 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovery of Options via Meta-Learned Subgoals
Feb 12, 2021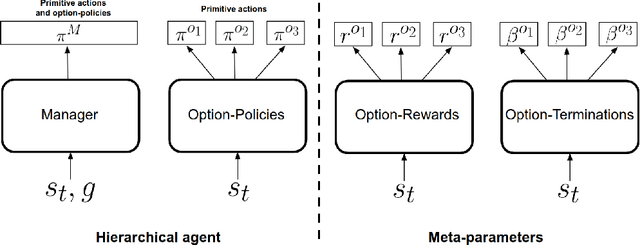
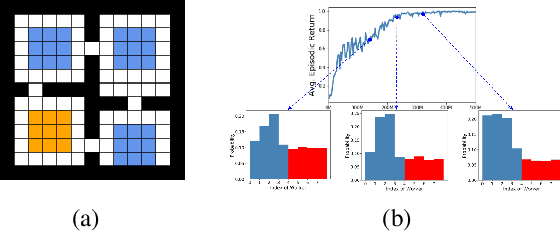
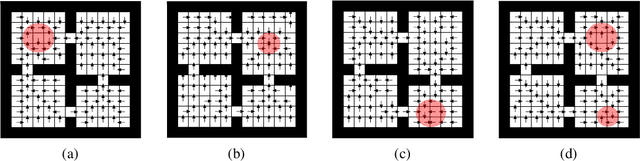
Temporal abstractions in the form of options have been shown to help reinforcement learning (RL) agents learn faster. However, despite prior work on this topic, the problem of discovering options through interaction with an environment remains a challenge. In this paper, we introduce a novel meta-gradient approach for discovering useful options in multi-task RL environments. Our approach is based on a manager-worker decomposition of the RL agent, in which a manager maximises rewards from the environment by learning a task-dependent policy over both a set of task-independent discovered-options and primitive actions. The option-reward and termination functions that define a subgoal for each option are parameterised as neural networks and trained via meta-gradients to maximise their usefulness. Empirical analysis on gridworld and DeepMind Lab tasks show that: (1) our approach can discover meaningful and diverse temporally-extended options in multi-task RL domains, (2) the discovered options are frequently used by the agent while learning to solve the training tasks, and (3) that the discovered options help a randomly initialised manager learn faster in completely new tasks.
Pairwise Weights for Temporal Credit Assignment
Feb 09, 2021
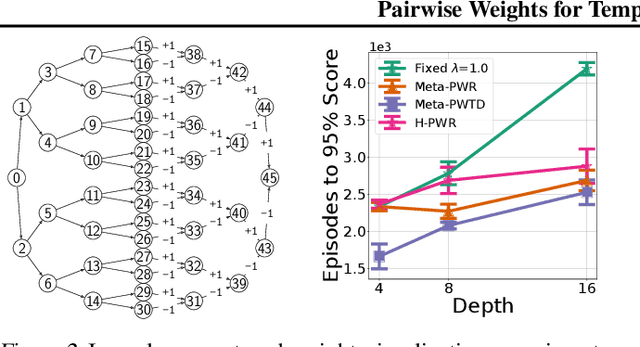
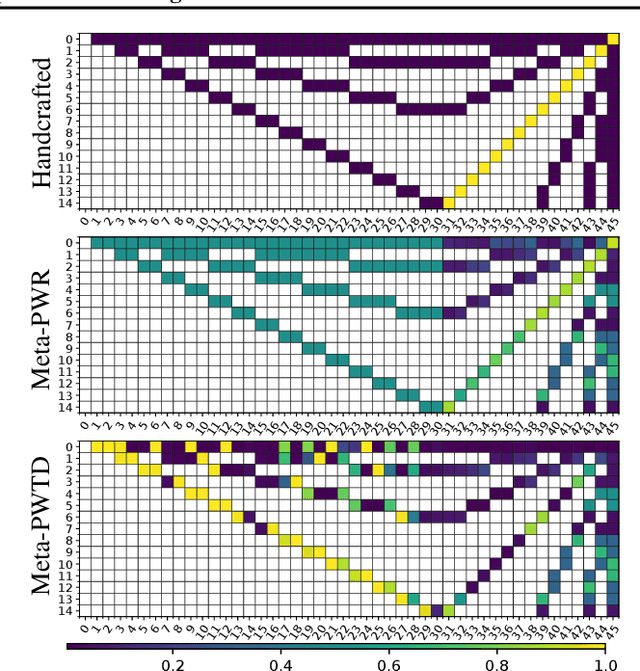

How much credit (or blame) should an action taken in a state get for a future reward? This is the fundamental temporal credit assignment problem in Reinforcement Learning (RL). One of the earliest and still most widely used heuristics is to assign this credit based on a scalar coefficient $\lambda$ (treated as a hyperparameter) raised to the power of the time interval between the state-action and the reward. In this empirical paper, we explore heuristics based on more general pairwise weightings that are functions of the state in which the action was taken, the state at the time of the reward, as well as the time interval between the two. Of course it isn't clear what these pairwise weight functions should be, and because they are too complex to be treated as hyperparameters we develop a metagradient procedure for learning these weight functions during the usual RL training of a policy. Our empirical work shows that it is often possible to learn these pairwise weight functions during learning of the policy to achieve better performance than competing approaches.
Learning State Representations from Random Deep Action-conditional Predictions
Feb 09, 2021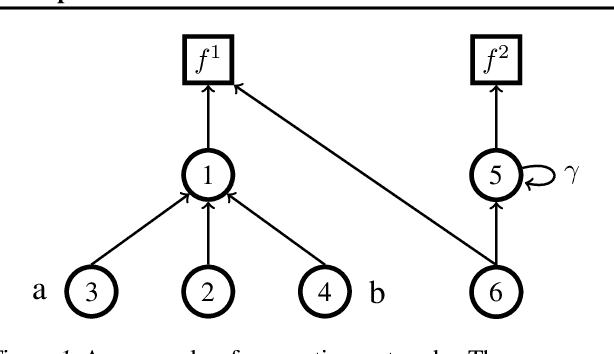
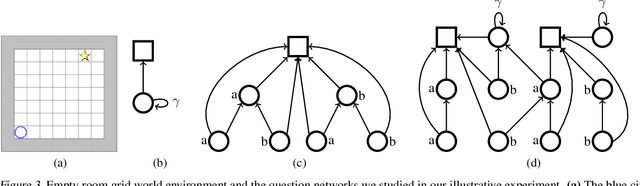
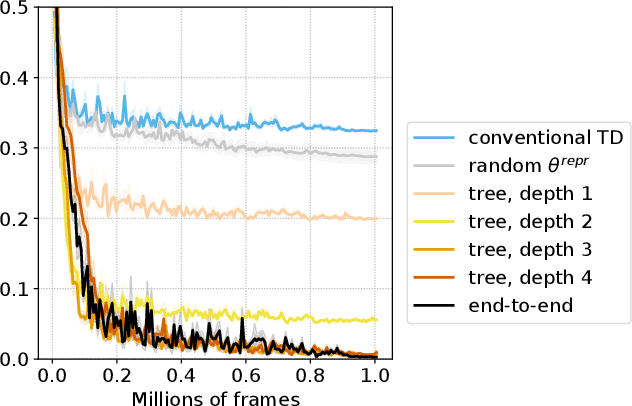
In this work, we study auxiliary prediction tasks defined by temporal-difference networks (TD networks); these networks are a language for expressing a rich space of general value function (GVF) prediction targets that may be learned efficiently with TD. Through analysis in an illustrative domain we show the benefits to learning state representations of exploiting the full richness of TD networks, including both action-conditional predictions and temporally deep predictions. Our main (and perhaps surprising) result is that deep action-conditional TD networks with random structures that create random prediction-questions about random features yield state representations that are competitive with state-of-the-art hand-crafted value prediction and pixel control auxiliary tasks in both Atari games and DeepMind Lab tasks. We also show through stop-gradient experiments that learning the state representations solely via these unsupervised random TD network prediction tasks yield agents that outperform the end-to-end-trained actor-critic baseline.
Efficient Querying for Cooperative Probabilistic Commitments
Dec 14, 2020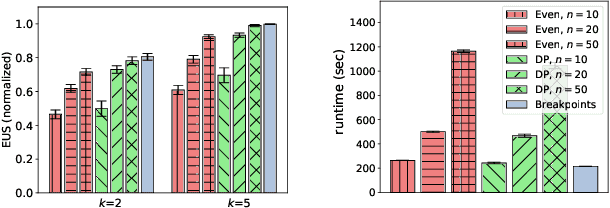
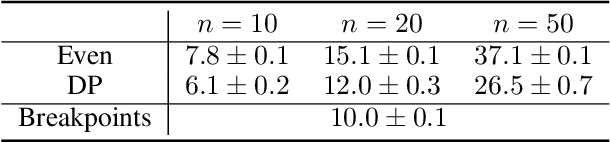
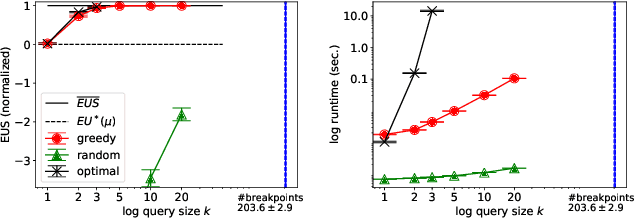
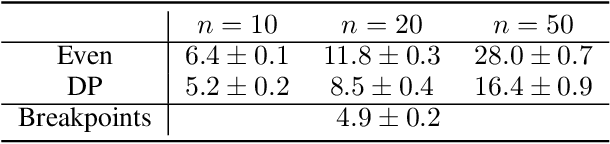
Multiagent systems can use commitments as the core of a general coordination infrastructure, supporting both cooperative and non-cooperative interactions. Agents whose objectives are aligned, and where one agent can help another achieve greater reward by sacrificing some of its own reward, should choose a cooperative commitment to maximize their joint reward. We present a solution to the problem of how cooperative agents can efficiently find an (approximately) optimal commitment by querying about carefully-selected commitment choices. We prove structural properties of the agents' values as functions of the parameters of the commitment specification, and develop a greedy method for composing a query with provable approximation bounds, which we empirically show can find nearly optimal commitments in a fraction of the time methods that lack our insights require.
The Value Equivalence Principle for Model-Based Reinforcement Learning
Nov 06, 2020
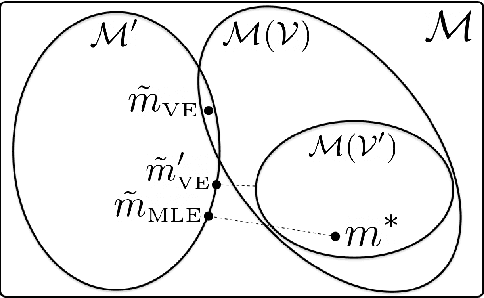
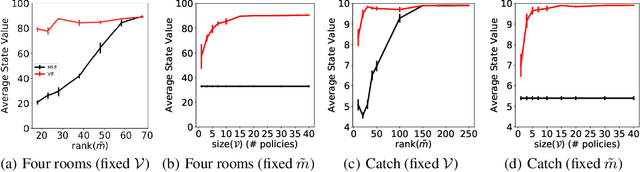
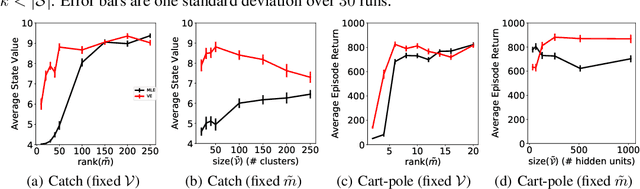
Learning models of the environment from data is often viewed as an essential component to building intelligent reinforcement learning (RL) agents. The common practice is to separate the learning of the model from its use, by constructing a model of the environment's dynamics that correctly predicts the observed state transitions. In this paper we argue that the limited representational resources of model-based RL agents are better used to build models that are directly useful for value-based planning. As our main contribution, we introduce the principle of value equivalence: two models are value equivalent with respect to a set of functions and policies if they yield the same Bellman updates. We propose a formulation of the model learning problem based on the value equivalence principle and analyze how the set of feasible solutions is impacted by the choice of policies and functions. Specifically, we show that, as we augment the set of policies and functions considered, the class of value equivalent models shrinks, until eventually collapsing to a single point corresponding to a model that perfectly describes the environment. In many problems, directly modelling state-to-state transitions may be both difficult and unnecessary. By leveraging the value-equivalence principle one may find simpler models without compromising performance, saving computation and memory. We illustrate the benefits of value-equivalent model learning with experiments comparing it against more traditional counterparts like maximum likelihood estimation. More generally, we argue that the principle of value equivalence underlies a number of recent empirical successes in RL, such as Value Iteration Networks, the Predictron, Value Prediction Networks, TreeQN, and MuZero, and provides a first theoretical underpinning of those results.
Reinforcement Learning for Sparse-Reward Object-Interaction Tasks in First-person Simulated 3D Environments
Oct 28, 2020
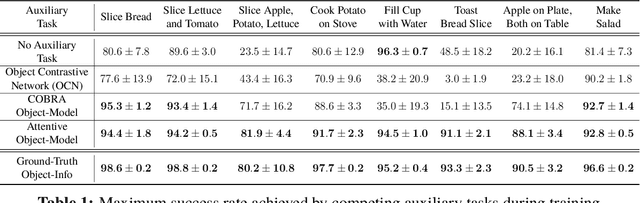
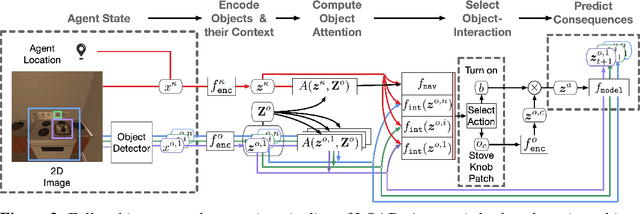
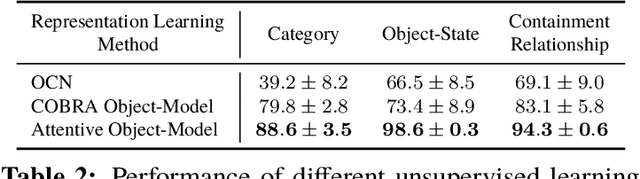
First-person object-interaction tasks in high-fidelity, 3D, simulated environments such as the AI2Thor virtual home-environment pose significant sample-efficiency challenges for reinforcement learning (RL) agents learning from sparse task rewards. To alleviate these challenges, prior work has provided extensive supervision via a combination of reward-shaping, ground-truth object-information, and expert demonstrations. In this work, we show that one can learn object-interaction tasks from scratch without supervision by learning an attentive object-model as an auxiliary task during task learning with an object-centric relational RL agent. Our key insight is that learning an object-model that incorporates object-attention into forward prediction provides a dense learning signal for unsupervised representation learning of both objects and their relationships. This, in turn, enables faster policy learning for an object-centric relational RL agent. We demonstrate our agent by introducing a set of challenging object-interaction tasks in the AI2Thor environment where learning with our attentive object-model is key to strong performance. Specifically, we compare our agent and relational RL agents with alternative auxiliary tasks to a relational RL agent equipped with ground-truth object-information, and show that learning with our object-model best closes the performance gap in terms of both learning speed and maximum success rate. Additionally, we find that incorporating object-attention into an object-model's forward predictions is key to learning representations which capture object-category and object-state.
Discovering Reinforcement Learning Algorithms
Jul 17, 2020
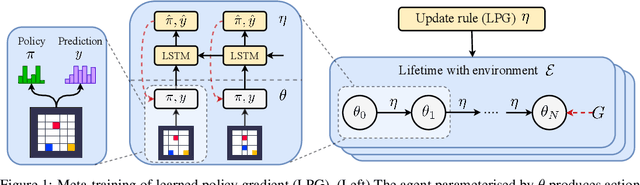
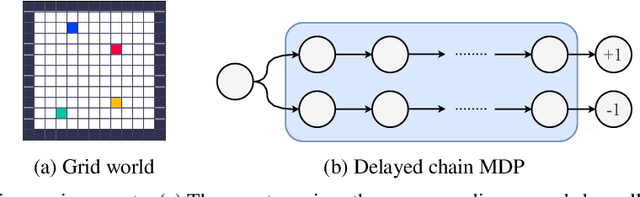
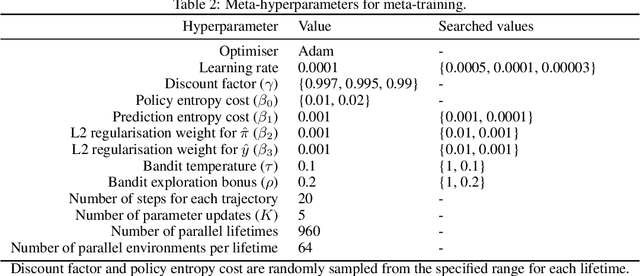
Reinforcement learning (RL) algorithms update an agent's parameters according to one of several possible rules, discovered manually through years of research. Automating the discovery of update rules from data could lead to more efficient algorithms, or algorithms that are better adapted to specific environments. Although there have been prior attempts at addressing this significant scientific challenge, it remains an open question whether it is feasible to discover alternatives to fundamental concepts of RL such as value functions and temporal-difference learning. This paper introduces a new meta-learning approach that discovers an entire update rule which includes both 'what to predict' (e.g. value functions) and 'how to learn from it' (e.g. bootstrapping) by interacting with a set of environments. The output of this method is an RL algorithm that we call Learned Policy Gradient (LPG). Empirical results show that our method discovers its own alternative to the concept of value functions. Furthermore it discovers a bootstrapping mechanism to maintain and use its predictions. Surprisingly, when trained solely on toy environments, LPG generalises effectively to complex Atari games and achieves non-trivial performance. This shows the potential to discover general RL algorithms from data.
Meta-Gradient Reinforcement Learning with an Objective Discovered Online
Jul 16, 2020

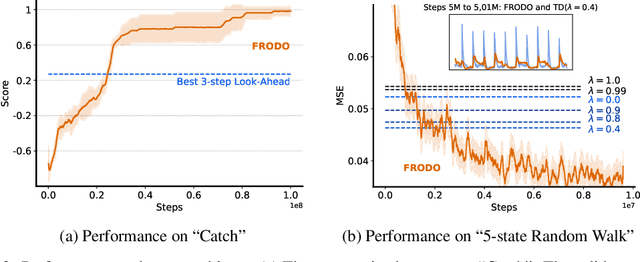
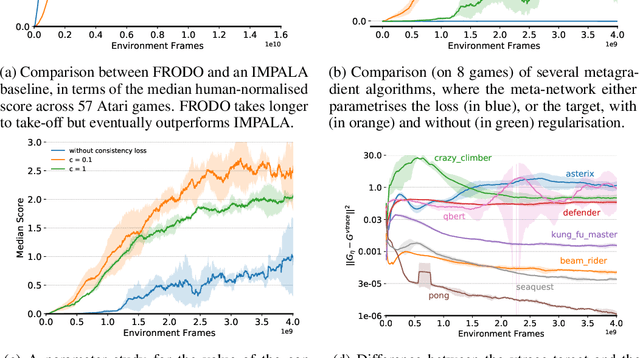
Deep reinforcement learning includes a broad family of algorithms that parameterise an internal representation, such as a value function or policy, by a deep neural network. Each algorithm optimises its parameters with respect to an objective, such as Q-learning or policy gradient, that defines its semantics. In this work, we propose an algorithm based on meta-gradient descent that discovers its own objective, flexibly parameterised by a deep neural network, solely from interactive experience with its environment. Over time, this allows the agent to learn how to learn increasingly effectively. Furthermore, because the objective is discovered online, it can adapt to changes over time. We demonstrate that the algorithm discovers how to address several important issues in RL, such as bootstrapping, non-stationarity, and off-policy learning. On the Atari Learning Environment, the meta-gradient algorithm adapts over time to learn with greater efficiency, eventually outperforming the median score of a strong actor-critic baseline.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020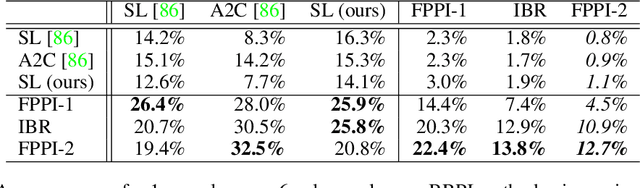
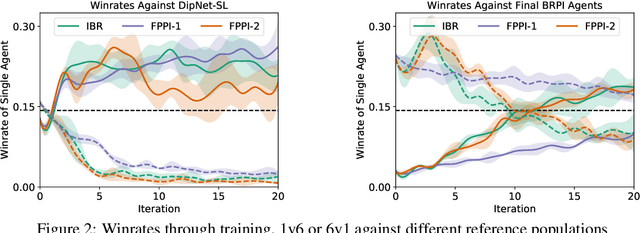
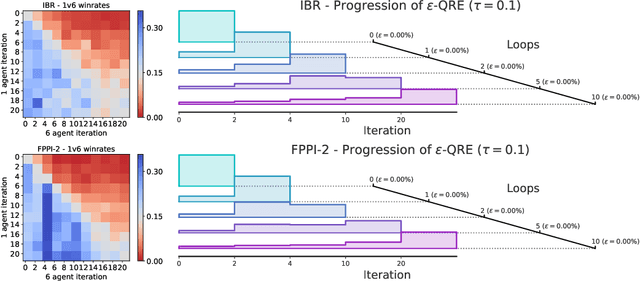
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.
Self-Tuning Deep Reinforcement Learning
Mar 02, 2020
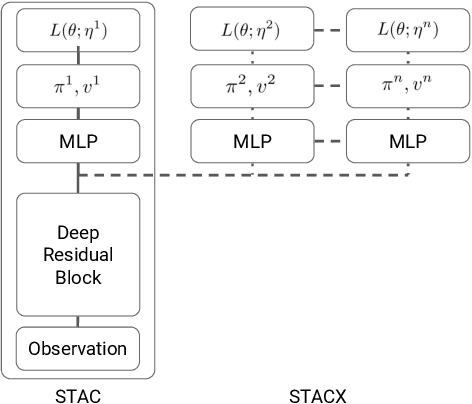
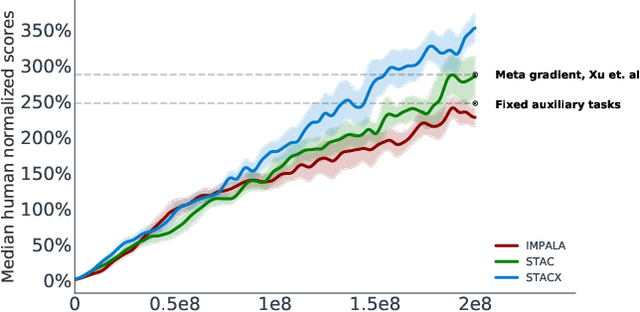
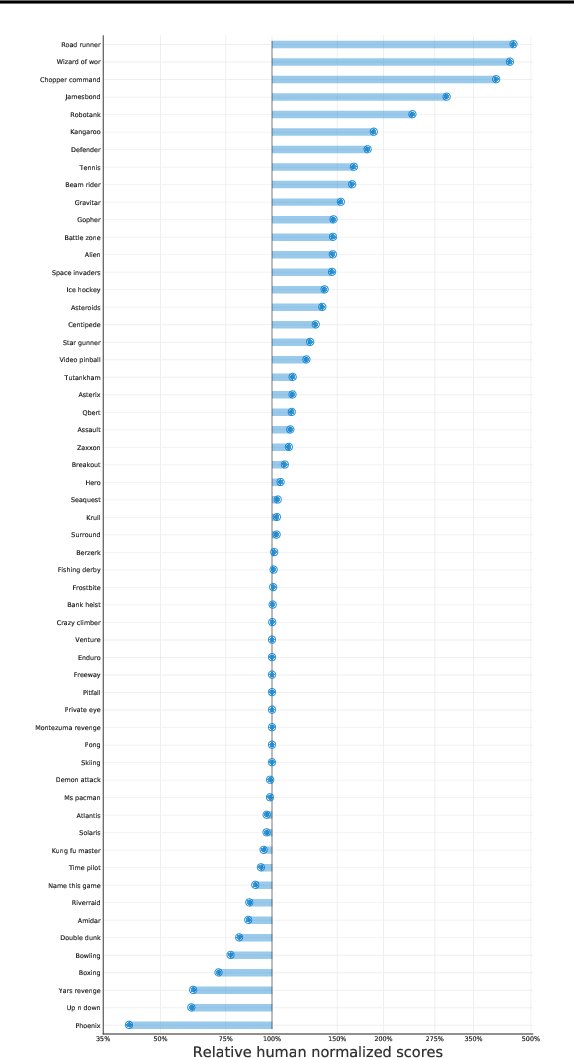
Reinforcement learning (RL) algorithms often require expensive manual or automated hyperparameter searches in order to perform well on a new domain. This need is particularly acute in modern deep RL architectures which often incorporate many modules and multiple loss functions. In this paper, we take a step towards addressing this issue by using metagradients (Xu et al., 2018) to tune these hyperparameters via differentiable cross validation, whilst the agent interacts with and learns from the environment. We present the Self-Tuning Actor Critic (STAC) which uses this process to tune the hyperparameters of the usual loss function of the IMPALA actor critic agent(Espeholt et. al., 2018), to learn the hyperparameters that define auxiliary loss functions, and to balance trade offs in off policy learning by introducing and adapting the hyperparameters of a novel leaky V-trace operator. The method is simple to use, sample efficient and does not require significant increase in compute. Ablative studies show that the overall performance of STAC improves as we adapt more hyperparameters. When applied to 57 games on the Atari 2600 environment over 200 million frames our algorithm improves the median human normalized score of the baseline from 243% to 364%.