 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnGoal: Tracking and Visualizing Conversational Goals in Multi-Turn Dialogue with Large Language Models
Aug 28, 2025



As multi-turn dialogues with large language models (LLMs) grow longer and more complex, how can users better evaluate and review progress on their conversational goals? We present OnGoal, an LLM chat interface that helps users better manage goal progress. OnGoal provides real-time feedback on goal alignment through LLM-assisted evaluation, explanations for evaluation results with examples, and overviews of goal progression over time, enabling users to navigate complex dialogues more effectively. Through a study with 20 participants on a writing task, we evaluate OnGoal against a baseline chat interface without goal tracking. Using OnGoal, participants spent less time and effort to achieve their goals while exploring new prompting strategies to overcome miscommunication, suggesting tracking and visualizing goals can enhance engagement and resilience in LLM dialogues. Our findings inspired design implications for future LLM chat interfaces that improve goal communication, reduce cognitive load, enhance interactivity, and enable feedback to improve LLM performance.
Chart-to-Experience: Benchmarking Multimodal LLMs for Predicting Experiential Impact of Charts
May 23, 2025



The field of Multimodal Large Language Models (MLLMs) has made remarkable progress in visual understanding tasks, presenting a vast opportunity to predict the perceptual and emotional impact of charts. However, it also raises concerns, as many applications of LLMs are based on overgeneralized assumptions from a few examples, lacking sufficient validation of their performance and effectiveness. We introduce Chart-to-Experience, a benchmark dataset comprising 36 charts, evaluated by crowdsourced workers for their impact on seven experiential factors. Using the dataset as ground truth, we evaluated capabilities of state-of-the-art MLLMs on two tasks: direct prediction and pairwise comparison of charts. Our findings imply that MLLMs are not as sensitive as human evaluators when assessing individual charts, but are accurate and reliable in pairwise comparisons.
Summaries as Captions: Generating Figure Captions for Scientific Documents with Automated Text Summarization
Feb 23, 2023



Effective figure captions are crucial for clear comprehension of scientific figures, yet poor caption writing remains a common issue in scientific articles. Our study of arXiv cs.CL papers found that 53.88% of captions were rated as unhelpful or worse by domain experts, showing the need for better caption generation. Previous efforts in figure caption generation treated it as a vision task, aimed at creating a model to understand visual content and complex contextual information. Our findings, however, demonstrate that over 75% of figure captions' tokens align with corresponding figure-mentioning paragraphs, indicating great potential for language technology to solve this task. In this paper, we present a novel approach for generating figure captions in scientific documents using text summarization techniques. Our approach extracts sentences referencing the target figure, then summarizes them into a concise caption. In the experiments on real-world arXiv papers (81.2% were published at academic conferences), our method, using only text data, outperformed previous approaches in both automatic and human evaluations. We further conducted data-driven investigations into the two core challenges: (i) low-quality author-written captions and (ii) the absence of a standard for good captions. We found that our models could generate improved captions for figures with original captions rated as unhelpful, and the model trained on captions with more than 30 tokens produced higher-quality captions. We also found that good captions often include the high-level takeaway of the figure. Our work proves the effectiveness of text summarization in generating figure captions for scholarly articles, outperforming prior vision-based approaches. Our findings have practical implications for future figure captioning systems, improving scientific communication clarity.
PersonaSAGE: A Multi-Persona Graph Neural Network
Dec 28, 2022



Graph Neural Networks (GNNs) have become increasingly important in recent years due to their state-of-the-art performance on many important downstream applications. Existing GNNs have mostly focused on learning a single node representation, despite that a node often exhibits polysemous behavior in different contexts. In this work, we develop a persona-based graph neural network framework called PersonaSAGE that learns multiple persona-based embeddings for each node in the graph. Such disentangled representations are more interpretable and useful than a single embedding. Furthermore, PersonaSAGE learns the appropriate set of persona embeddings for each node in the graph, and every node can have a different number of assigned persona embeddings. The framework is flexible enough and the general design helps in the wide applicability of the learned embeddings to suit the domain. We utilize publicly available benchmark datasets to evaluate our approach and against a variety of baselines. The experiments demonstrate the effectiveness of PersonaSAGE for a variety of important tasks including link prediction where we achieve an average gain of 15% while remaining competitive for node classification. Finally, we also demonstrate the utility of PersonaSAGE with a case study for personalized recommendation of different entity types in a data management platform.
A Hypergraph Neural Network Framework for Learning Hyperedge-Dependent Node Embeddings
Dec 28, 2022In this work, we introduce a hypergraph representation learning framework called Hypergraph Neural Networks (HNN) that jointly learns hyperedge embeddings along with a set of hyperedge-dependent embeddings for each node in the hypergraph. HNN derives multiple embeddings per node in the hypergraph where each embedding for a node is dependent on a specific hyperedge of that node. Notably, HNN is accurate, data-efficient, flexible with many interchangeable components, and useful for a wide range of hypergraph learning tasks. We evaluate the effectiveness of the HNN framework for hyperedge prediction and hypergraph node classification. We find that HNN achieves an overall mean gain of 7.72% and 11.37% across all baseline models and graphs for hyperedge prediction and hypergraph node classification, respectively.
Graph Learning with Localized Neighborhood Fairness
Dec 22, 2022Learning fair graph representations for downstream applications is becoming increasingly important, but existing work has mostly focused on improving fairness at the global level by either modifying the graph structure or objective function without taking into account the local neighborhood of a node. In this work, we formally introduce the notion of neighborhood fairness and develop a computational framework for learning such locally fair embeddings. We argue that the notion of neighborhood fairness is more appropriate since GNN-based models operate at the local neighborhood level of a node. Our neighborhood fairness framework has two main components that are flexible for learning fair graph representations from arbitrary data: the first aims to construct fair neighborhoods for any arbitrary node in a graph and the second enables adaption of these fair neighborhoods to better capture certain application or data-dependent constraints, such as allowing neighborhoods to be more biased towards certain attributes or neighbors in the graph.Furthermore, while link prediction has been extensively studied, we are the first to investigate the graph representation learning task of fair link classification. We demonstrate the effectiveness of the proposed neighborhood fairness framework for a variety of graph machine learning tasks including fair link prediction, link classification, and learning fair graph embeddings. Notably, our approach achieves not only better fairness but also increases the accuracy in the majority of cases across a wide variety of graphs, problem settings, and metrics.
CGC: Contrastive Graph Clustering for Community Detection and Tracking
Apr 05, 2022
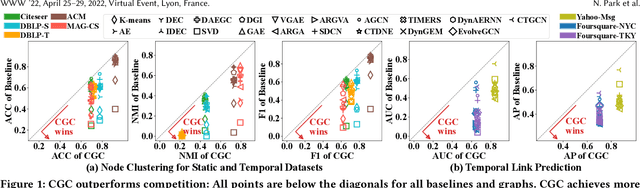
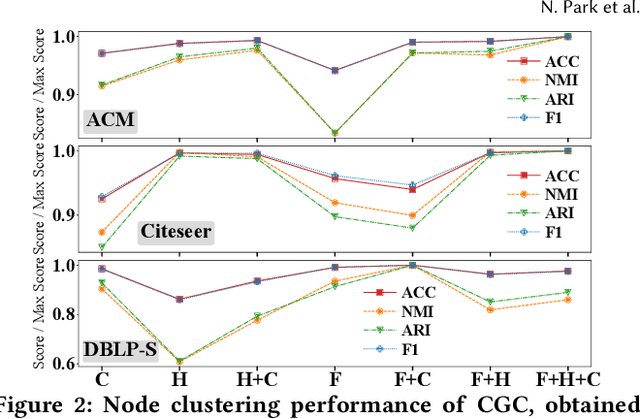
Given entities and their interactions in the web data, which may have occurred at different time, how can we find communities of entities and track their evolution? In this paper, we approach this important task from graph clustering perspective. Recently, state-of-the-art clustering performance in various domains has been achieved by deep clustering methods. Especially, deep graph clustering (DGC) methods have successfully extended deep clustering to graph-structured data by learning node representations and cluster assignments in a joint optimization framework. Despite some differences in modeling choices (e.g., encoder architectures), existing DGC methods are mainly based on autoencoders and use the same clustering objective with relatively minor adaptations. Also, while many real-world graphs are dynamic, previous DGC methods considered only static graphs. In this work, we develop CGC, a novel end-to-end framework for graph clustering, which fundamentally differs from existing methods. CGC learns node embeddings and cluster assignments in a contrastive graph learning framework, where positive and negative samples are carefully selected in a multi-level scheme such that they reflect hierarchical community structures and network homophily. Also, we extend CGC for time-evolving data, where temporal graph clustering is performed in an incremental learning fashion, with the ability to detect change points. Extensive evaluation on real-world graphs demonstrates that the proposed CGC consistently outperforms existing methods.
Online MAP Inference and Learning for Nonsymmetric Determinantal Point Processes
Nov 29, 2021



In this paper, we introduce the online and streaming MAP inference and learning problems for Non-symmetric Determinantal Point Processes (NDPPs) where data points arrive in an arbitrary order and the algorithms are constrained to use a single-pass over the data as well as sub-linear memory. The online setting has an additional requirement of maintaining a valid solution at any point in time. For solving these new problems, we propose algorithms with theoretical guarantees, evaluate them on several real-world datasets, and show that they give comparable performance to state-of-the-art offline algorithms that store the entire data in memory and take multiple passes over it.
"It doesn't look good for a date": Transforming Critiques into Preferences for Conversational Recommendation Systems
Sep 15, 2021
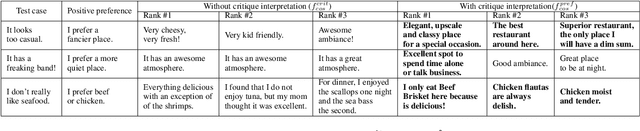
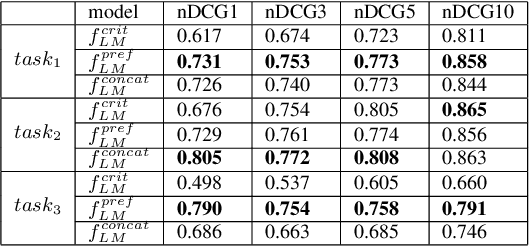
Conversations aimed at determining good recommendations are iterative in nature. People often express their preferences in terms of a critique of the current recommendation (e.g., "It doesn't look good for a date"), requiring some degree of common sense for a preference to be inferred. In this work, we present a method for transforming a user critique into a positive preference (e.g., "I prefer more romantic") in order to retrieve reviews pertaining to potentially better recommendations (e.g., "Perfect for a romantic dinner"). We leverage a large neural language model (LM) in a few-shot setting to perform critique-to-preference transformation, and we test two methods for retrieving recommendations: one that matches embeddings, and another that fine-tunes an LM for the task. We instantiate this approach in the restaurant domain and evaluate it using a new dataset of restaurant critiques. In an ablation study, we show that utilizing critique-to-preference transformation improves recommendations, and that there are at least three general cases that explain this improved performance.
Developing a Conversational Recommendation System for Navigating Limited Options
Apr 13, 2021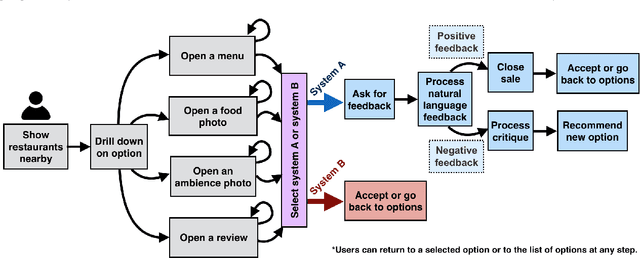
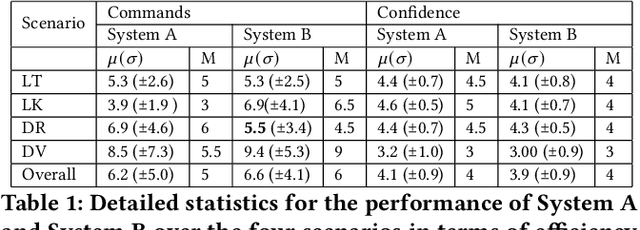
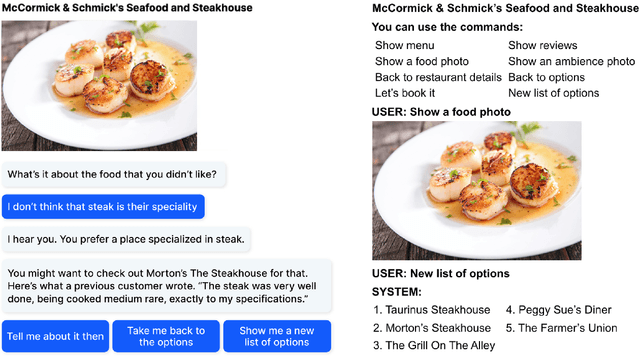
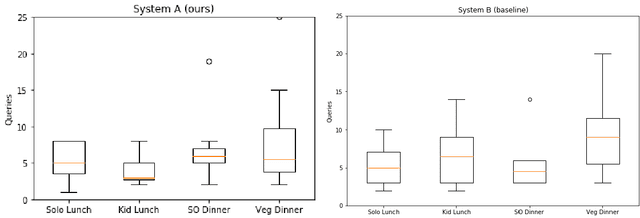
We have developed a conversational recommendation system designed to help users navigate through a set of limited options to find the best choice. Unlike many internet scale systems that use a singular set of search terms and return a ranked list of options from amongst thousands, our system uses multi-turn user dialog to deeply understand the users preferences. The system responds in context to the users specific and immediate feedback to make sequential recommendations. We envision our system would be highly useful in situations with intrinsic constraints, such as finding the right restaurant within walking distance or the right retail item within a limited inventory. Our research prototype instantiates the former use case, leveraging real data from Google Places, Yelp, and Zomato. We evaluated our system against a similar system that did not incorporate user feedback in a 16 person remote study, generating 64 scenario-based search journeys. When our recommendation system was successfully triggered, we saw both an increase in efficiency and a higher confidence rating with respect to final user choice. We also found that users preferred our system (75%) compared with the baseline.