 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating self-supervised learning for speech enhancement and separation
Mar 15, 2022
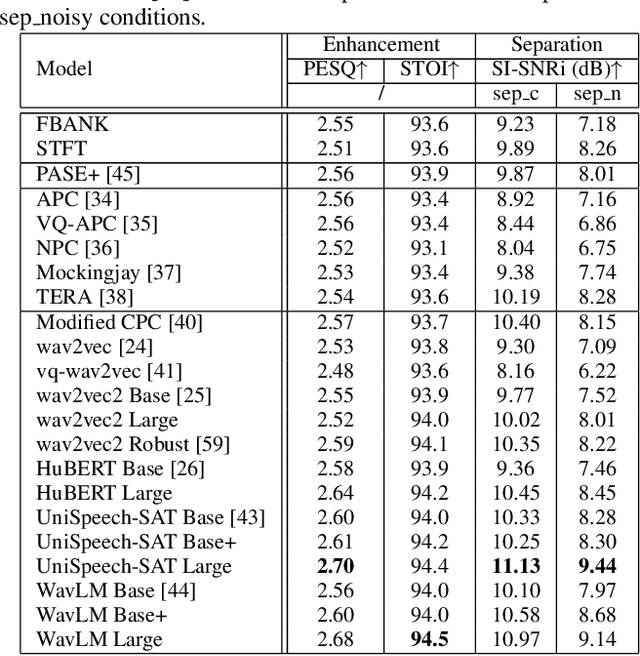
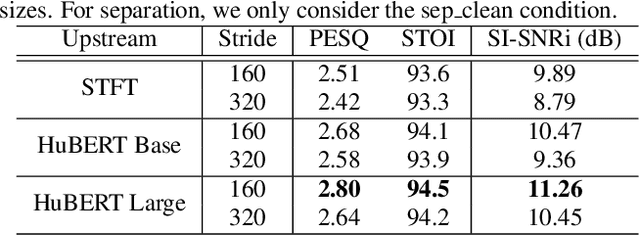
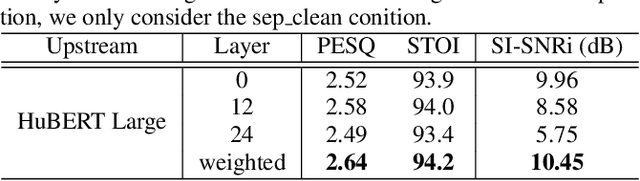
Speech enhancement and separation are two fundamental tasks for robust speech processing. Speech enhancement suppresses background noise while speech separation extracts target speech from interfering speakers. Despite a great number of supervised learning-based enhancement and separation methods having been proposed and achieving good performance, studies on applying self-supervised learning (SSL) to enhancement and separation are limited. In this paper, we evaluate 13 SSL upstream methods on speech enhancement and separation downstream tasks. Our experimental results on Voicebank-DEMAND and Libri2Mix show that some SSL representations consistently outperform baseline features including the short-time Fourier transform (STFT) magnitude and log Mel filterbank (FBANK). Furthermore, we analyze the factors that make existing SSL frameworks difficult to apply to speech enhancement and separation and discuss the representation properties desired for both tasks. Our study is included as the official speech enhancement and separation downstreams for SUPERB.
Enhance Language Identification using Dual-mode Model with Knowledge Distillation
Mar 07, 2022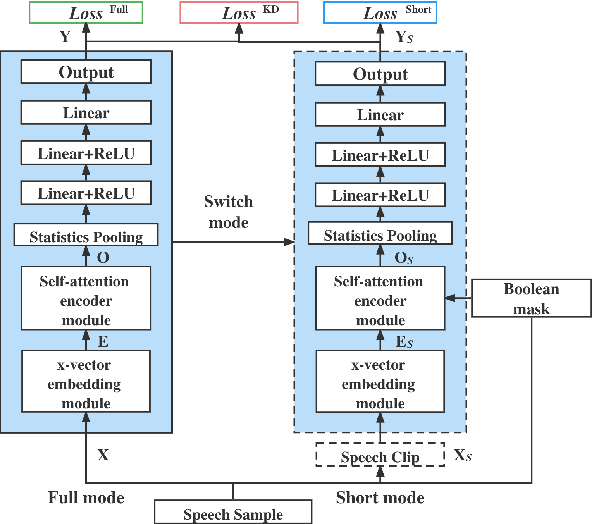
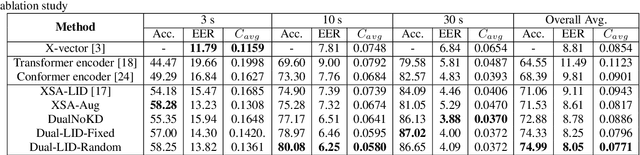

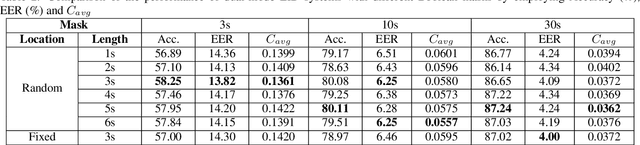
In this paper, we propose to employ a dual-mode framework on the x-vector self-attention (XSA-LID) model with knowledge distillation (KD) to enhance its language identification (LID) performance for both long and short utterances. The dual-mode XSA-LID model is trained by jointly optimizing both the full and short modes with their respective inputs being the full-length speech and its short clip extracted by a specific Boolean mask, and KD is applied to further boost the performance on short utterances. In addition, we investigate the impact of clip-wise linguistic variability and lexical integrity for LID by analyzing the variation of LID performance in terms of the lengths and positions of the mimicked speech clips. We evaluated our approach on the MLS14 data from the NIST 2017 LRE. With the 3~s random-location Boolean mask, our proposed method achieved 19.23%, 21.52% and 8.37% relative improvement in average cost compared with the XSA-LID model on 3s, 10s, and 30s speech, respectively.
Lhotse: a speech data representation library for the modern deep learning ecosystem
Oct 25, 2021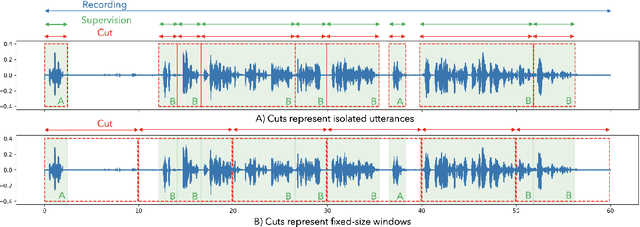
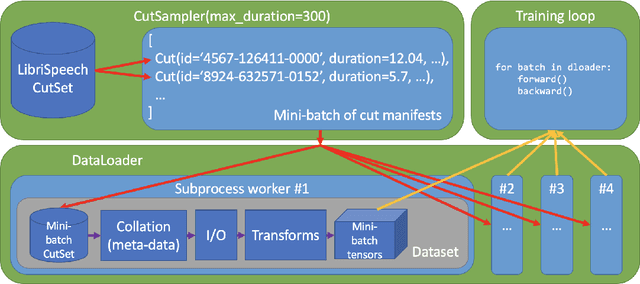
Speech data is notoriously difficult to work with due to a variety of codecs, lengths of recordings, and meta-data formats. We present Lhotse, a speech data representation library that draws upon lessons learned from Kaldi speech recognition toolkit and brings its concepts into the modern deep learning ecosystem. Lhotse provides a common JSON description format with corresponding Python classes and data preparation recipes for over 30 popular speech corpora. Various datasets can be easily combined together and re-purposed for different tasks. The library handles multi-channel recordings, long recordings, local and cloud storage, lazy and on-the-fly operations amongst other features. We introduce Cut and CutSet concepts, which simplify common data wrangling tasks for audio and help incorporate acoustic context of speech utterances. Finally, we show how Lhotse leverages PyTorch data API abstractions and adopts them to handle speech data for deep learning.
Injecting Text and Cross-lingual Supervision in Few-shot Learning from Self-Supervised Models
Oct 10, 2021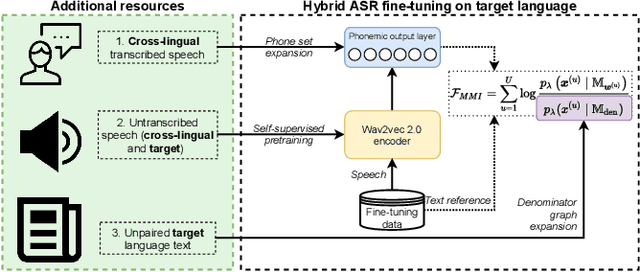

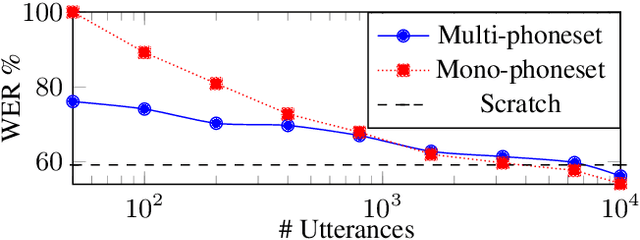
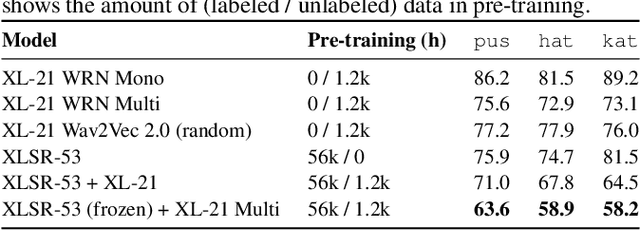
Self-supervised model pre-training has recently garnered significant interest, but relatively few efforts have explored using additional resources in fine-tuning these models. We demonstrate how universal phoneset acoustic models can leverage cross-lingual supervision to improve transfer of pretrained self-supervised representations to new languages. We also show how target-language text can be used to enable and improve fine-tuning with the lattice-free maximum mutual information (LF-MMI) objective. In three low-resource languages these techniques greatly improved few-shot learning performance.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021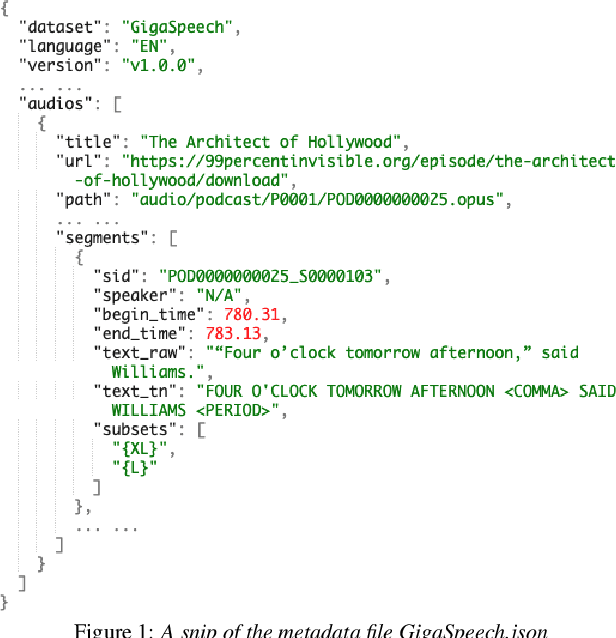
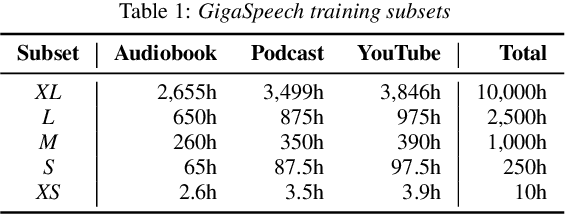
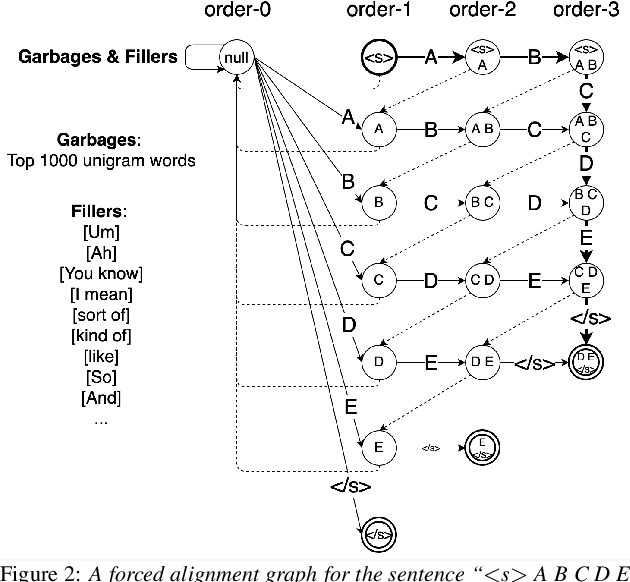
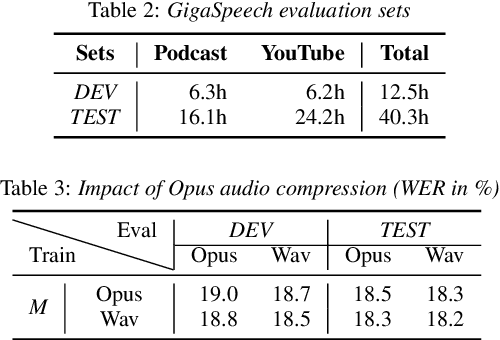
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Reformulating DOVER-Lap Label Mapping as a Graph Partitioning Problem
Apr 05, 2021
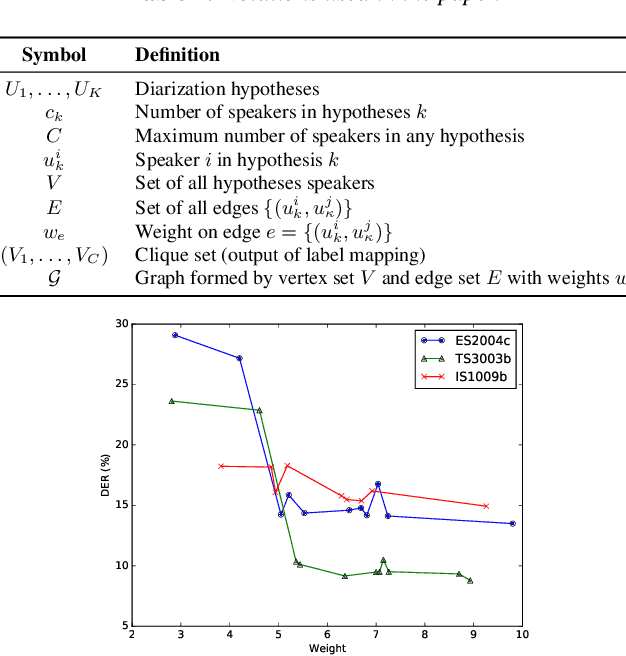
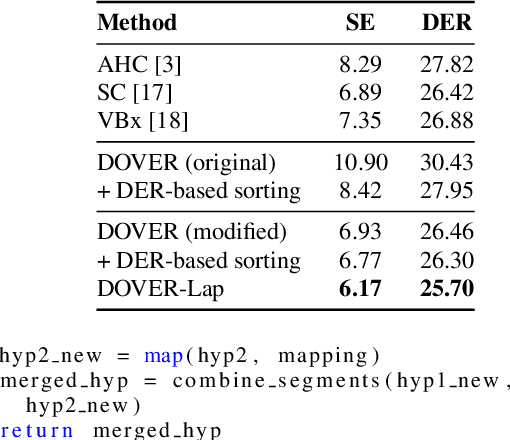
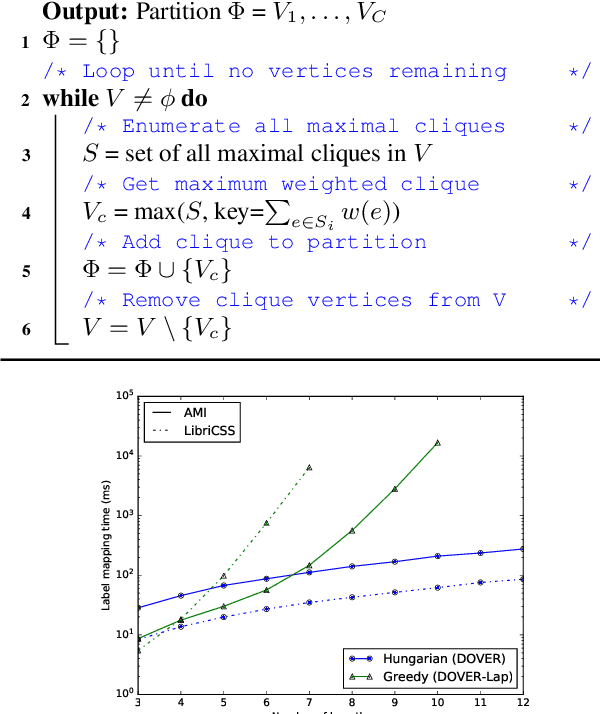
We recently proposed DOVER-Lap, a method for combining overlap-aware speaker diarization system outputs. DOVER-Lap improved upon its predecessor DOVER by using a label mapping method based on globally-informed greedy search. In this paper, we analyze this label mapping in the framework of a maximum orthogonal graph partitioning problem, and present three inferences. First, we show that DOVER-Lap label mapping is exponential in the input size, which poses a challenge when combining a large number of hypotheses. We then revisit the DOVER label mapping algorithm and propose a modification which performs similar to DOVER-Lap while being computationally tractable. We also derive an approximation bound for the algorithm in terms of the maximum number of hypotheses speakers. Finally, we describe a randomized local search algorithm which provides a near-optimal $(1-\epsilon)$-approximate solution to the problem with high probability. We empirically demonstrate the effectiveness of our methods on the AMI meeting corpus. Our code is publicly available: https://github.com/desh2608/dover-lap.
Adversarial Attacks and Defenses for Speech Recognition Systems
Mar 31, 2021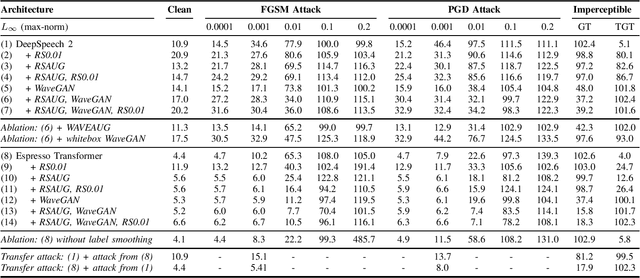
The ubiquitous presence of machine learning systems in our lives necessitates research into their vulnerabilities and appropriate countermeasures. In particular, we investigate the effectiveness of adversarial attacks and defenses against automatic speech recognition (ASR) systems. We select two ASR models - a thoroughly studied DeepSpeech model and a more recent Espresso framework Transformer encoder-decoder model. We investigate two threat models: a denial-of-service scenario where fast gradient-sign method (FGSM) or weak projected gradient descent (PGD) attacks are used to degrade the model's word error rate (WER); and a targeted scenario where a more potent imperceptible attack forces the system to recognize a specific phrase. We find that the attack transferability across the investigated ASR systems is limited. To defend the model, we use two preprocessing defenses: randomized smoothing and WaveGAN-based vocoder, and find that they significantly improve the model's adversarial robustness. We show that a WaveGAN vocoder can be a useful countermeasure to adversarial attacks on ASR systems - even when it is jointly attacked with the ASR, the target phrases' word error rate is high.
An Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Mar 16, 2021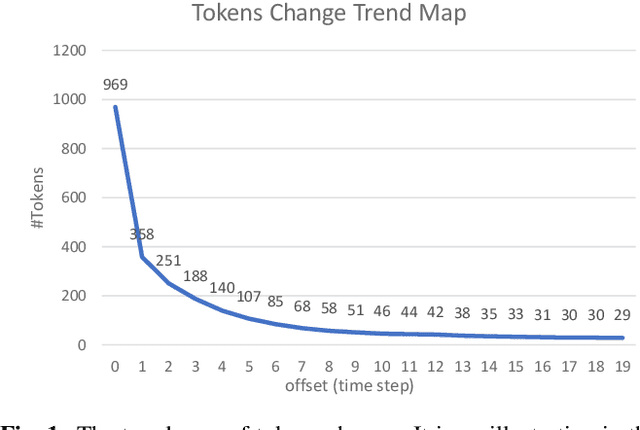
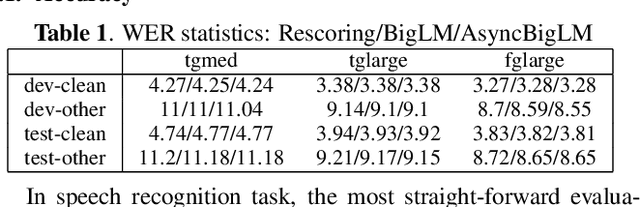
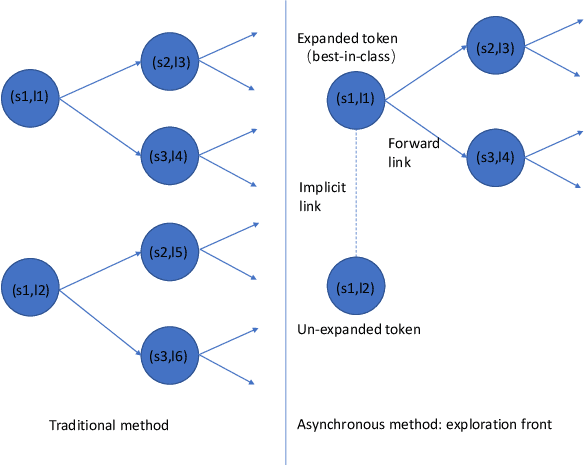
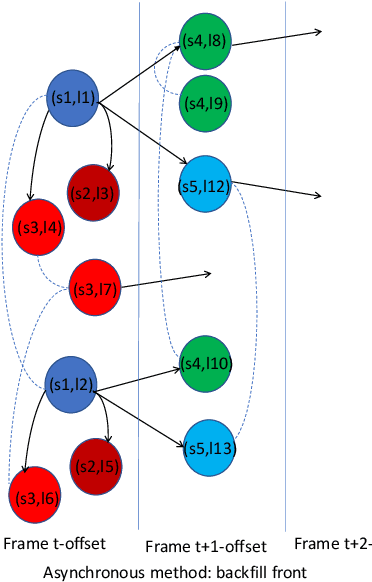
We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.
Learning Feature Weights using Reward Modeling for Denoising Parallel Corpora
Mar 11, 2021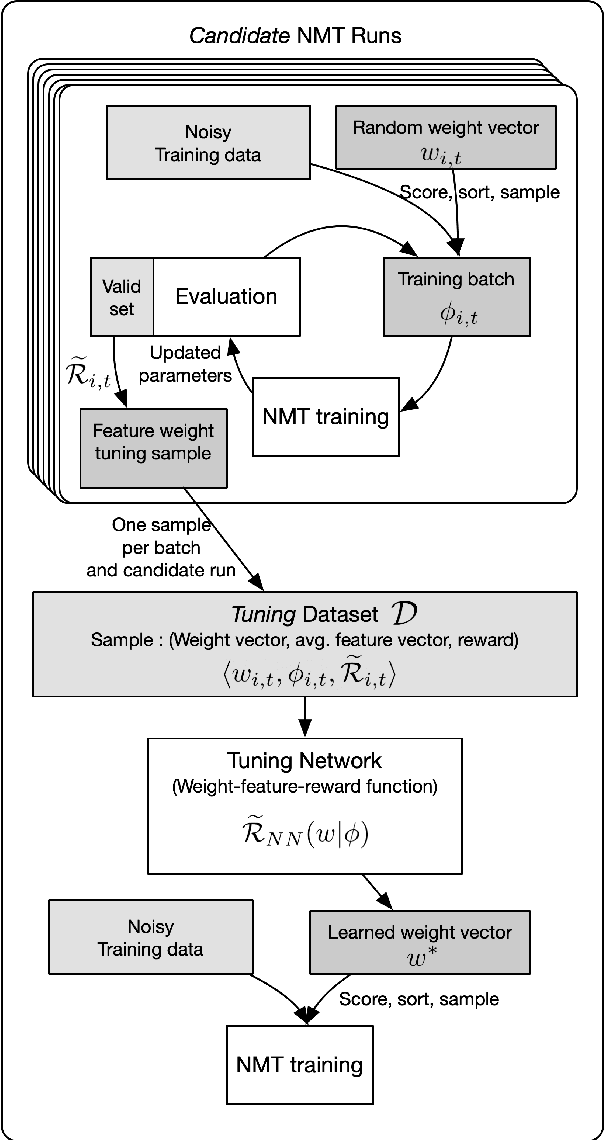
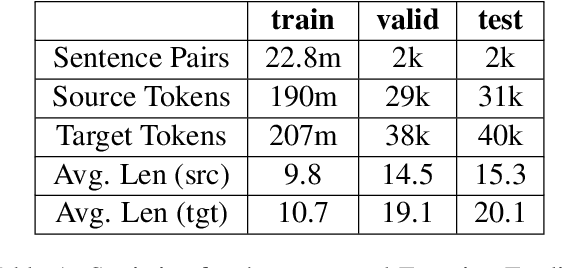
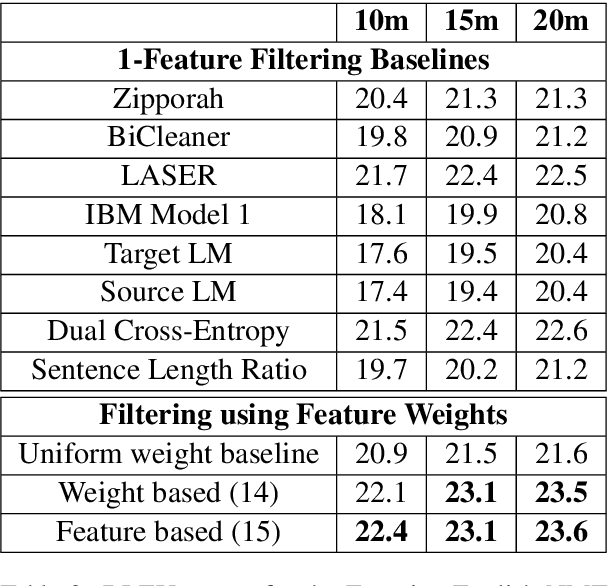
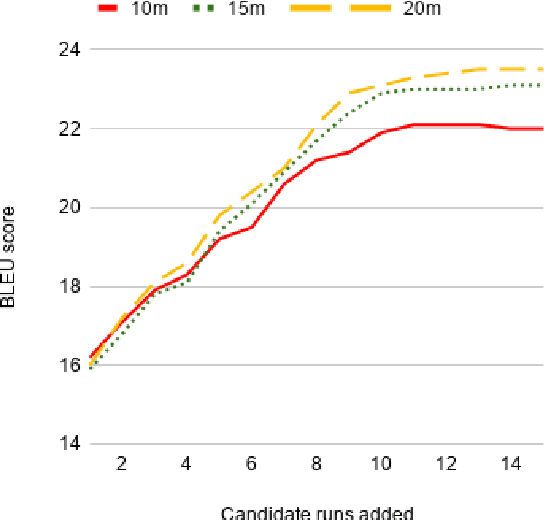
Large web-crawled corpora represent an excellent resource for improving the performance of Neural Machine Translation (NMT) systems across several language pairs. However, since these corpora are typically extremely noisy, their use is fairly limited. Current approaches to dealing with this problem mainly focus on filtering using heuristics or single features such as language model scores or bi-lingual similarity. This work presents an alternative approach which learns weights for multiple sentence-level features. These feature weights which are optimized directly for the task of improving translation performance, are used to score and filter sentences in the noisy corpora more effectively. We provide results of applying this technique to building NMT systems using the Paracrawl corpus for Estonian-English and show that it beats strong single feature baselines and hand designed combinations. Additionally, we analyze the sensitivity of this method to different types of noise and explore if the learned weights generalize to other language pairs using the Maltese-English Paracrawl corpus.
Learning Policies for Multilingual Training of Neural Machine Translation Systems
Mar 11, 2021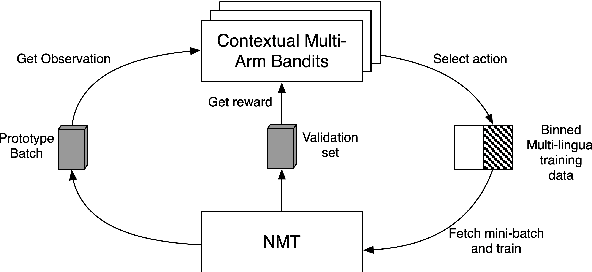
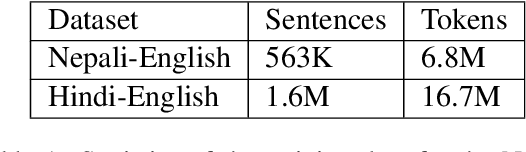
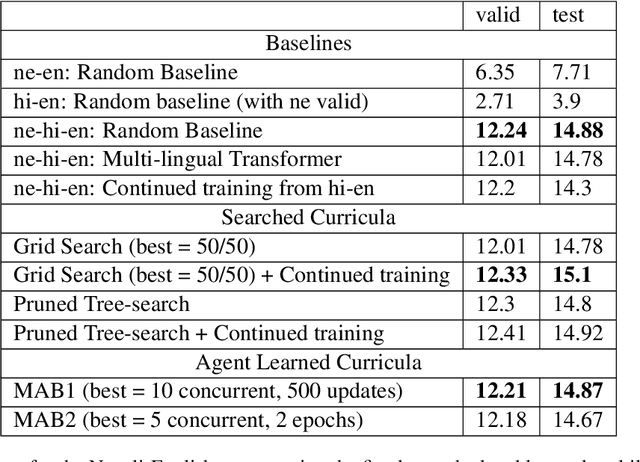
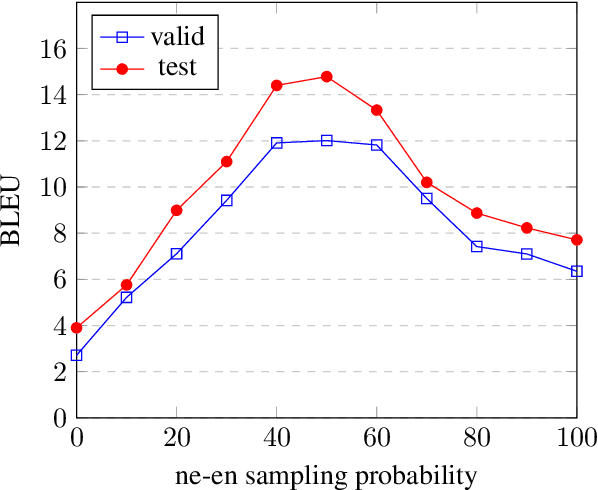
Low-resource Multilingual Neural Machine Translation (MNMT) is typically tasked with improving the translation performance on one or more language pairs with the aid of high-resource language pairs. In this paper, we propose two simple search based curricula -- orderings of the multilingual training data -- which help improve translation performance in conjunction with existing techniques such as fine-tuning. Additionally, we attempt to learn a curriculum for MNMT from scratch jointly with the training of the translation system with the aid of contextual multi-arm bandits. We show on the FLORES low-resource translation dataset that these learned curricula can provide better starting points for fine tuning and improve overall performance of the translation system.