 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Autoregressive Density Estimation: Towards Learning to Learn Distributions
Feb 28, 2018
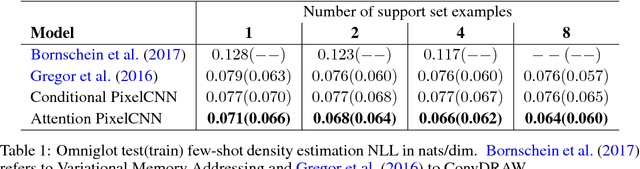
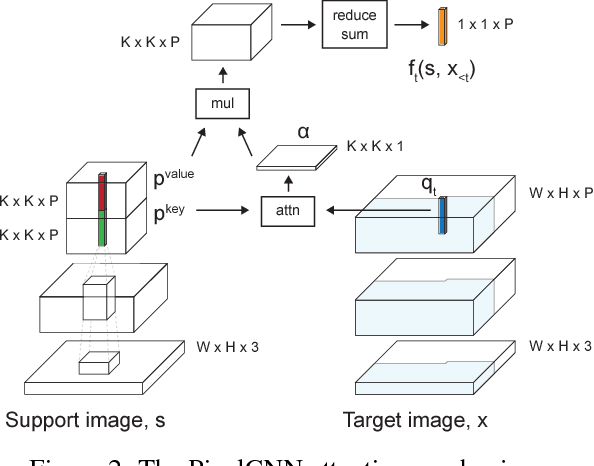
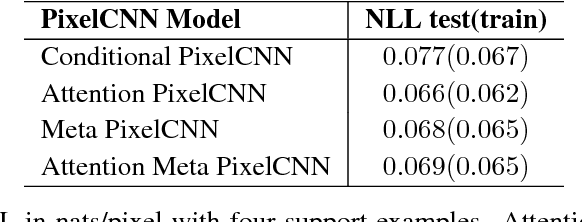
Deep autoregressive models have shown state-of-the-art performance in density estimation for natural images on large-scale datasets such as ImageNet. However, such models require many thousands of gradient-based weight updates and unique image examples for training. Ideally, the models would rapidly learn visual concepts from only a handful of examples, similar to the manner in which humans learns across many vision tasks. In this paper, we show how 1) neural attention and 2) meta learning techniques can be used in combination with autoregressive models to enable effective few-shot density estimation. Our proposed modifications to PixelCNN result in state-of-the art few-shot density estimation on the Omniglot dataset. Furthermore, we visualize the learned attention policy and find that it learns intuitive algorithms for simple tasks such as image mirroring on ImageNet and handwriting on Omniglot without supervision. Finally, we extend the model to natural images and demonstrate few-shot image generation on the Stanford Online Products dataset.
Robust Imitation of Diverse Behaviors
Jul 14, 2017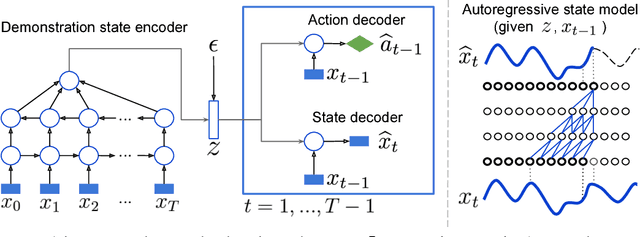
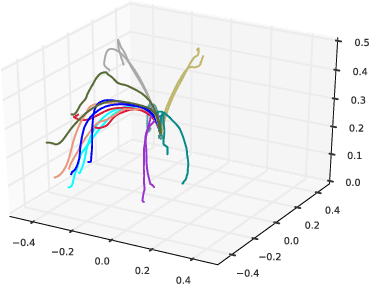
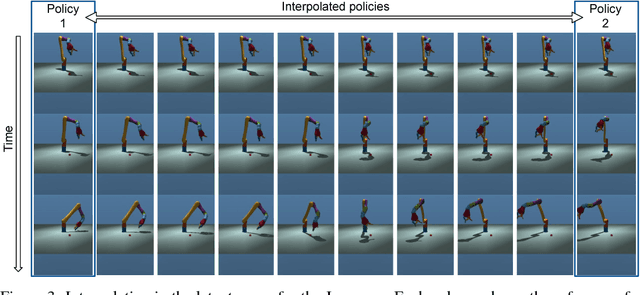
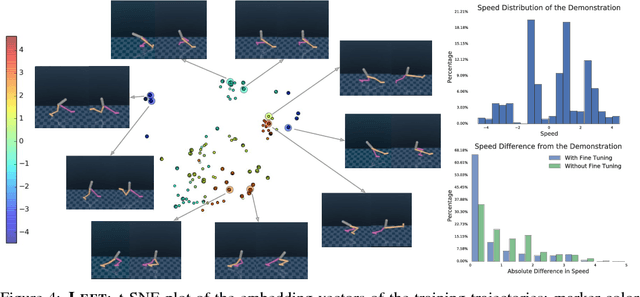
Deep generative models have recently shown great promise in imitation learning for motor control. Given enough data, even supervised approaches can do one-shot imitation learning; however, they are vulnerable to cascading failures when the agent trajectory diverges from the demonstrations. Compared to purely supervised methods, Generative Adversarial Imitation Learning (GAIL) can learn more robust controllers from fewer demonstrations, but is inherently mode-seeking and more difficult to train. In this paper, we show how to combine the favourable aspects of these two approaches. The base of our model is a new type of variational autoencoder on demonstration trajectories that learns semantic policy embeddings. We show that these embeddings can be learned on a 9 DoF Jaco robot arm in reaching tasks, and then smoothly interpolated with a resulting smooth interpolation of reaching behavior. Leveraging these policy representations, we develop a new version of GAIL that (1) is much more robust than the purely-supervised controller, especially with few demonstrations, and (2) avoids mode collapse, capturing many diverse behaviors when GAIL on its own does not. We demonstrate our approach on learning diverse gaits from demonstration on a 2D biped and a 62 DoF 3D humanoid in the MuJoCo physics environment.
Parallel Multiscale Autoregressive Density Estimation
Mar 10, 2017

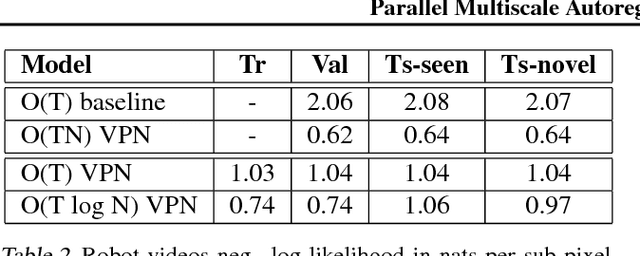
PixelCNN achieves state-of-the-art results in density estimation for natural images. Although training is fast, inference is costly, requiring one network evaluation per pixel; O(N) for N pixels. This can be sped up by caching activations, but still involves generating each pixel sequentially. In this work, we propose a parallelized PixelCNN that allows more efficient inference by modeling certain pixel groups as conditionally independent. Our new PixelCNN model achieves competitive density estimation and orders of magnitude speedup - O(log N) sampling instead of O(N) - enabling the practical generation of 512x512 images. We evaluate the model on class-conditional image generation, text-to-image synthesis, and action-conditional video generation, showing that our model achieves the best results among non-pixel-autoregressive density models that allow efficient sampling.
SSD: Single Shot MultiBox Detector
Dec 29, 2016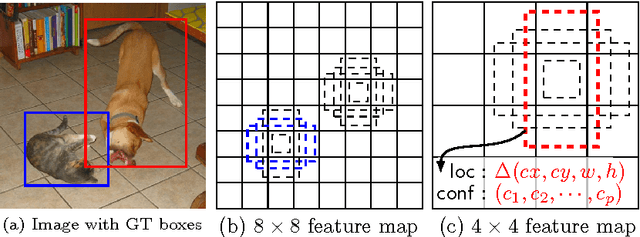
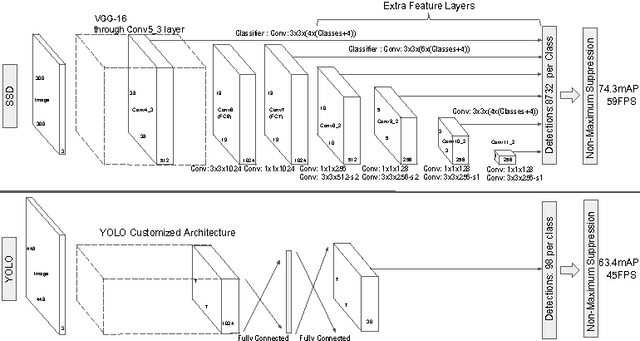

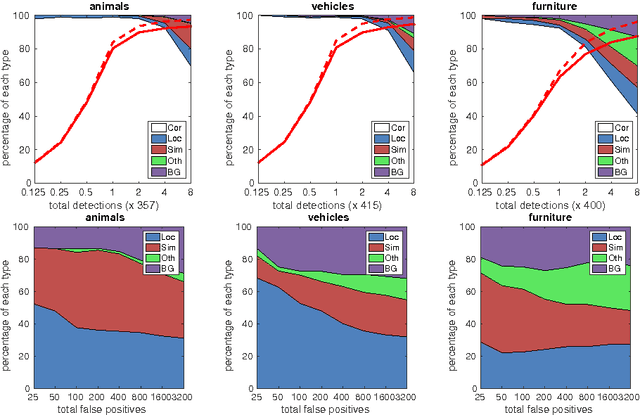
We present a method for detecting objects in images using a single deep neural network. Our approach, named SSD, discretizes the output space of bounding boxes into a set of default boxes over different aspect ratios and scales per feature map location. At prediction time, the network generates scores for the presence of each object category in each default box and produces adjustments to the box to better match the object shape. Additionally, the network combines predictions from multiple feature maps with different resolutions to naturally handle objects of various sizes. Our SSD model is simple relative to methods that require object proposals because it completely eliminates proposal generation and subsequent pixel or feature resampling stage and encapsulates all computation in a single network. This makes SSD easy to train and straightforward to integrate into systems that require a detection component. Experimental results on the PASCAL VOC, MS COCO, and ILSVRC datasets confirm that SSD has comparable accuracy to methods that utilize an additional object proposal step and is much faster, while providing a unified framework for both training and inference. Compared to other single stage methods, SSD has much better accuracy, even with a smaller input image size. For $300\times 300$ input, SSD achieves 72.1% mAP on VOC2007 test at 58 FPS on a Nvidia Titan X and for $500\times 500$ input, SSD achieves 75.1% mAP, outperforming a comparable state of the art Faster R-CNN model. Code is available at https://github.com/weiliu89/caffe/tree/ssd .
Learning What and Where to Draw
Oct 08, 2016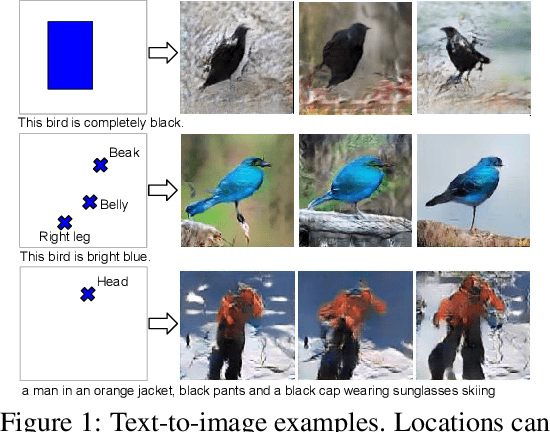
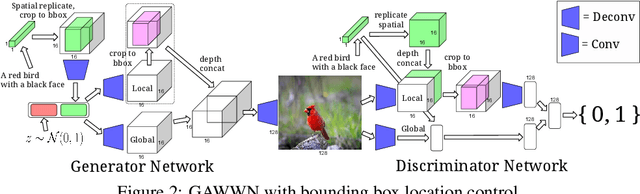
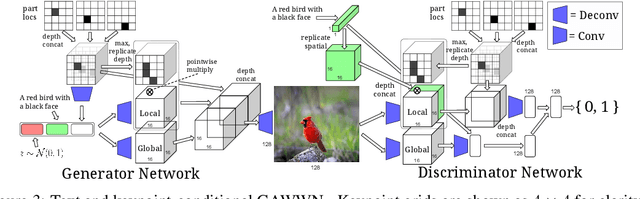
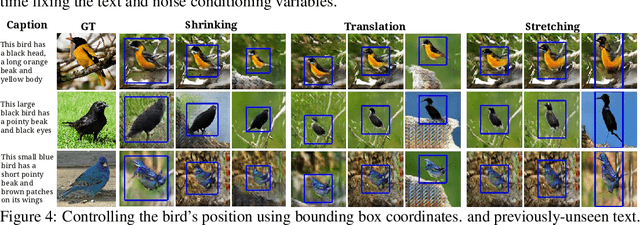
Generative Adversarial Networks (GANs) have recently demonstrated the capability to synthesize compelling real-world images, such as room interiors, album covers, manga, faces, birds, and flowers. While existing models can synthesize images based on global constraints such as a class label or caption, they do not provide control over pose or object location. We propose a new model, the Generative Adversarial What-Where Network (GAWWN), that synthesizes images given instructions describing what content to draw in which location. We show high-quality 128 x 128 image synthesis on the Caltech-UCSD Birds dataset, conditioned on both informal text descriptions and also object location. Our system exposes control over both the bounding box around the bird and its constituent parts. By modeling the conditional distributions over part locations, our system also enables conditioning on arbitrary subsets of parts (e.g. only the beak and tail), yielding an efficient interface for picking part locations. We also show preliminary results on the more challenging domain of text- and location-controllable synthesis of images of human actions on the MPII Human Pose dataset.
Generative Adversarial Text to Image Synthesis
Jun 05, 2016
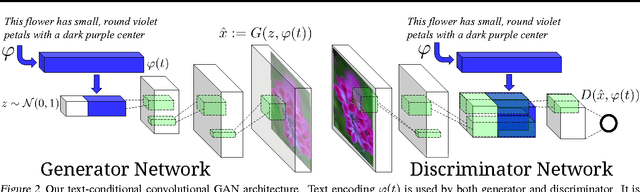

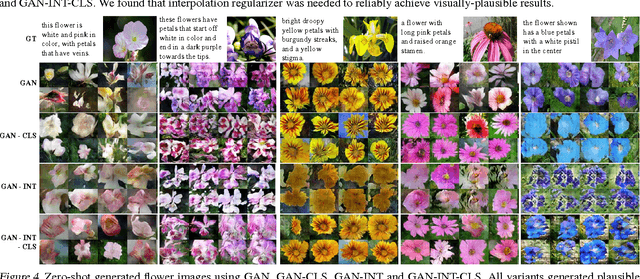
Automatic synthesis of realistic images from text would be interesting and useful, but current AI systems are still far from this goal. However, in recent years generic and powerful recurrent neural network architectures have been developed to learn discriminative text feature representations. Meanwhile, deep convolutional generative adversarial networks (GANs) have begun to generate highly compelling images of specific categories, such as faces, album covers, and room interiors. In this work, we develop a novel deep architecture and GAN formulation to effectively bridge these advances in text and image model- ing, translating visual concepts from characters to pixels. We demonstrate the capability of our model to generate plausible images of birds and flowers from detailed text descriptions.
Learning Deep Representations of Fine-grained Visual Descriptions
May 17, 2016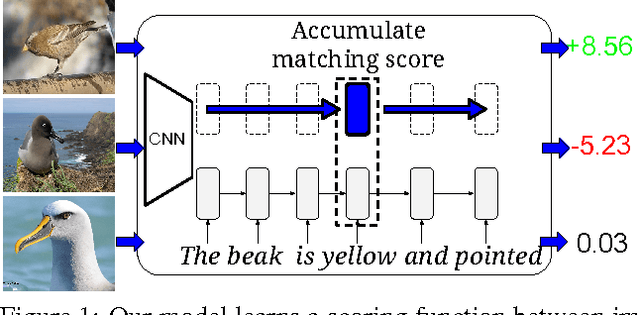
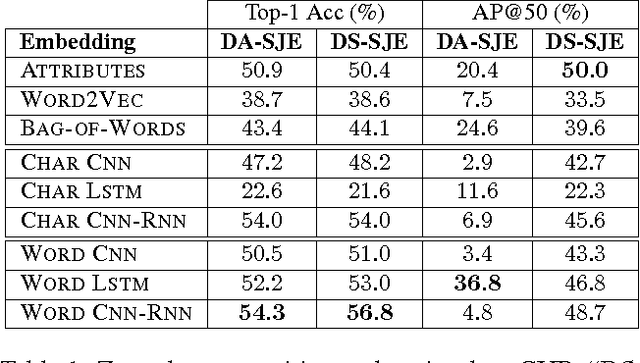
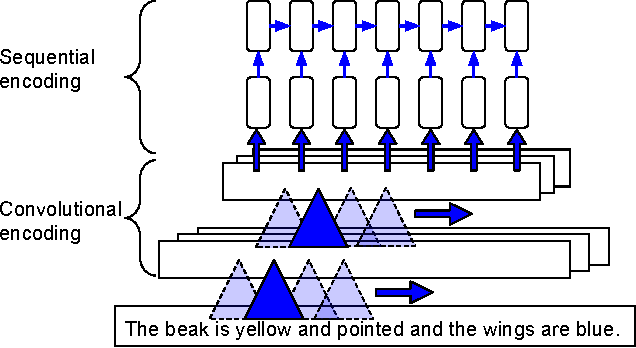
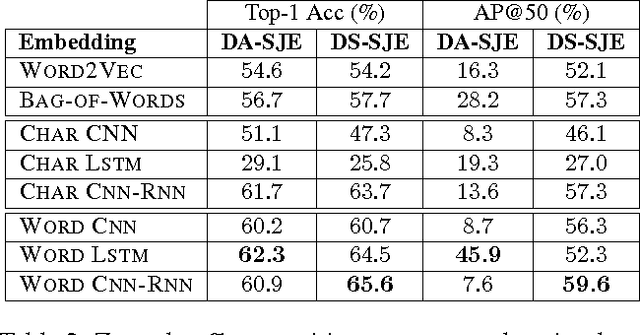
State-of-the-art methods for zero-shot visual recognition formulate learning as a joint embedding problem of images and side information. In these formulations the current best complement to visual features are attributes: manually encoded vectors describing shared characteristics among categories. Despite good performance, attributes have limitations: (1) finer-grained recognition requires commensurately more attributes, and (2) attributes do not provide a natural language interface. We propose to overcome these limitations by training neural language models from scratch; i.e. without pre-training and only consuming words and characters. Our proposed models train end-to-end to align with the fine-grained and category-specific content of images. Natural language provides a flexible and compact way of encoding only the salient visual aspects for distinguishing categories. By training on raw text, our model can do inference on raw text as well, providing humans a familiar mode both for annotation and retrieval. Our model achieves strong performance on zero-shot text-based image retrieval and significantly outperforms the attribute-based state-of-the-art for zero-shot classification on the Caltech UCSD Birds 200-2011 dataset.
Neural Programmer-Interpreters
Feb 29, 2016
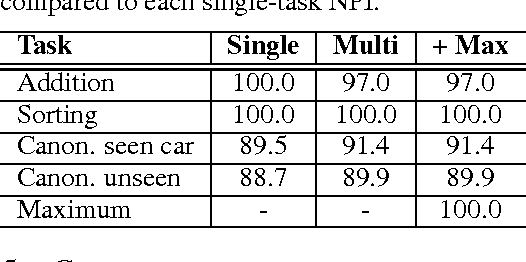
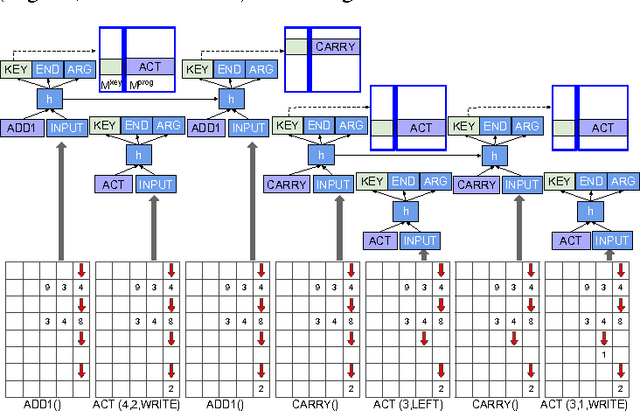
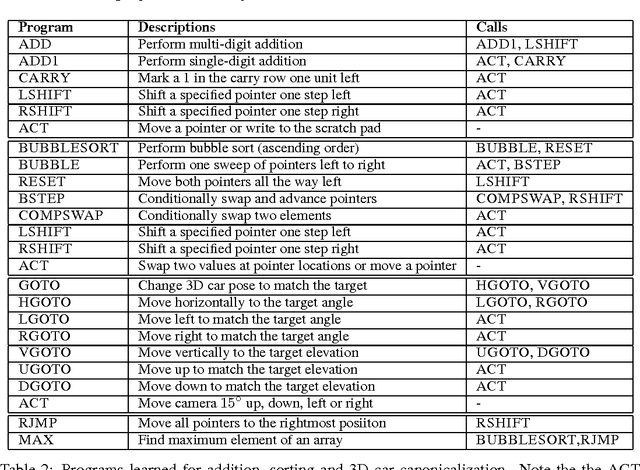
We propose the neural programmer-interpreter (NPI): a recurrent and compositional neural network that learns to represent and execute programs. NPI has three learnable components: a task-agnostic recurrent core, a persistent key-value program memory, and domain-specific encoders that enable a single NPI to operate in multiple perceptually diverse environments with distinct affordances. By learning to compose lower-level programs to express higher-level programs, NPI reduces sample complexity and increases generalization ability compared to sequence-to-sequence LSTMs. The program memory allows efficient learning of additional tasks by building on existing programs. NPI can also harness the environment (e.g. a scratch pad with read-write pointers) to cache intermediate results of computation, lessening the long-term memory burden on recurrent hidden units. In this work we train the NPI with fully-supervised execution traces; each program has example sequences of calls to the immediate subprograms conditioned on the input. Rather than training on a huge number of relatively weak labels, NPI learns from a small number of rich examples. We demonstrate the capability of our model to learn several types of compositional programs: addition, sorting, and canonicalizing 3D models. Furthermore, a single NPI learns to execute these programs and all 21 associated subprograms.
Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis
Jan 05, 2016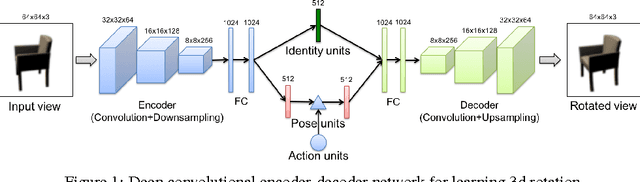
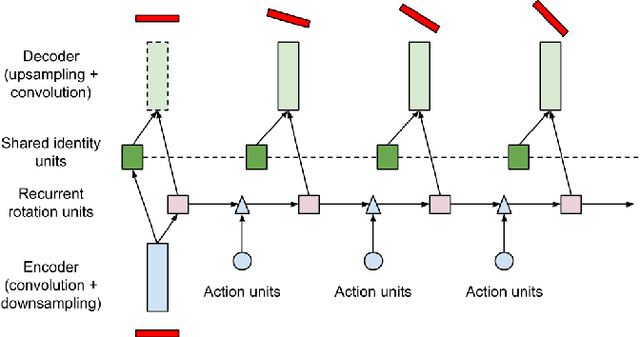
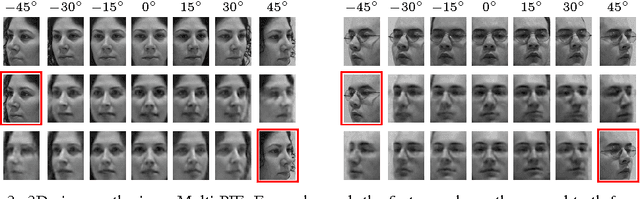
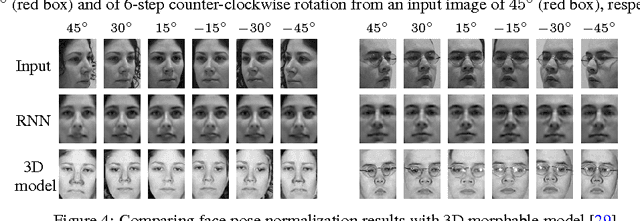
An important problem for both graphics and vision is to synthesize novel views of a 3D object from a single image. This is particularly challenging due to the partial observability inherent in projecting a 3D object onto the image space, and the ill-posedness of inferring object shape and pose. However, we can train a neural network to address the problem if we restrict our attention to specific object categories (in our case faces and chairs) for which we can gather ample training data. In this paper, we propose a novel recurrent convolutional encoder-decoder network that is trained end-to-end on the task of rendering rotated objects starting from a single image. The recurrent structure allows our model to capture long-term dependencies along a sequence of transformations. We demonstrate the quality of its predictions for human faces on the Multi-PIE dataset and for a dataset of 3D chair models, and also show its ability to disentangle latent factors of variation (e.g., identity and pose) without using full supervision.
Scalable, High-Quality Object Detection
Dec 09, 2015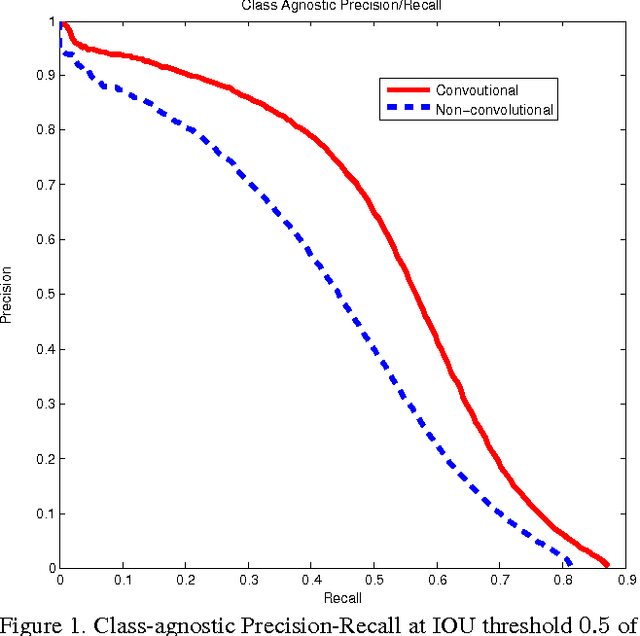
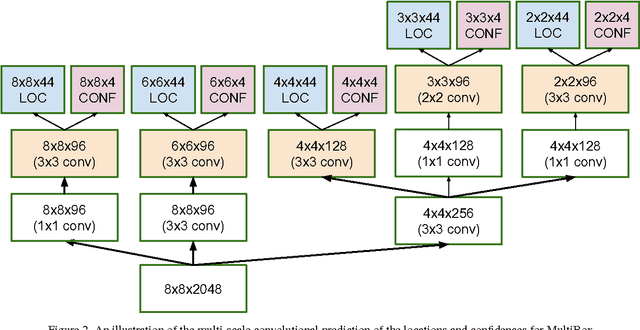
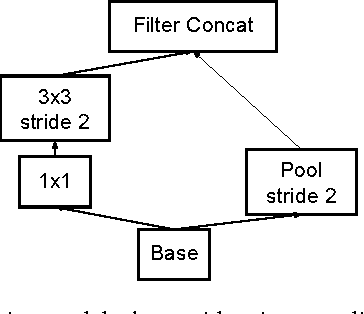

Current high-quality object detection approaches use the scheme of salience-based object proposal methods followed by post-classification using deep convolutional features. This spurred recent research in improving object proposal methods. However, domain agnostic proposal generation has the principal drawback that the proposals come unranked or with very weak ranking, making it hard to trade-off quality for running time. This raises the more fundamental question of whether high-quality proposal generation requires careful engineering or can be derived just from data alone. We demonstrate that learning-based proposal methods can effectively match the performance of hand-engineered methods while allowing for very efficient runtime-quality trade-offs. Using the multi-scale convolutional MultiBox (MSC-MultiBox) approach, we substantially advance the state-of-the-art on the ILSVRC 2014 detection challenge data set, with $0.5$ mAP for a single model and $0.52$ mAP for an ensemble of two models. MSC-Multibox significantly improves the proposal quality over its predecessor MultiBox~method: AP increases from $0.42$ to $0.53$ for the ILSVRC detection challenge. Finally, we demonstrate improved bounding-box recall compared to Multiscale Combinatorial Grouping with less proposals on the Microsoft-COCO data set.