 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Textual Knowledge for Enhanced Image Clustering
Apr 13, 2026Image clustering aims to group images in an unsupervised fashion. Traditional methods focus on knowledge from visual space, making it difficult to distinguish between visually similar but semantically different classes. Recent advances in vision-language models enable the use of textual knowledge to enhance image clustering. However, most existing methods rely on coarse class labels or simple nouns, overlooking the rich conceptual and attribute-level semantics embedded in textual space. In this paper, we propose a knowledge-enhanced clustering (KEC) method that constructs a hierarchical concept-attribute structured knowledge with the help of large language models (LLMs) to guide clustering. Specifically, we first condense redundant textual labels into abstract concepts and then automatically extract discriminative attributes for each single concept and similar concept pairs, via structured prompts to LLMs. This knowledge is instantiated for each input image to achieve the knowledge-enhanced features. The knowledge-enhanced features with original visual features are adapted to various downstream clustering algorithms. We evaluate KEC on 20 diverse datasets, showing consistent improvements across existing methods using additional textual knowledge. KEC without training outperforms zero-shot CLIP on 14 out of 20 datasets. Furthermore, the naive use of textual knowledge may harm clustering performance, while KEC provides both accuracy and robustness.
HingeMem: Boundary Guided Long-Term Memory with Query Adaptive Retrieval for Scalable Dialogues
Apr 08, 2026Long-term memory is critical for dialogue systems that support continuous, sustainable, and personalized interactions. However, existing methods rely on continuous summarization or OpenIE-based graph construction paired with fixed Top-\textit{k} retrieval, leading to limited adaptability across query categories and high computational overhead. In this paper, we propose HingeMem, a boundary-guided long-term memory that operationalizes event segmentation theory to build an interpretable indexing interface via boundary-triggered hyperedges over four elements: person, time, location, and topic. When any such element changes, HingeMem draws a boundary and writes the current segment, thereby reducing redundant operations and preserving salient context. To enable robust and efficient retrieval under diverse information needs, HingeMem introduces query-adaptive retrieval mechanisms that jointly decide (a) \textit{what to retrieve}: determine the query-conditioned routing over the element-indexed memory; (b) \textit{how much to retrieve}: control the retrieval depth based on the estimated query type. Extensive experiments across LLM scales (from 0.6B to production-tier models; \textit{e.g.}, Qwen3-0.6B to Qwen-Flash) on LOCOMO show that HingeMem achieves approximately $20\%$ relative improvement over strong baselines without query categories specification, while reducing computational cost (68\%$\downarrow$ question answering token cost compared to HippoRAG2). Beyond advancing memory modeling, HingeMem's adaptive retrieval makes it a strong fit for web applications requiring efficient and trustworthy memory over extended interactions.
Embodied Science: Closing the Discovery Loop with Agentic Embodied AI
Mar 20, 2026Artificial intelligence has demonstrated remarkable capability in predicting scientific properties, yet scientific discovery remains an inherently physical, long-horizon pursuit governed by experimental cycles. Most current computational approaches are misaligned with this reality, framing discovery as isolated, task-specific predictions rather than continuous interaction with the physical world. Here, we argue for embodied science, a paradigm that reframes scientific discovery as a closed loop tightly coupling agentic reasoning with physical execution. We propose a unified Perception-Language-Action-Discovery (PLAD) framework, wherein embodied agents perceive experimental environments, reason over scientific knowledge, execute physical interventions, and internalize outcomes to drive subsequent exploration. By grounding computational reasoning in robust physical feedback, this approach bridges the gap between digital prediction and empirical validation, offering a roadmap for autonomous discovery systems in the life and chemical sciences.
CitySeeker: How Do VLMS Explore Embodied Urban Navigation With Implicit Human Needs?
Dec 18, 2025Vision-Language Models (VLMs) have made significant progress in explicit instruction-based navigation; however, their ability to interpret implicit human needs (e.g., "I am thirsty") in dynamic urban environments remains underexplored. This paper introduces CitySeeker, a novel benchmark designed to assess VLMs' spatial reasoning and decision-making capabilities for exploring embodied urban navigation to address implicit needs. CitySeeker includes 6,440 trajectories across 8 cities, capturing diverse visual characteristics and implicit needs in 7 goal-driven scenarios. Extensive experiments reveal that even top-performing models (e.g., Qwen2.5-VL-32B-Instruct) achieve only 21.1% task completion. We find key bottlenecks in error accumulation in long-horizon reasoning, inadequate spatial cognition, and deficient experiential recall. To further analyze them, we investigate a series of exploratory strategies-Backtracking Mechanisms, Enriching Spatial Cognition, and Memory-Based Retrieval (BCR), inspired by human cognitive mapping's emphasis on iterative observation-reasoning cycles and adaptive path optimization. Our analysis provides actionable insights for developing VLMs with robust spatial intelligence required for tackling "last-mile" navigation challenges.
Semi-Infinite Programming for Collision-Avoidance in Optimal and Model Predictive Control
Aug 17, 2025



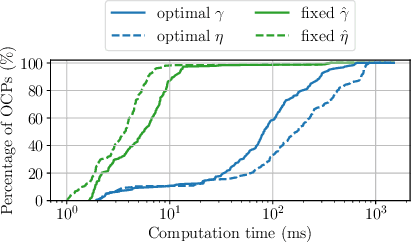
This paper presents a novel approach for collision avoidance in optimal and model predictive control, in which the environment is represented by a large number of points and the robot as a union of padded polygons. The conditions that none of the points shall collide with the robot can be written in terms of an infinite number of constraints per obstacle point. We show that the resulting semi-infinite programming (SIP) optimal control problem (OCP) can be efficiently tackled through a combination of two methods: local reduction and an external active-set method. Specifically, this involves iteratively identifying the closest point obstacles, determining the lower-level distance minimizer among all feasible robot shape parameters, and solving the upper-level finitely-constrained subproblems. In addition, this paper addresses robust collision avoidance in the presence of ellipsoidal state uncertainties. Enforcing constraint satisfaction over all possible uncertainty realizations extends the dimension of constraint infiniteness. The infinitely many constraints arising from translational uncertainty are handled by local reduction together with the robot shape parameterization, while rotational uncertainty is addressed via a backoff reformulation. A controller implemented based on the proposed method is demonstrated on a real-world robot running at 20Hz, enabling fast and collision-free navigation in tight spaces. An application to 3D collision avoidance is also demonstrated in simulation.
Synergizing RAG and Reasoning: A Systematic Review
Apr 22, 2025



Recent breakthroughs in large language models (LLMs), particularly in reasoning capabilities, have propelled Retrieval-Augmented Generation (RAG) to unprecedented levels. By synergizing retrieval mechanisms with advanced reasoning, LLMs can now tackle increasingly complex problems. This paper presents a systematic review of the collaborative interplay between RAG and reasoning, clearly defining "reasoning" within the RAG context. It construct a comprehensive taxonomy encompassing multi-dimensional collaborative objectives, representative paradigms, and technical implementations, and analyze the bidirectional synergy methods. Additionally, we critically evaluate current limitations in RAG assessment, including the absence of intermediate supervision for multi-step reasoning and practical challenges related to cost-risk trade-offs. To bridge theory and practice, we provide practical guidelines tailored to diverse real-world applications. Finally, we identify promising research directions, such as graph-based knowledge integration, hybrid model collaboration, and RL-driven optimization. Overall, this work presents a theoretical framework and practical foundation to advance RAG systems in academia and industry, fostering the next generation of RAG solutions.
StePO-Rec: Towards Personalized Outfit Styling Assistant via Knowledge-Guided Multi-Step Reasoning
Apr 14, 2025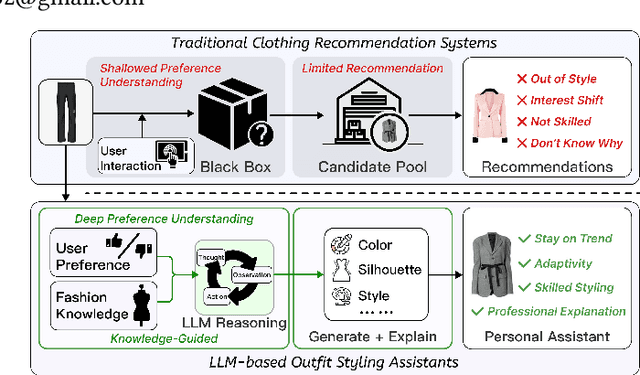



Advancements in Generative AI offers new opportunities for FashionAI, surpassing traditional recommendation systems that often lack transparency and struggle to integrate expert knowledge, leaving the potential for personalized fashion styling remain untapped. To address these challenges, we present PAFA (Principle-Aware Fashion), a multi-granular knowledge base that organizes professional styling expertise into three levels of metadata, domain principles, and semantic relationships. Using PAFA, we develop StePO-Rec, a knowledge-guided method for multi-step outfit recommendation. StePO-Rec provides structured suggestions using a scenario-dimension-attribute framework, employing recursive tree construction to align recommendations with both professional principles and individual preferences. A preference-trend re-ranking system further adapts to fashion trends while maintaining the consistency of the user's original style. Experiments on the widely used personalized outfit dataset IQON show a 28% increase in Recall@1 and 32.8% in MAP. Furthermore, case studies highlight improved explainability, traceability, result reliability, and the seamless integration of expertise and personalization.
Decoding Urban Industrial Complexity: Enhancing Knowledge-Driven Insights via IndustryScopeGPT
Nov 24, 2024



Industrial parks are critical to urban economic growth. Yet, their development often encounters challenges stemming from imbalances between industrial requirements and urban services, underscoring the need for strategic planning and operations. This paper introduces IndustryScopeKG, a pioneering large-scale multi-modal, multi-level industrial park knowledge graph, which integrates diverse urban data including street views, corporate, socio-economic, and geospatial information, capturing the complex relationships and semantics within industrial parks. Alongside this, we present the IndustryScopeGPT framework, which leverages Large Language Models (LLMs) with Monte Carlo Tree Search to enhance tool-augmented reasoning and decision-making in Industrial Park Planning and Operation (IPPO). Our work significantly improves site recommendation and functional planning, demonstrating the potential of combining LLMs with structured datasets to advance industrial park management. This approach sets a new benchmark for intelligent IPPO research and lays a robust foundation for advancing urban industrial development. The dataset and related code are available at https://github.com/Tongji-KGLLM/IndustryScope.
* 9 pages, 6 figures, the 32nd ACM International Conference on Multimedia
Real-Time-Feasible Collision-Free Motion Planning For Ellipsoidal Objects
Sep 18, 2024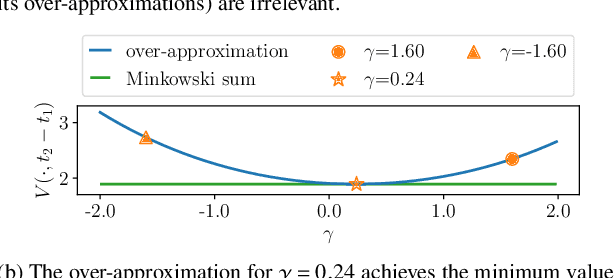
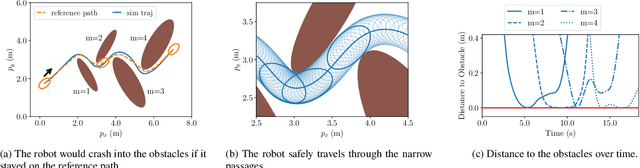
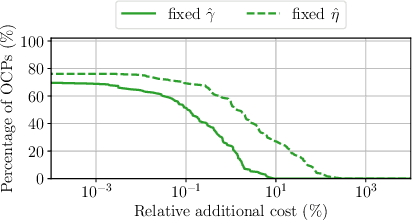
Online planning of collision-free trajectories is a fundamental task for robotics and self-driving car applications. This paper revisits collision avoidance between ellipsoidal objects using differentiable constraints. Two ellipsoids do not overlap if and only if the endpoint of the vector between the center points of the ellipsoids does not lie in the interior of the Minkowski sum of the ellipsoids. This condition is formulated using a parametric over-approximation of the Minkowski sum, which can be made tight in any given direction. The resulting collision avoidance constraint is included in an optimal control problem (OCP) and evaluated in comparison to the separating-hyperplane approach. Not only do we observe that the Minkowski-sum formulation is computationally more efficient in our experiments, but also that using pre-determined over-approximation parameters based on warm-start trajectories leads to a very limited increase in suboptimality. This gives rise to a novel real-time scheme for collision-free motion planning with model predictive control (MPC). Both the real-time feasibility and the effectiveness of the constraint formulation are demonstrated in challenging real-world experiments.
Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
Jul 26, 2024



Retrieval-augmented Generation (RAG) has markedly enhanced the capabilities of Large Language Models (LLMs) in tackling knowledge-intensive tasks. The increasing demands of application scenarios have driven the evolution of RAG, leading to the integration of advanced retrievers, LLMs and other complementary technologies, which in turn has amplified the intricacy of RAG systems. However, the rapid advancements are outpacing the foundational RAG paradigm, with many methods struggling to be unified under the process of "retrieve-then-generate". In this context, this paper examines the limitations of the existing RAG paradigm and introduces the modular RAG framework. By decomposing complex RAG systems into independent modules and specialized operators, it facilitates a highly reconfigurable framework. Modular RAG transcends the traditional linear architecture, embracing a more advanced design that integrates routing, scheduling, and fusion mechanisms. Drawing on extensive research, this paper further identifies prevalent RAG patterns-linear, conditional, branching, and looping-and offers a comprehensive analysis of their respective implementation nuances. Modular RAG presents innovative opportunities for the conceptualization and deployment of RAG systems. Finally, the paper explores the potential emergence of new operators and paradigms, establishing a solid theoretical foundation and a practical roadmap for the continued evolution and practical deployment of RAG technologies.