorithms is predicated on an often under-emphasised requirement -- each trial needs to start from a fixed initial state distribution. Unfortunately, resetting the environment to its initial state after each trial requires substantial amount of human supervision and extensive instrumentation of the environment which defeats the purpose of autonomous reinforcement learning. In this work, we propose Value-accelerated Persistent Reinforcement Learning (VaPRL), which generates a curriculum of initial states such that the agent can bootstrap on the success of easier tasks to efficiently learn harder tasks. The agent also learns to reach the initial states proposed by the curriculum, minimizing the reliance on human interventions into the learning. We observe that VaPRL reduces the interventions required by three orders of magnitude compared to episodic RL while outperforming prior state-of-the art methods for reset-free RL both in terms of sample efficiency and asymptotic performance on a variety of simulated robotics problems.
Modularity in Reinforcement Learning via Algorithmic Independence in Credit Assignment
Jul 21, 2021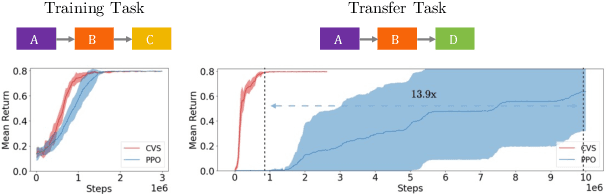
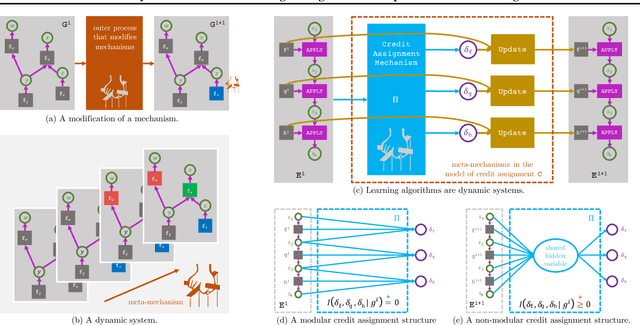
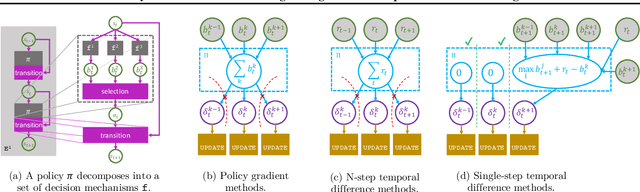
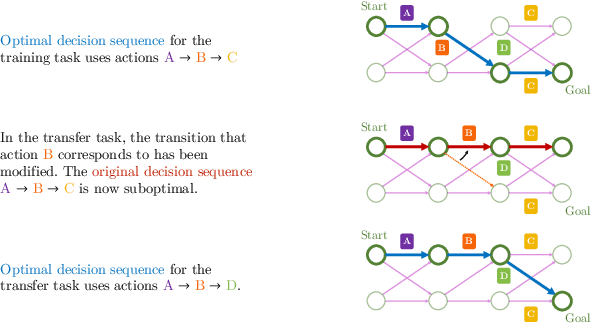
Many transfer problems require re-using previously optimal decisions for solving new tasks, which suggests the need for learning algorithms that can modify the mechanisms for choosing certain actions independently of those for choosing others. However, there is currently no formalism nor theory for how to achieve this kind of modular credit assignment. To answer this question, we define modular credit assignment as a constraint on minimizing the algorithmic mutual information among feedback signals for different decisions. We introduce what we call the modularity criterion for testing whether a learning algorithm satisfies this constraint by performing causal analysis on the algorithm itself. We generalize the recently proposed societal decision-making framework as a more granular formalism than the Markov decision process to prove that for decision sequences that do not contain cycles, certain single-step temporal difference action-value methods meet this criterion while all policy-gradient methods do not. Empirical evidence suggests that such action-value methods are more sample efficient than policy-gradient methods on transfer problems that require only sparse changes to a sequence of previously optimal decisions.
Offline Meta-Reinforcement Learning with Online Self-Supervision
Jul 19, 2021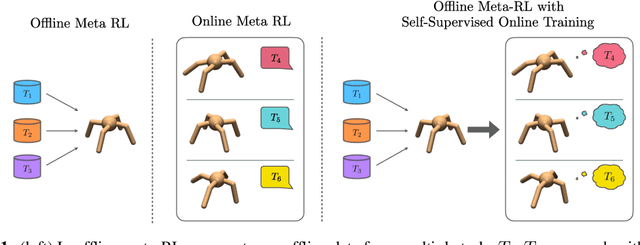
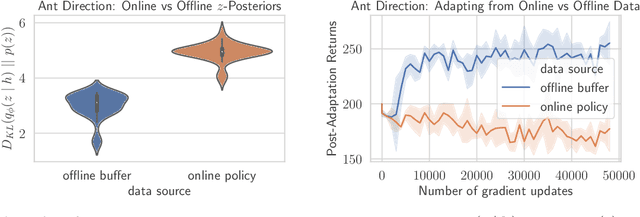
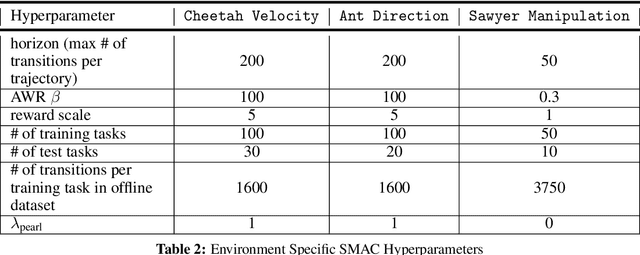
Meta-reinforcement learning (RL) can meta-train policies that adapt to new tasks with orders of magnitude less data than standard RL, but meta-training itself is costly and time-consuming. If we can meta-train on offline data, then we can reuse the same static dataset, labeled once with rewards for different tasks, to meta-train policies that adapt to a variety of new tasks at meta-test time. Although this capability would make meta-RL a practical tool for real-world use, offline meta-RL presents additional challenges beyond online meta-RL or standard offline RL settings. Meta-RL learns an exploration strategy that collects data for adapting, and also meta-trains a policy that quickly adapts to data from a new task. Since this policy was meta-trained on a fixed, offline dataset, it might behave unpredictably when adapting to data collected by the learned exploration strategy, which differs systematically from the offline data and thus induces distributional shift. We do not want to remove this distributional shift by simply adopting a conservative exploration strategy, because learning an exploration strategy enables an agent to collect better data for faster adaptation. Instead, we propose a hybrid offline meta-RL algorithm, which uses offline data with rewards to meta-train an adaptive policy, and then collects additional unsupervised online data, without any reward labels to bridge this distribution shift. By not requiring reward labels for online collection, this data can be much cheaper to collect. We compare our method to prior work on offline meta-RL on simulated robot locomotion and manipulation tasks and find that using additional unsupervised online data collection leads to a dramatic improvement in the adaptive capabilities of the meta-trained policies, matching the performance of fully online meta-RL on a range of challenging domains that require generalization to new tasks.
MURAL: Meta-Learning Uncertainty-Aware Rewards for Outcome-Driven Reinforcement Learning
Jul 18, 2021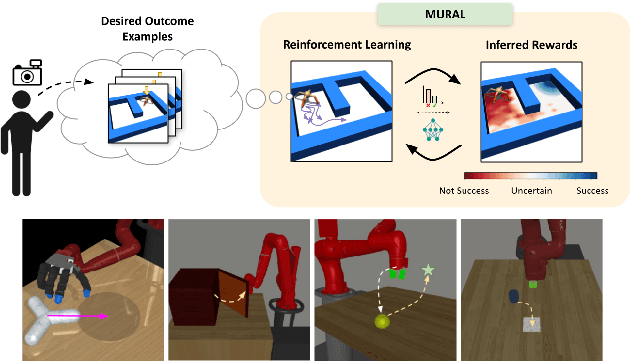
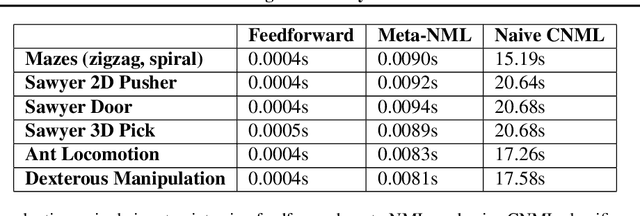

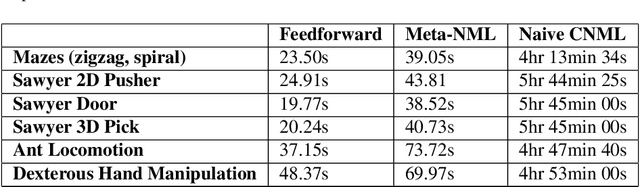
Exploration in reinforcement learning is a challenging problem: in the worst case, the agent must search for high-reward states that could be hidden anywhere in the state space. Can we define a more tractable class of RL problems, where the agent is provided with examples of successful outcomes? In this problem setting, the reward function can be obtained automatically by training a classifier to categorize states as successful or not. If trained properly, such a classifier can provide a well-shaped objective landscape that both promotes progress toward good states and provides a calibrated exploration bonus. In this work, we show that an uncertainty aware classifier can solve challenging reinforcement learning problems by both encouraging exploration and provided directed guidance towards positive outcomes. We propose a novel mechanism for obtaining these calibrated, uncertainty-aware classifiers based on an amortized technique for computing the normalized maximum likelihood (NML) distribution. To make this tractable, we propose a novel method for computing the NML distribution by using meta-learning. We show that the resulting algorithm has a number of intriguing connections to both count-based exploration methods and prior algorithms for learning reward functions, while also providing more effective guidance towards the goal. We demonstrate that our algorithm solves a number of challenging navigation and robotic manipulation tasks which prove difficult or impossible for prior methods.
Conservative Objective Models for Effective Offline Model-Based Optimization
Jul 14, 2021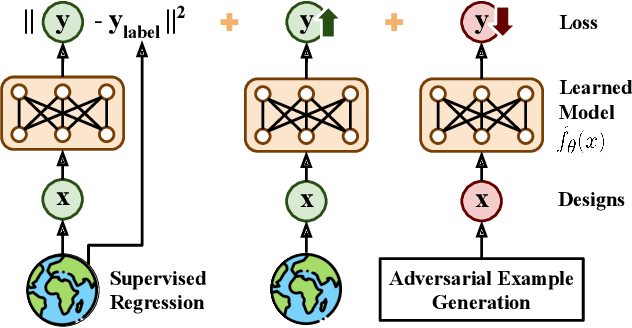
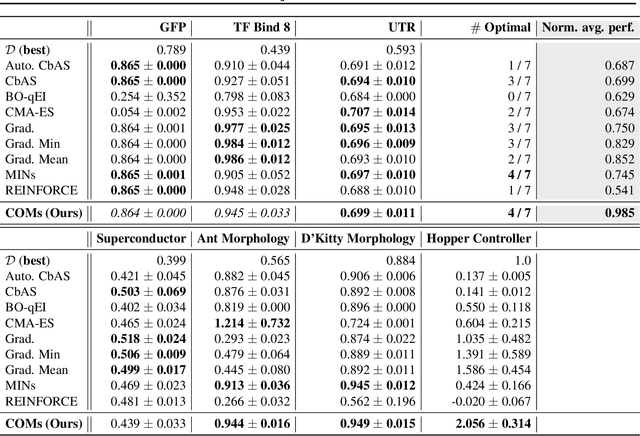
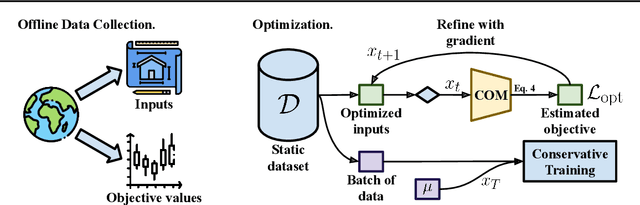
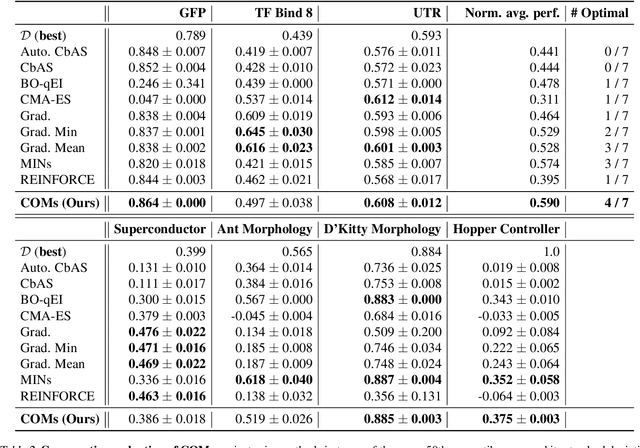
Computational design problems arise in a number of settings, from synthetic biology to computer architectures. In this paper, we aim to solve data-driven model-based optimization (MBO) problems, where the goal is to find a design input that maximizes an unknown objective function provided access to only a static dataset of prior experiments. Such data-driven optimization procedures are the only practical methods in many real-world domains where active data collection is expensive (e.g., when optimizing over proteins) or dangerous (e.g., when optimizing over aircraft designs). Typical methods for MBO that optimize the design against a learned model suffer from distributional shift: it is easy to find a design that "fools" the model into predicting a high value. To overcome this, we propose conservative objective models (COMs), a method that learns a model of the objective function that lower bounds the actual value of the ground-truth objective on out-of-distribution inputs, and uses it for optimization. Structurally, COMs resemble adversarial training methods used to overcome adversarial examples. COMs are simple to implement and outperform a number of existing methods on a wide range of MBO problems, including optimizing protein sequences, robot morphologies, neural network weights, and superconducting materials.