 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting to 99% Accuracy in Interactive Segmentation
Mar 17, 2020

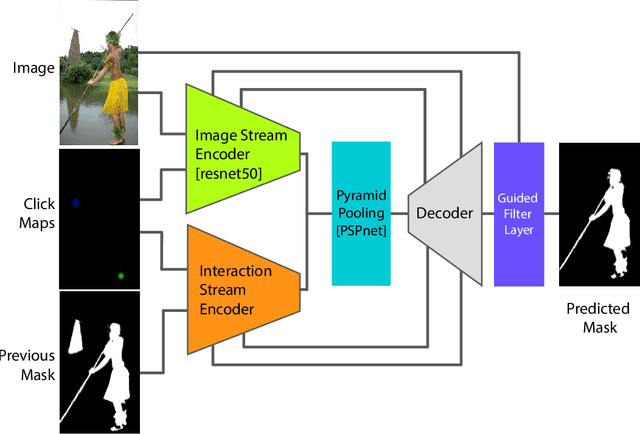
Interactive object cutout tools are the cornerstone of the image editing workflow. Recent deep-learning based interactive segmentation algorithms have made significant progress in handling complex images and rough binary selections can typically be obtained with just a few clicks. Yet, deep learning techniques tend to plateau once this rough selection has been reached. In this work, we interpret this plateau as the inability of current algorithms to sufficiently leverage each user interaction and also as the limitations of current training/testing datasets. We propose a novel interactive architecture and a novel training scheme that are both tailored to better exploit the user workflow. We also show that significant improvements can be further gained by introducing a synthetic training dataset that is specifically designed for complex object boundaries. Comprehensive experiments support our approach, and our network achieves state of the art performance.
Deep Visual Template-Free Form Parsing
Sep 18, 2019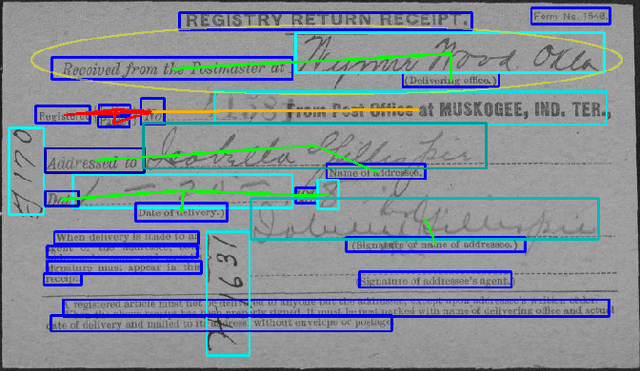


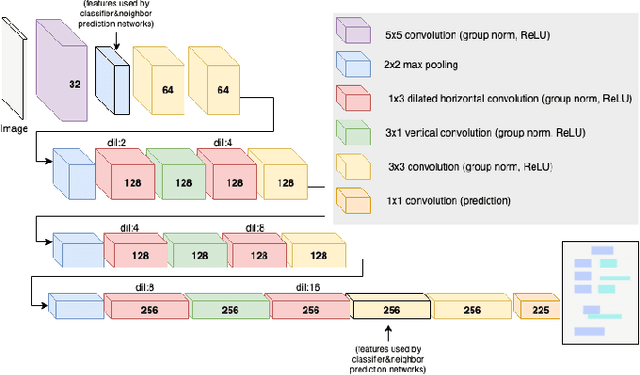
Automatic, template-free extraction of information from form images is challenging due to the variety of form layouts. This is even more challenging for historical forms due to noise and degradation. A crucial part of the extraction process is associating input text with pre-printed labels. We present a learned, template-free solution to detecting pre-printed text and input text/handwriting and predicting pair-wise relationships between them. While previous approaches to this problem have been focused on clean images and clear layouts, we show our approach is effective in the domain of noisy, degraded, and varied form images. We introduce a new dataset of historical form images (late 1800s, early 1900s) for training and validating our approach. Our method uses a convolutional network to detect pre-printed text and input text lines. We pool features from the detection network to classify possible relationships in a language-agnostic way. We show that our proposed pairing method outperforms heuristic rules and that visual features are critical to obtaining high accuracy.
Unconstrained Foreground Object Search
Aug 10, 2019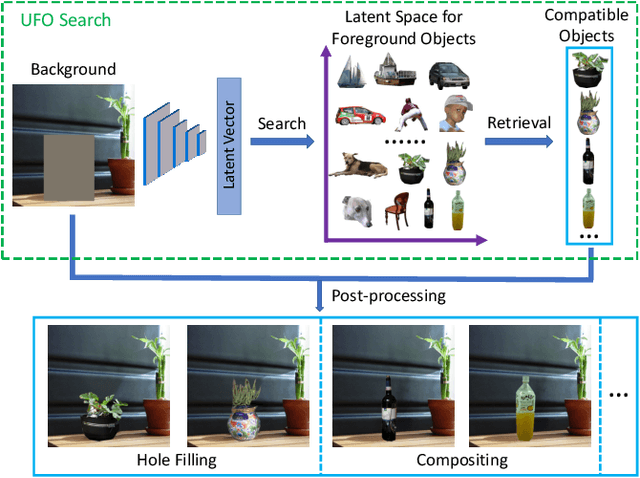
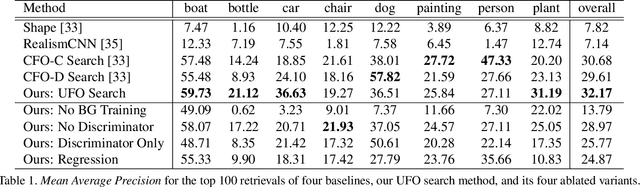
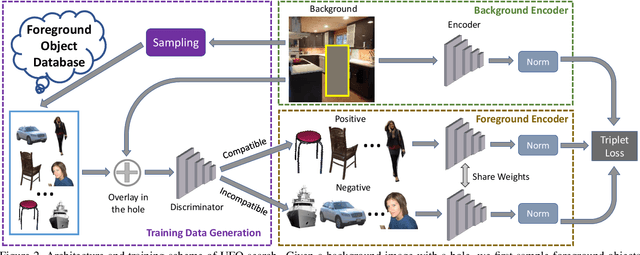
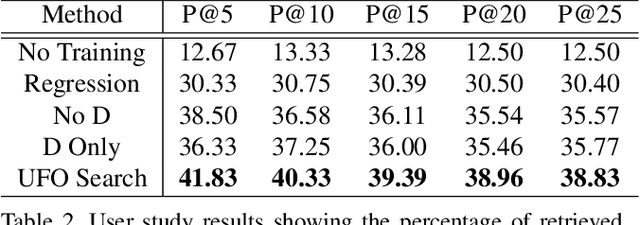
Many people search for foreground objects to use when editing images. While existing methods can retrieve candidates to aid in this, they are constrained to returning objects that belong to a pre-specified semantic class. We instead propose a novel problem of unconstrained foreground object (UFO) search and introduce a solution that supports efficient search by encoding the background image in the same latent space as the candidate foreground objects. A key contribution of our work is a cost-free, scalable approach for creating a large-scale training dataset with a variety of foreground objects of differing semantic categories per image location. Quantitative and human-perception experiments with two diverse datasets demonstrate the advantage of our UFO search solution over related baselines.
Answering Questions about Data Visualizations using Efficient Bimodal Fusion
Aug 05, 2019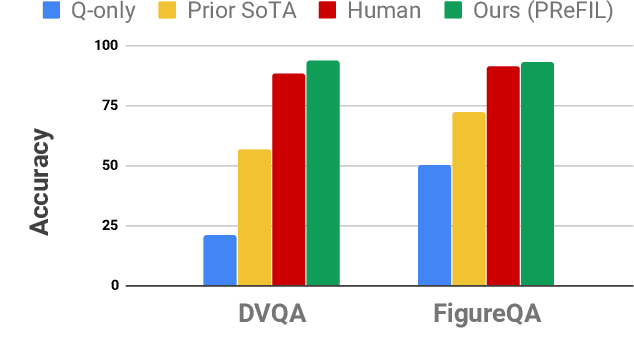

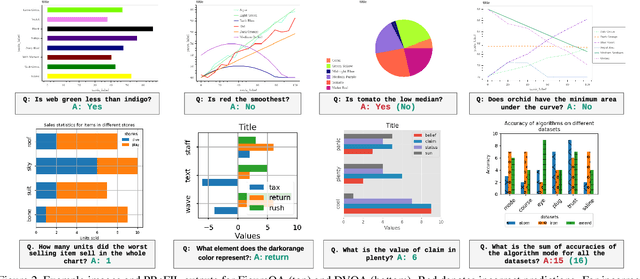
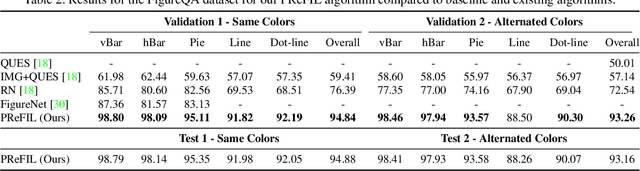
Chart question answering (CQA) is a newly proposed visual question answering (VQA) task where an algorithm must answer questions about data visualizations, e.g. bar charts, pie charts, and line graphs. CQA requires capabilities that natural-image VQA algorithms lack: fine-grained measurements, optical character recognition, and handling out-of-vocabulary words in both questions and answers. Without modifications, state-of-the-art VQA algorithms perform poorly on this task. Here, we propose a novel CQA algorithm called parallel recurrent fusion of image and language (PReFIL). PReFIL first learns bimodal embeddings by fusing question and image features and then intelligently aggregates these learned embeddings to answer the given question. Despite its simplicity, PReFIL greatly surpasses state-of-the art systems and human baselines on both the FigureQA and DVQA datasets. Additionally, we demonstrate that PReFIL can be used to reconstruct tables by asking a series of questions about a chart.
Figure Captioning with Reasoning and Sequence-Level Training
Jun 07, 2019
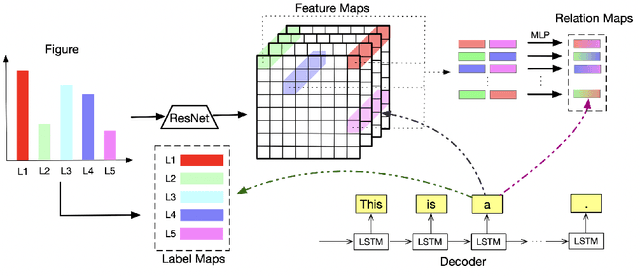
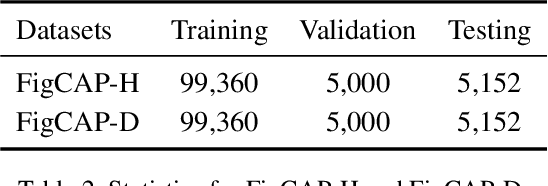
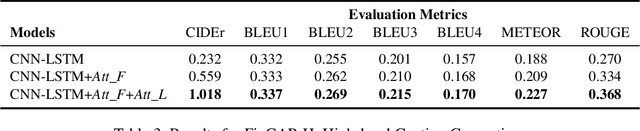
Figures, such as bar charts, pie charts, and line plots, are widely used to convey important information in a concise format. They are usually human-friendly but difficult for computers to process automatically. In this work, we investigate the problem of figure captioning where the goal is to automatically generate a natural language description of the figure. While natural image captioning has been studied extensively, figure captioning has received relatively little attention and remains a challenging problem. First, we introduce a new dataset for figure captioning, FigCAP, based on FigureQA. Second, we propose two novel attention mechanisms. To achieve accurate generation of labels in figures, we propose Label Maps Attention. To model the relations between figure labels, we propose Relation Maps Attention. Third, we use sequence-level training with reinforcement learning in order to directly optimizes evaluation metrics, which alleviates the exposure bias issue and further improves the models in generating long captions. Extensive experiments show that the proposed method outperforms the baselines, thus demonstrating a significant potential for the automatic captioning of vast repositories of figures.
YouTube-VOS: Sequence-to-Sequence Video Object Segmentation
Sep 03, 2018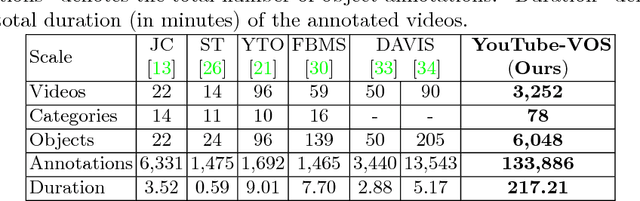

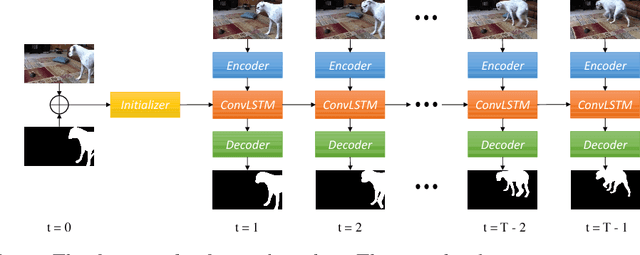
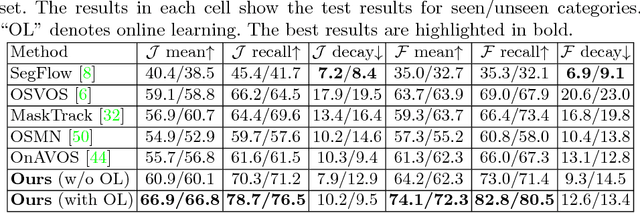
Learning long-term spatial-temporal features are critical for many video analysis tasks. However, existing video segmentation methods predominantly rely on static image segmentation techniques, and methods capturing temporal dependency for segmentation have to depend on pretrained optical flow models, leading to suboptimal solutions for the problem. End-to-end sequential learning to explore spatial-temporal features for video segmentation is largely limited by the scale of available video segmentation datasets, i.e., even the largest video segmentation dataset only contains 90 short video clips. To solve this problem, we build a new large-scale video object segmentation dataset called YouTube Video Object Segmentation dataset (YouTube-VOS). Our dataset contains 3,252 YouTube video clips and 78 categories including common objects and human activities. This is by far the largest video object segmentation dataset to our knowledge and we have released it at https://youtube-vos.org. Based on this dataset, we propose a novel sequence-to-sequence network to fully exploit long-term spatial-temporal information in videos for segmentation. We demonstrate that our method is able to achieve the best results on our YouTube-VOS test set and comparable results on DAVIS 2016 compared to the current state-of-the-art methods. Experiments show that the large scale dataset is indeed a key factor to the success of our model.
Concept Mask: Large-Scale Segmentation from Semantic Concepts
Aug 18, 2018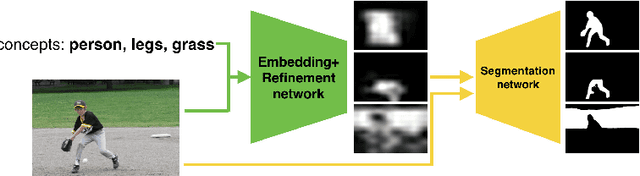


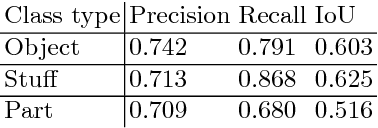
Existing works on semantic segmentation typically consider a small number of labels, ranging from tens to a few hundreds. With a large number of labels, training and evaluation of such task become extremely challenging due to correlation between labels and lack of datasets with complete annotations. We formulate semantic segmentation as a problem of image segmentation given a semantic concept, and propose a novel system which can potentially handle an unlimited number of concepts, including objects, parts, stuff, and attributes. We achieve this using a weakly and semi-supervised framework leveraging multiple datasets with different levels of supervision. We first train a deep neural network on a 6M stock image dataset with only image-level labels to learn visual-semantic embedding on 18K concepts. Then, we refine and extend the embedding network to predict an attention map, using a curated dataset with bounding box annotations on 750 concepts. Finally, we train an attention-driven class agnostic segmentation network using an 80-category fully annotated dataset. We perform extensive experiments to validate that the proposed system performs competitively to the state of the art on fully supervised concepts, and is capable of producing accurate segmentations for weakly learned and unseen concepts.
Progressive Attention Networks for Visual Attribute Prediction
Aug 06, 2018
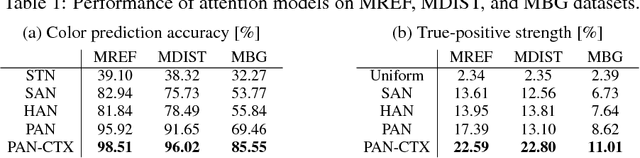
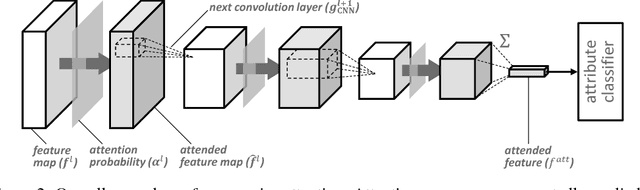

We propose a novel attention model that can accurately attends to target objects of various scales and shapes in images. The model is trained to gradually suppress irrelevant regions in an input image via a progressive attentive process over multiple layers of a convolutional neural network. The attentive process in each layer determines whether to pass or block features at certain spatial locations for use in the subsequent layers. The proposed progressive attention mechanism works well especially when combined with hard attention. We further employ local contexts to incorporate neighborhood features of each location and estimate a better attention probability map. The experiments on synthetic and real datasets show that the proposed attention networks outperform traditional attention methods in visual attribute prediction tasks.
Discriminability objective for training descriptive captions
Jun 08, 2018

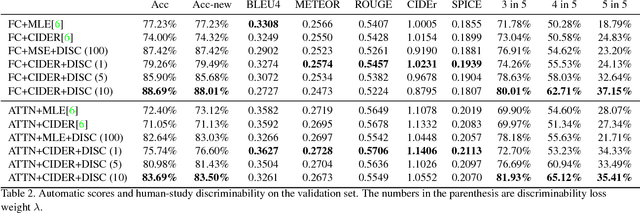

One property that remains lacking in image captions generated by contemporary methods is discriminability: being able to tell two images apart given the caption for one of them. We propose a way to improve this aspect of caption generation. By incorporating into the captioning training objective a loss component directly related to ability (by a machine) to disambiguate image/caption matches, we obtain systems that produce much more discriminative caption, according to human evaluation. Remarkably, our approach leads to improvement in other aspects of generated captions, reflected by a battery of standard scores such as BLEU, SPICE etc. Our approach is modular and can be applied to a variety of model/loss combinations commonly proposed for image captioning.
DVQA: Understanding Data Visualizations via Question Answering
Mar 29, 2018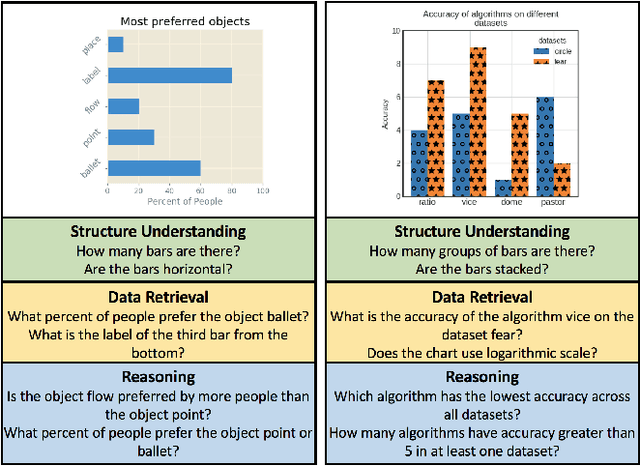
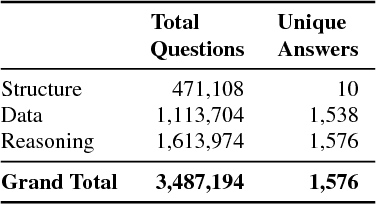
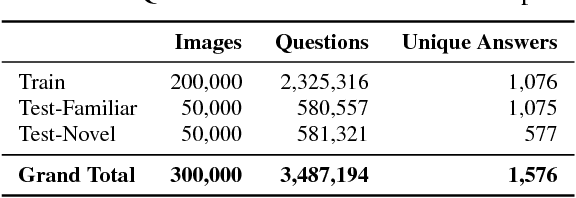
Bar charts are an effective way to convey numeric information, but today's algorithms cannot parse them. Existing methods fail when faced with even minor variations in appearance. Here, we present DVQA, a dataset that tests many aspects of bar chart understanding in a question answering framework. Unlike visual question answering (VQA), DVQA requires processing words and answers that are unique to a particular bar chart. State-of-the-art VQA algorithms perform poorly on DVQA, and we propose two strong baselines that perform considerably better. Our work will enable algorithms to automatically extract numeric and semantic information from vast quantities of bar charts found in scientific publications, Internet articles, business reports, and many other areas.