 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction2Motion: Conditioned Generation of 3D Human Motions
Jul 30, 2020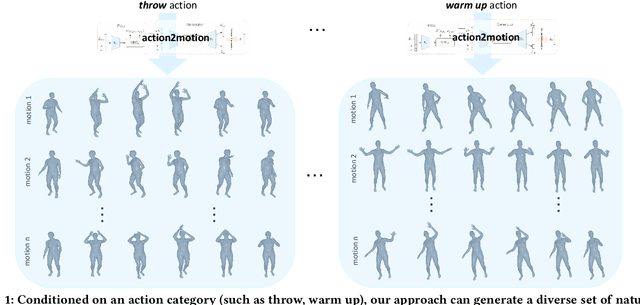
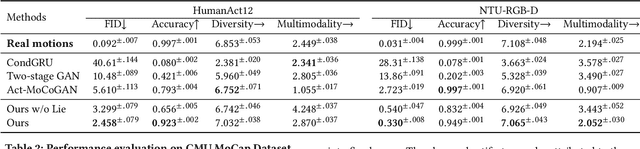
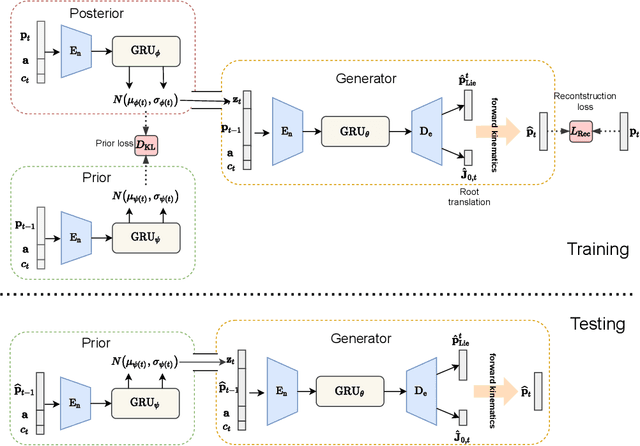
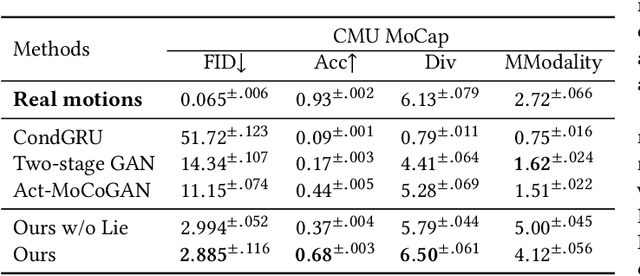
Action recognition is a relatively established task, where givenan input sequence of human motion, the goal is to predict its ac-tion category. This paper, on the other hand, considers a relativelynew problem, which could be thought of as an inverse of actionrecognition: given a prescribed action type, we aim to generateplausible human motion sequences in 3D. Importantly, the set ofgenerated motions are expected to maintain itsdiversityto be ableto explore the entire action-conditioned motion space; meanwhile,each sampled sequence faithfully resembles anaturalhuman bodyarticulation dynamics. Motivated by these objectives, we followthe physics law of human kinematics by adopting the Lie Algebratheory to represent thenaturalhuman motions; we also propose atemporal Variational Auto-Encoder (VAE) that encourages adiversesampling of the motion space. A new 3D human motion dataset, HumanAct12, is also constructed. Empirical experiments overthree distinct human motion datasets (including ours) demonstratethe effectiveness of our approach.
3D Human Shape Reconstruction from a Polarization Image
Jul 17, 2020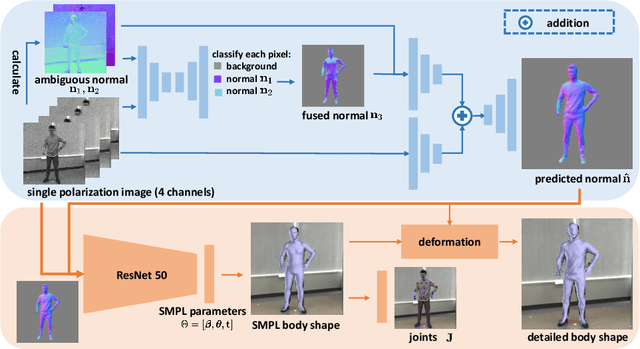
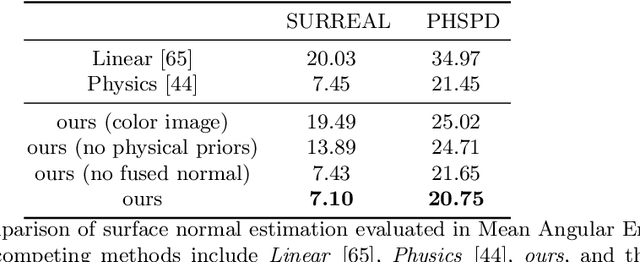


This paper tackles the problem of estimating 3D body shape of clothed humans from single polarized 2D images, i.e. polarization images. Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing surface normal of the objects of interest. Inspired by the recent advances in human shape estimation from single color images, in this paper, we attempt at estimating human body shapes by leveraging the geometric cues from single polarization images. A dedicated two-stage deep learning approach, SfP, is proposed: given a polarization image, stage one aims at inferring the fined-detailed body surface normal; stage two gears to reconstruct the 3D body shape of clothing details. Empirical evaluations on a synthetic dataset (SURREAL) as well as a real-world dataset (PHSPD) demonstrate the qualitative and quantitative performance of our approach in estimating human poses and shapes. This indicates polarization camera is a promising alternative to the more conventional color or depth imaging for human shape estimation. Further, normal maps inferred from polarization imaging play a significant role in accurately recovering the body shapes of clothed people.
Self-Attention Enhanced Patient Journey Understanding in Healthcare System
Jun 19, 2020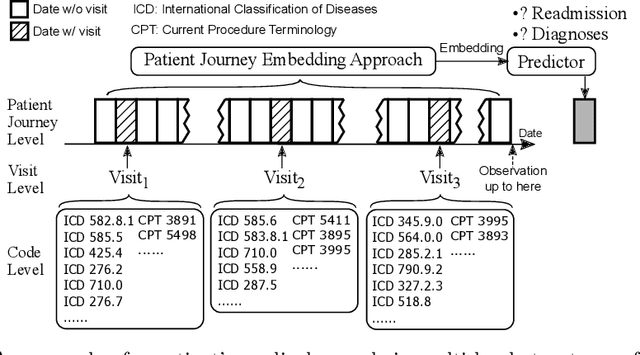

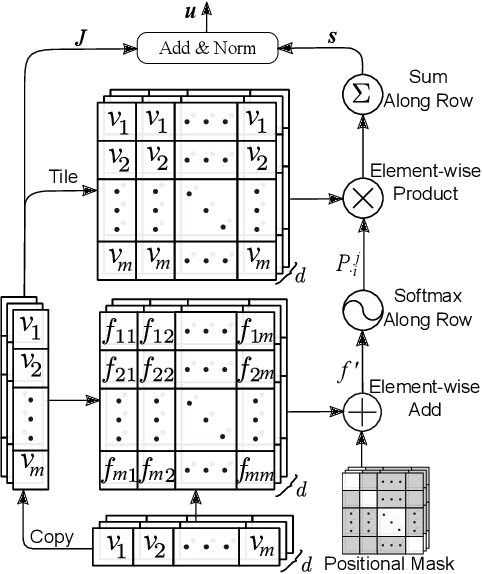
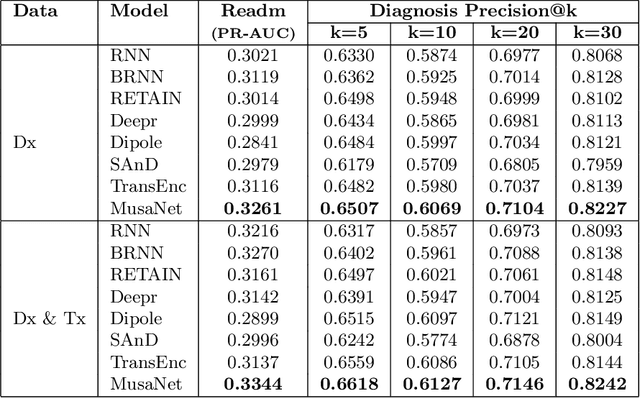
Understanding patients' journeys in healthcare system is a fundamental prepositive task for a broad range of AI-based healthcare applications. This task aims to learn an informative representation that can comprehensively encode hidden dependencies among medical events and its inner entities, and then the use of encoding outputs can greatly benefit the downstream application-driven tasks. A patient journey is a sequence of electronic health records (EHRs) over time that is organized at multiple levels: patient, visits and medical codes. The key challenge of patient journey understanding is to design an effective encoding mechanism which can properly tackle the aforementioned multi-level structured patient journey data with temporal sequential visits and a set of medical codes. This paper proposes a novel self-attention mechanism that can simultaneously capture the contextual and temporal relationships hidden in patient journeys. A multi-level self-attention network (MusaNet) is specifically designed to learn the representations of patient journeys that is used to be a long sequence of activities. The MusaNet is trained in end-to-end manner using the training data derived from EHRs. We evaluated the efficacy of our method on two medical application tasks with real-world benchmark datasets. The results have demonstrated the proposed MusaNet produces higher-quality representations than state-of-the-art baseline methods. The source code is available in https://github.com/xueping/MusaNet.
Multi-Task Reinforcement Learning based Mobile Manipulation Control for Dynamic Object Tracking and Grasping
Jun 07, 2020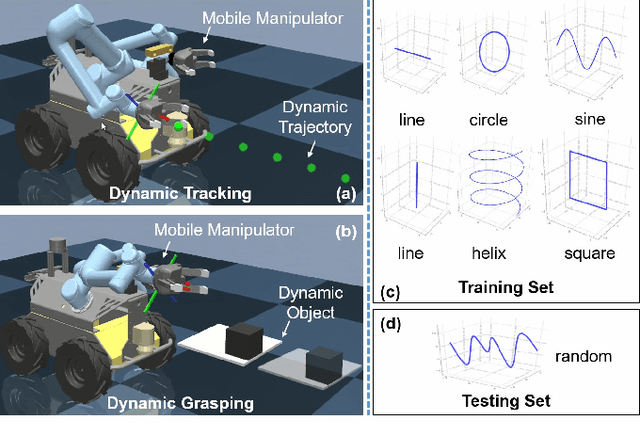
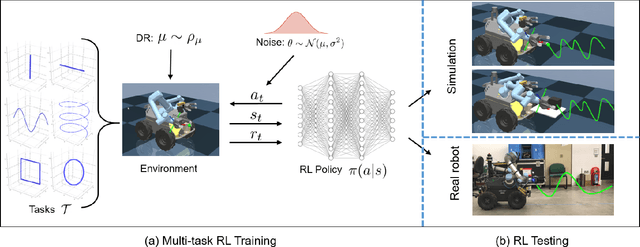
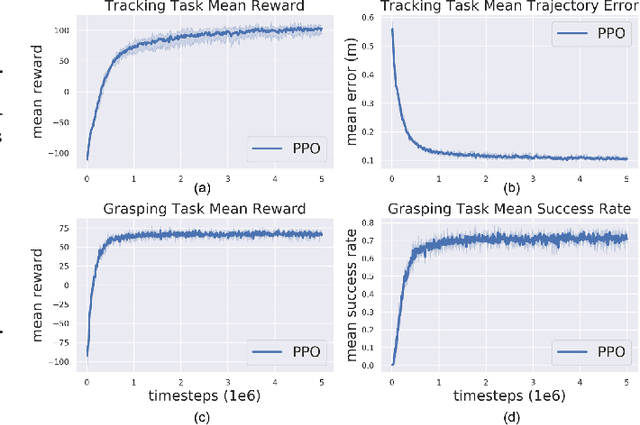

Agile control of mobile manipulator is challenging because of the high complexity coupled by the robotic system and the unstructured working environment. Tracking and grasping a dynamic object with a random trajectory is even harder. In this paper, a multi-task reinforcement learning-based mobile manipulation control framework is proposed to achieve general dynamic object tracking and grasping. Several basic types of dynamic trajectories are chosen as the task training set. To improve the policy generalization in practice, random noise and dynamics randomization are introduced during the training process. Extensive experiments show that our policy trained can adapt to unseen random dynamic trajectories with about 0.1m tracking error and 75\% grasping success rate of dynamic objects. The trained policy can also be successfully deployed on a real mobile manipulator.
SparseFusion: Dynamic Human Avatar Modeling from Sparse RGBD Images
Jun 05, 2020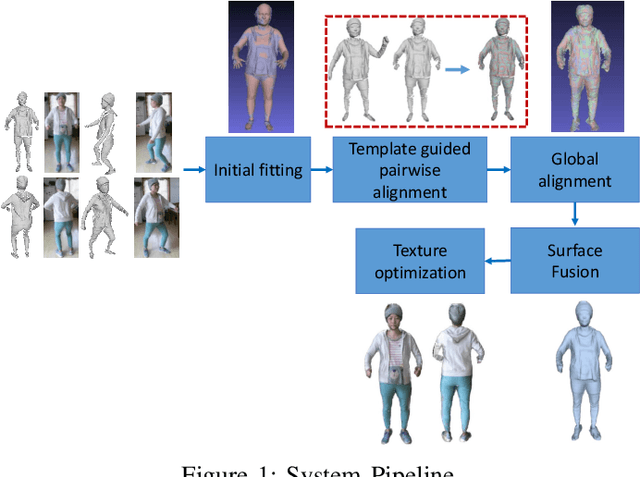

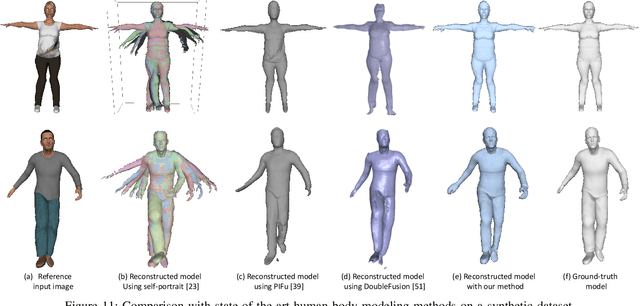
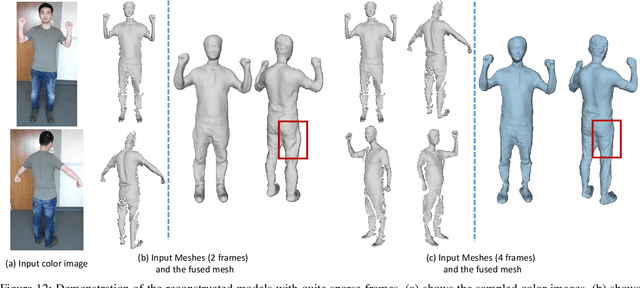
In this paper, we propose a novel approach to reconstruct 3D human body shapes based on a sparse set of RGBD frames using a single RGBD camera. We specifically focus on the realistic settings where human subjects move freely during the capture. The main challenge is how to robustly fuse these sparse frames into a canonical 3D model, under pose changes and surface occlusions. This is addressed by our new framework consisting of the following steps. First, based on a generative human template, for every two frames having sufficient overlap, an initial pairwise alignment is performed; It is followed by a global non-rigid registration procedure, in which partial results from RGBD frames are collected into a unified 3D shape, under the guidance of correspondences from the pairwise alignment; Finally, the texture map of the reconstructed human model is optimized to deliver a clear and spatially consistent texture. Empirical evaluations on synthetic and real datasets demonstrate both quantitatively and qualitatively the superior performance of our framework in reconstructing complete 3D human models with high fidelity. It is worth noting that our framework is flexible, with potential applications going beyond shape reconstruction. As an example, we showcase its use in reshaping and reposing to a new avatar.
A Comparison of Few-Shot Learning Methods for Underwater Optical and Sonar Image Classification
May 10, 2020
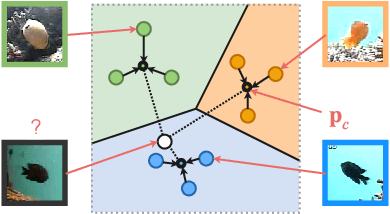
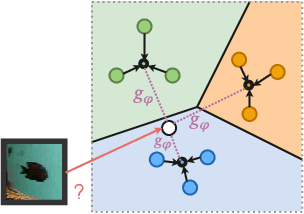
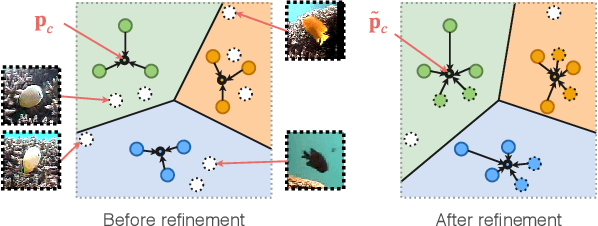
Deep convolutional neural networks have shown to perform well in underwater object recognition tasks, on both optical and sonar images. However, many such methods require hundreds, if not thousands, of images per class to generalize well to unseen examples. This is restricting in situations where obtaining and labeling larger volumes of data is impractical, such as observing a rare object, performing real-time operations, or operating in new underwater environments. Finding an algorithm capable of learning from only a few samples could reduce the time spent obtaining and labeling datasets, and accelerate the training of deep-learning models. To the best of our knowledge, this is the first paper to evaluate and compare several Few-Shot Learning (FSL) methods using underwater optical and side-scan sonar imagery. Our results show that FSL methods offer a significant advantage over the traditional transfer learning methods that employ fine-tuning of pre-trained models. Our findings show that FSL methods are not too far from being used on real-world robotics scenarios and expanding the capabilities of autonomous underwater systems.
RadarSLAM: Radar based Large-Scale SLAM in All Weathers
May 05, 2020
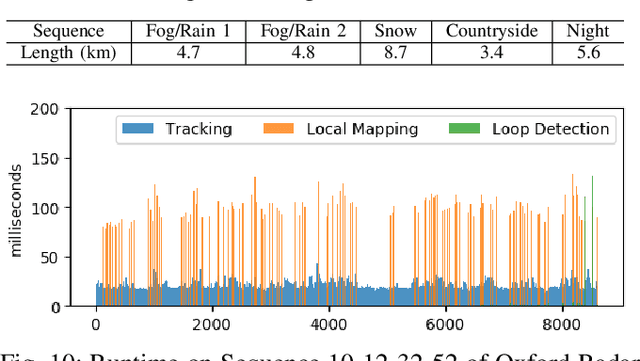
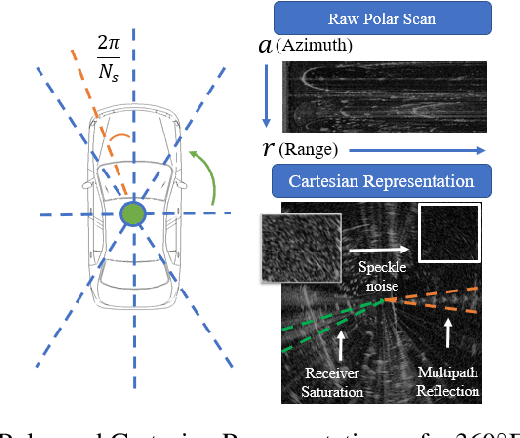
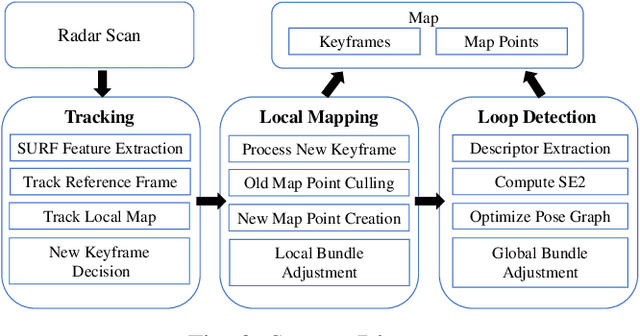
Numerous Simultaneous Localization and Mapping (SLAM) algorithms have been presented in last decade using different sensor modalities. However, robust SLAM in extreme weather conditions is still an open research problem. In this paper, RadarSLAM, a full radar based graph SLAM system, is proposed for reliable localization and mapping in large-scale environments. It is composed of pose tracking, local mapping, loop closure detection and pose graph optimization, enhanced by novel feature matching and probabilistic point cloud generation on radar images. Extensive experiments are conducted on a public radar dataset and several self-collected radar sequences, demonstrating the state-of-the-art reliability and localization accuracy in various adverse weather conditions, such as dark night, dense fog and heavy snowfall.
Polarization Human Shape and Pose Dataset
Apr 30, 2020


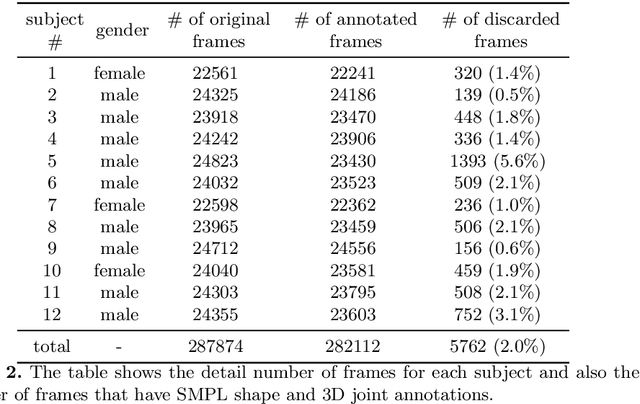
Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing detailed surface normal of the objects of interest. Meanwhile, inspired by the recent breakthroughs in human shape estimation from a single color image, we attempt to investigate the new question of whether the geometric cues from polarization camera could be leveraged in estimating detailed human body shapes. This has led to the curation of Polarization Human Shape and Pose Dataset (PHSPD)5, our home-grown polarization image dataset of various human shapes and poses.
ZSTAD: Zero-Shot Temporal Activity Detection
Mar 12, 2020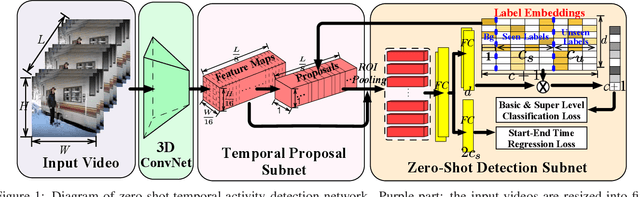
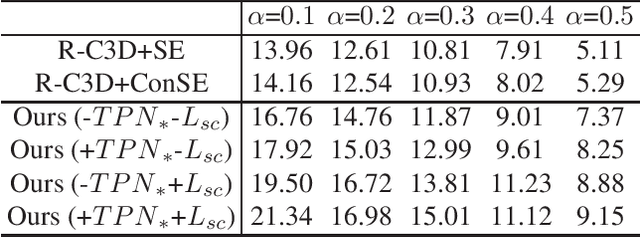
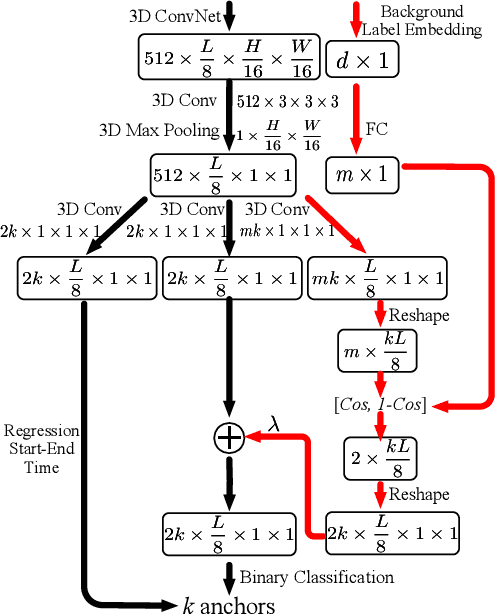

An integral part of video analysis and surveillance is temporal activity detection, which means to simultaneously recognize and localize activities in long untrimmed videos. Currently, the most effective methods of temporal activity detection are based on deep learning, and they typically perform very well with large scale annotated videos for training. However, these methods are limited in real applications due to the unavailable videos about certain activity classes and the time-consuming data annotation. To solve this challenging problem, we propose a novel task setting called zero-shot temporal activity detection (ZSTAD), where activities that have never been seen in training can still be detected. We design an end-to-end deep network based on R-C3D as the architecture for this solution. The proposed network is optimized with an innovative loss function that considers the embeddings of activity labels and their super-classes while learning the common semantics of seen and unseen activities. Experiments on both the THUMOS14 and the Charades datasets show promising performance in terms of detecting unseen activities.
Robot Calligraphy using Pseudospectral Optimal Control in Conjunction with a Novel Dynamic Brush Model
Mar 02, 2020
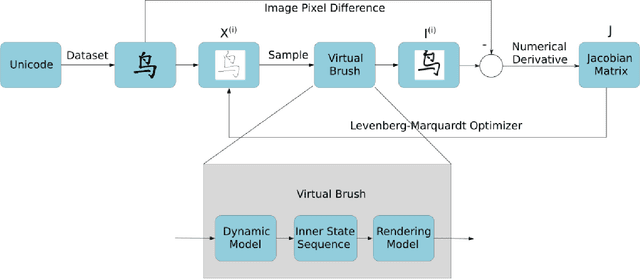
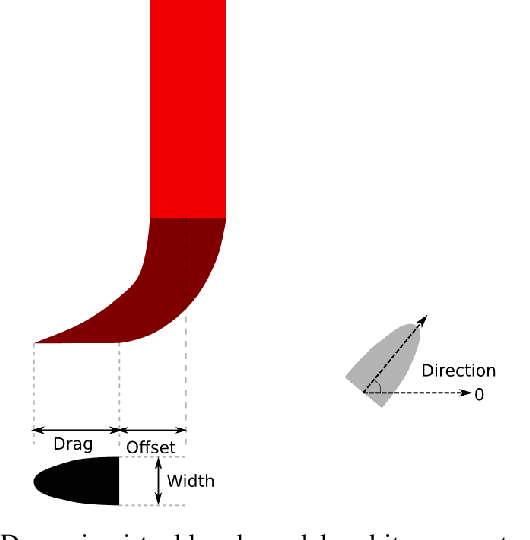
Chinese calligraphy is a unique art form with great artistic value but difficult to master. In this paper, we formulate the calligraphy writing problem as a trajectory optimization problem, and propose an improved virtual brush model for simulating the real writing process. Our approach is inspired by pseudospectral optimal control in that we parameterize the actuator trajectory for each stroke as a Chebyshev polynomial. The proposed dynamic virtual brush model plays a key role in formulating the objective function to be optimized. Our approach shows excellent performance in drawing aesthetically pleasing characters, and does so much more efficiently than previous work, opening up the possibility to achieve real-time closed-loop control.