 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-DRAGON: Geospatial Reasoning and Dynamic Planning for Retrieval-Augmented Outdoor Navigation
May 25, 2026Autonomous ground robots operating in large-scale outdoor environments require both robust long-range navigation and fine-grained ''last-mile'' exploration. Current advances in visual-language navigation (VLN) work well at short-range tasks, lacking geospatial grounding for long-distance missions. Some OpenStreetMap (OSM)-based methods relying on cloud-based Large Language Models (LLMs) are prone to factual hallucination and cannot conduct ''last-mile'' exploration based on human instruction. To address these challenges, we present G-DRAGON, a retrieval-augmented framework for outdoor, open-world navigation. This framework maps natural-language commands to versioned, local OSM entities via generative retrieval based on lightweight LLM, yielding accurate coordinates for global route planning. A high-level planning module bridges global topological routes with the SLAM system, projecting geospatial waypoints into the robot's navigable frame. For the ''last mile," the framework transitions to frontier-based exploration and open-set semantic voxel mapping to localize open-vocabulary targets. Experimental results in simulation demonstrate our framework outperforms state-of-the-art baselines. Furthermore, we validate the system in unseen real-world urban environments on an Unmanned Ground Vehicle (UGV), successfully completing person-search missions with trajectories of up to 500m.
C2T-ID: Converting Semantic Codebooks to Textual Document Identifiers for Generative Search
Oct 22, 2025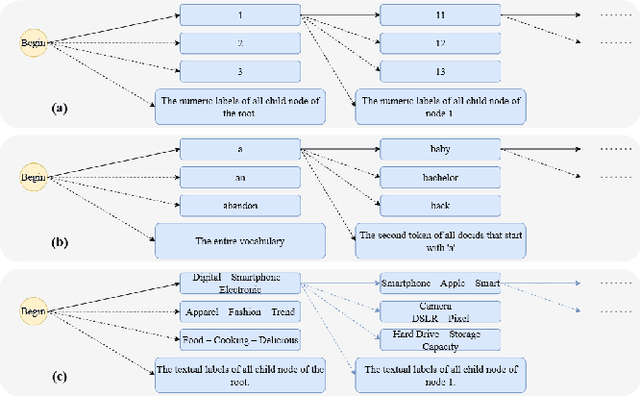
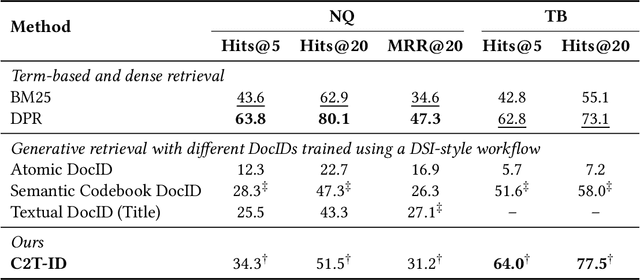
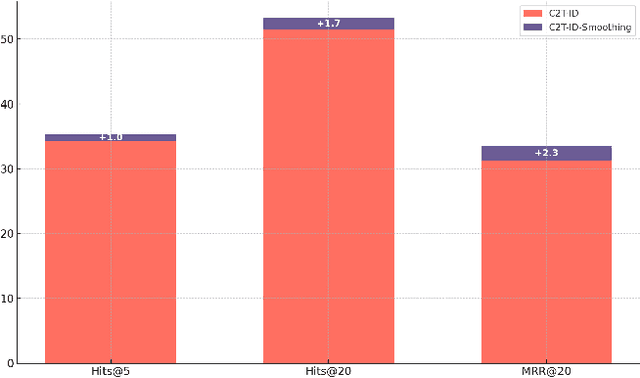
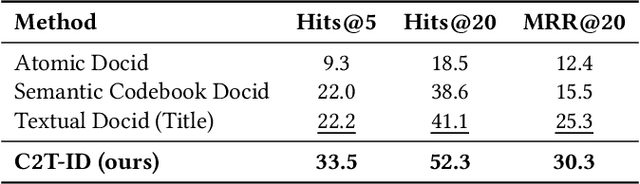
Designing document identifiers (docids) that carry rich semantic information while maintaining tractable search spaces is a important challenge in generative retrieval (GR). Popular codebook methods address this by building a hierarchical semantic tree and constraining generation to its child nodes, yet their numeric identifiers cannot leverage the large language model's pretrained natural language understanding. Conversely, using text as docid provides more semantic expressivity but inflates the decoding space, making the system brittle to early-step errors. To resolve this trade-off, we propose C2T-ID: (i) first construct semantic numerical docid via hierarchical clustering; (ii) then extract high-frequency metadata keywords and iteratively replace each numeric label with its cluster's top-K keywords; and (iii) an optional two-level semantic smoothing step further enhances the fluency of C2T-ID. Experiments on Natural Questions and Taobao's product search demonstrate that C2T-ID significantly outperforms atomic, semantic codebook, and pure-text docid baselines, demonstrating its effectiveness in balancing semantic expressiveness with search space constraints.
Does Generative Retrieval Overcome the Limitations of Dense Retrieval?
Sep 26, 2025Generative retrieval (GR) has emerged as a new paradigm in neural information retrieval, offering an alternative to dense retrieval (DR) by directly generating identifiers of relevant documents. In this paper, we theoretically and empirically investigate how GR fundamentally diverges from DR in both learning objectives and representational capacity. GR performs globally normalized maximum-likelihood optimization and encodes corpus and relevance information directly in the model parameters, whereas DR adopts locally normalized objectives and represents the corpus with external embeddings before computing similarity via a bilinear interaction. Our analysis suggests that, under scaling, GR can overcome the inherent limitations of DR, yielding two major benefits. First, with larger corpora, GR avoids the sharp performance degradation caused by the optimization drift induced by DR's local normalization. Second, with larger models, GR's representational capacity scales with parameter size, unconstrained by the global low-rank structure that limits DR. We validate these theoretical insights through controlled experiments on the Natural Questions and MS MARCO datasets, across varying negative sampling strategies, embedding dimensions, and model scales. But despite its theoretical advantages, GR does not universally outperform DR in practice. We outline directions to bridge the gap between GR's theoretical potential and practical performance, providing guidance for future research in scalable and robust generative retrieval.
Physics-Informed Statistical Modeling for Wildfire Aerosols Process Using Multi-Source Geostationary Satellite Remote-Sensing Data Streams
Jun 23, 2022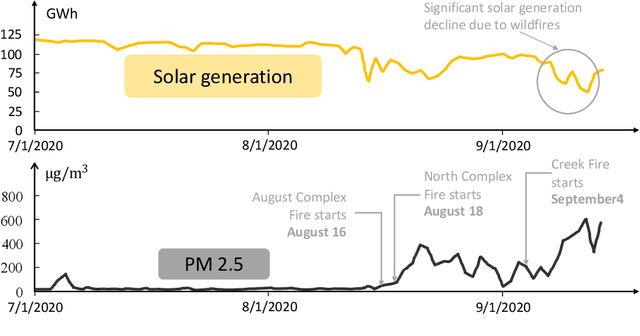
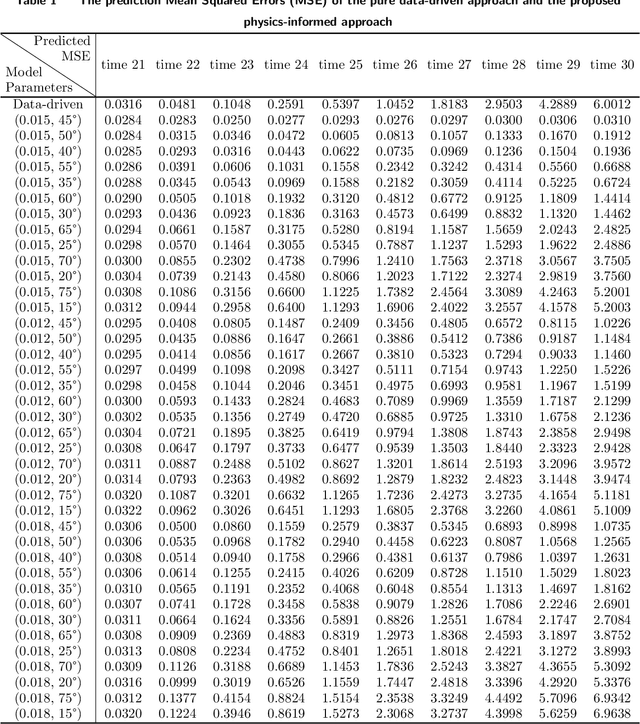
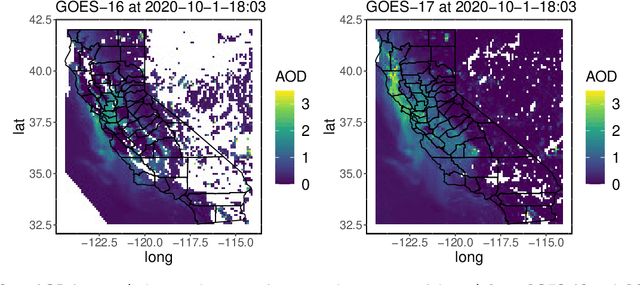
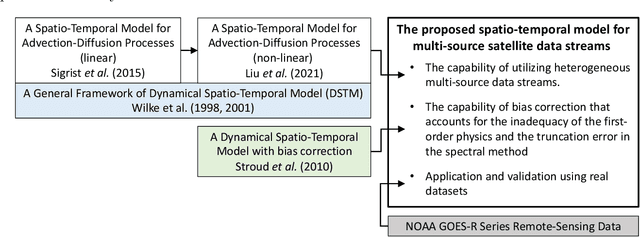
Increasingly frequent wildfires significantly affect solar energy production as the atmospheric aerosols generated by wildfires diminish the incoming solar radiation to the earth. Atmospheric aerosols are measured by Aerosol Optical Depth (AOD), and AOD data streams can be retrieved and monitored by geostationary satellites. However, multi-source remote-sensing data streams often present heterogeneous characteristics, including different data missing rates, measurement errors, systematic biases, and so on. To accurately estimate and predict the underlying AOD propagation process, there exist practical needs and theoretical interests to propose a physics-informed statistical approach for modeling wildfire AOD propagation by simultaneously utilizing, or fusing, multi-source heterogeneous satellite remote-sensing data streams. Leveraging a spectral approach, the proposed approach integrates multi-source satellite data streams with a fundamental advection-diffusion equation that governs the AOD propagation process. A bias correction process is included in the statistical model to account for the bias of the physics model and the truncation error of the Fourier series. The proposed approach is applied to California wildfires AOD data streams obtained from the National Oceanic and Atmospheric Administration. Comprehensive numerical examples are provided to demonstrate the predictive capabilities and model interpretability of the proposed approach. Computer code has been made available on GitHub.
Robust Matrix Completion State Estimation in Distribution Systems
Mar 12, 2019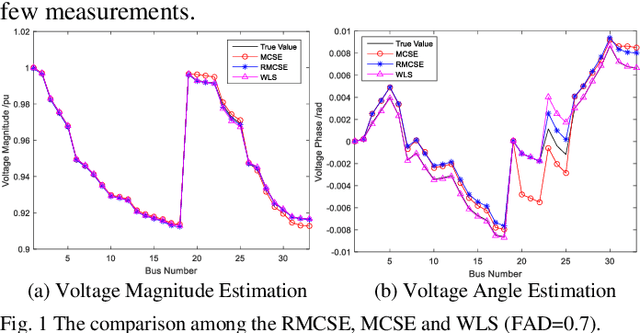
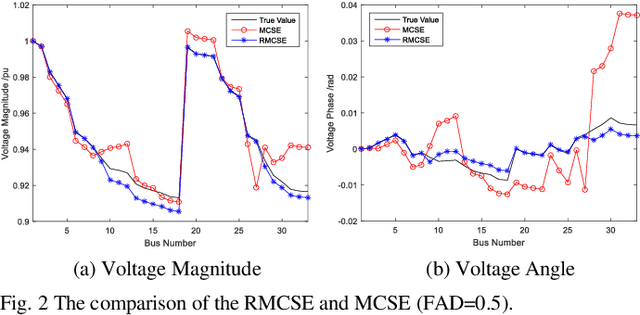
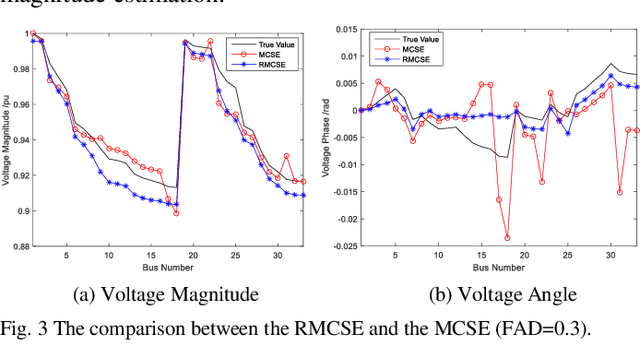
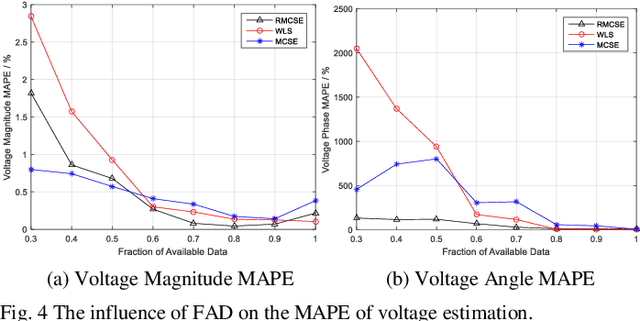
Due to the insufficient measurements in the distribution system state estimation (DSSE), full observability and redundant measurements are difficult to achieve without using the pseudo measurements. The matrix completion state estimation (MCSE) combines the matrix completion and power system model to estimate voltage by exploring the low-rank characteristics of the matrix. This paper proposes a robust matrix completion state estimation (RMCSE) to estimate the voltage in a distribution system under a low-observability condition. Tradition state estimation weighted least squares (WLS) method requires full observability to calculate the states and needs redundant measurements to proceed a bad data detection. The proposed method improves the robustness of the MCSE to bad data by minimizing the rank of the matrix and measurements residual with different weights. It can estimate the system state in a low-observability system and has robust estimates without the bad data detection process in the face of multiple bad data. The method is numerically evaluated on the IEEE 33-node radial distribution system. The estimation performance and robustness of RMCSE are compared with the WLS with the largest normalized residual bad data identification (WLS-LNR), and the MCSE.