 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Jun 30, 2022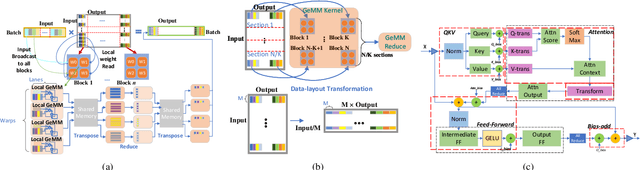
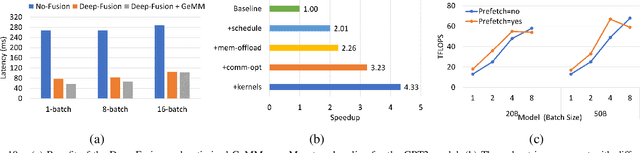
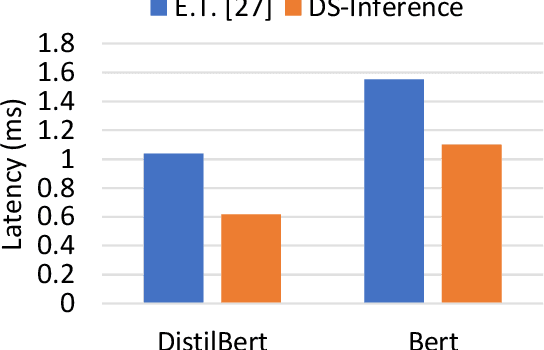
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be single- or multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1.5x for throughput-oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25x larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over $50\%$ of A6000 peak).
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022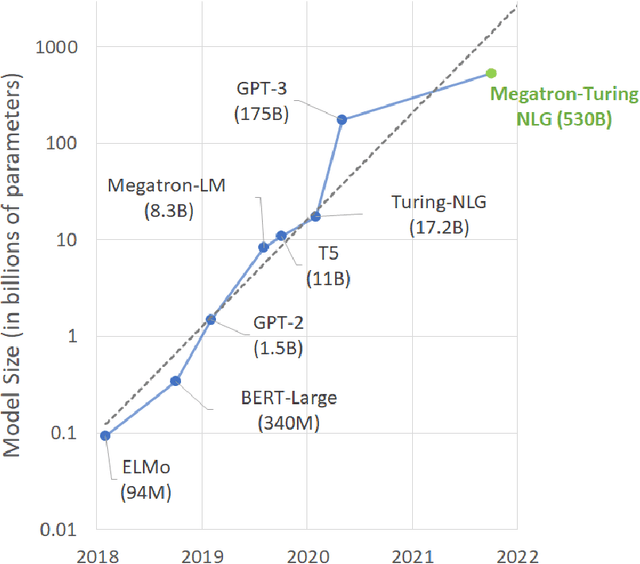
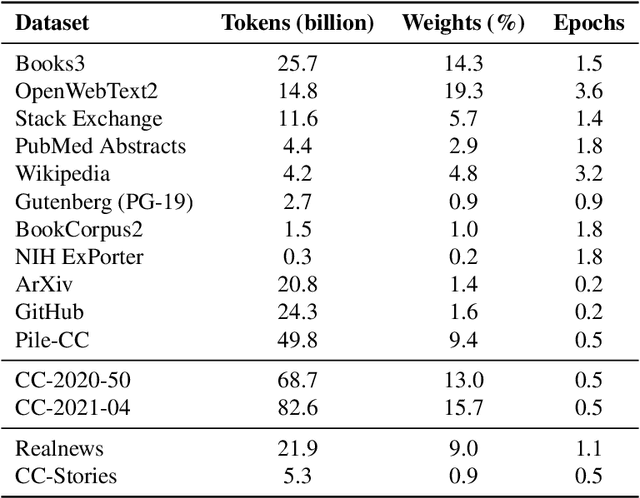
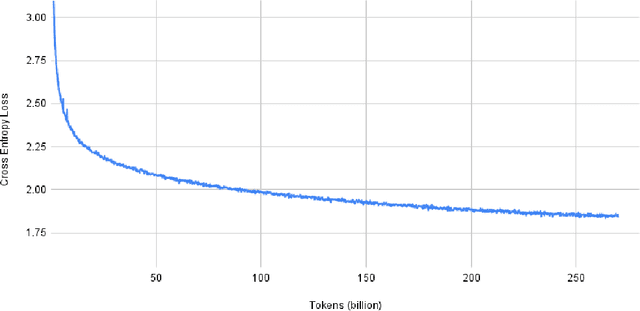
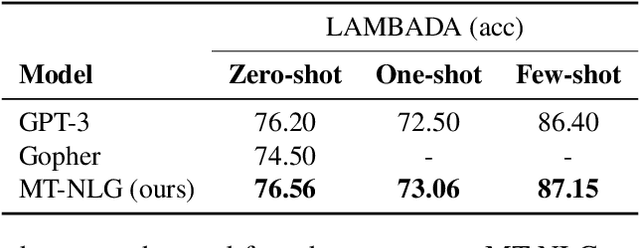
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
Jan 14, 2022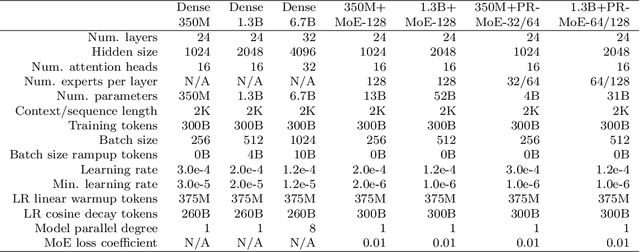
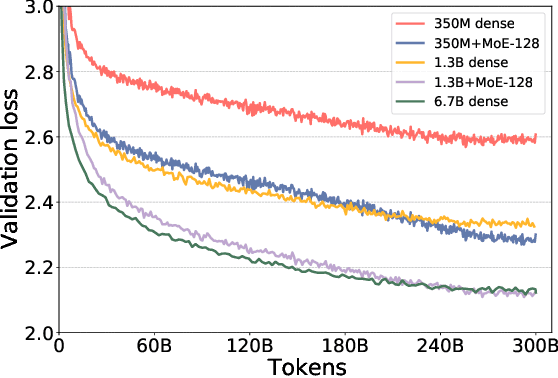
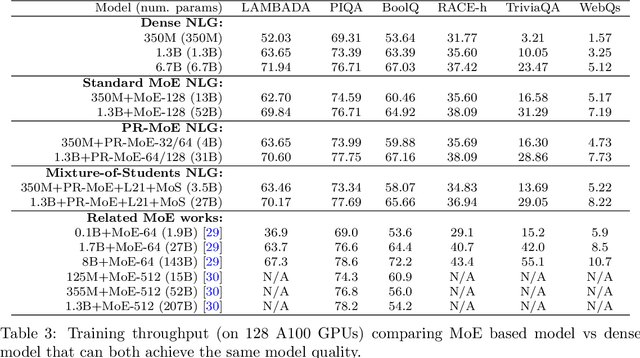
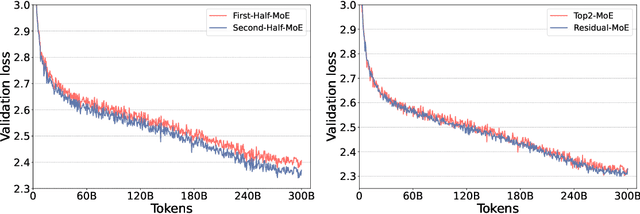
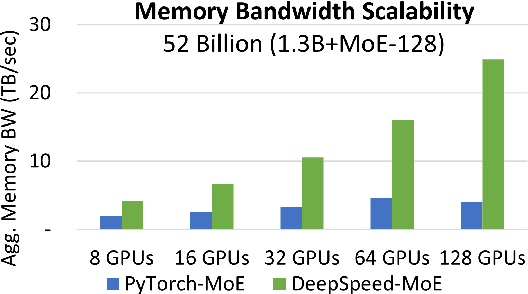
As the training of giant dense models hits the boundary on the availability and capability of the hardware resources today, Mixture-of-Experts (MoE) models become one of the most promising model architectures due to their significant training cost reduction compared to a quality-equivalent dense model. Its training cost saving is demonstrated from encoder-decoder models (prior works) to a 5x saving for auto-aggressive language models (this work along with parallel explorations). However, due to the much larger model size and unique architecture, how to provide fast MoE model inference remains challenging and unsolved, limiting its practical usage. To tackle this, we present DeepSpeed-MoE, an end-to-end MoE training and inference solution as part of the DeepSpeed library, including novel MoE architecture designs and model compression techniques that reduce MoE model size by up to 3.7x, and a highly optimized inference system that provides 7.3x better latency and cost compared to existing MoE inference solutions. DeepSpeed-MoE offers an unprecedented scale and efficiency to serve massive MoE models with up to 4.5x faster and 9x cheaper inference compared to quality-equivalent dense models. We hope our innovations and systems help open a promising path to new directions in the large model landscape, a shift from dense to sparse MoE models, where training and deploying higher-quality models with fewer resources becomes more widely possible.
Scalable and Efficient MoE Training for Multitask Multilingual Models
Sep 22, 2021
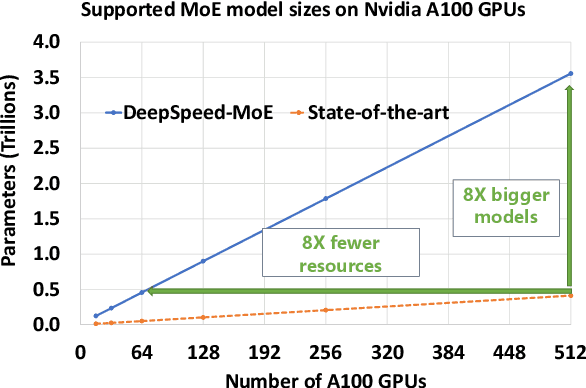

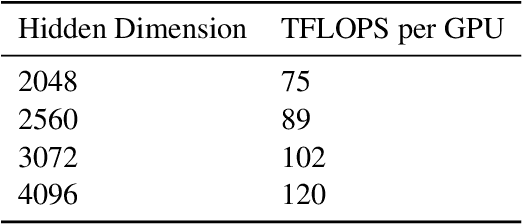
The Mixture of Experts (MoE) models are an emerging class of sparsely activated deep learning models that have sublinear compute costs with respect to their parameters. In contrast with dense models, the sparse architecture of MoE offers opportunities for drastically growing model size with significant accuracy gain while consuming much lower compute budget. However, supporting large scale MoE training also has its own set of system and modeling challenges. To overcome the challenges and embrace the opportunities of MoE, we first develop a system capable of scaling MoE models efficiently to trillions of parameters. It combines multi-dimensional parallelism and heterogeneous memory technologies harmoniously with MoE to empower 8x larger models on the same hardware compared with existing work. Besides boosting system efficiency, we also present new training methods to improve MoE sample efficiency and leverage expert pruning strategy to improve inference time efficiency. By combining the efficient system and training methods, we are able to significantly scale up large multitask multilingual models for language generation which results in a great improvement in model accuracy. A model trained with 10 billion parameters on 50 languages can achieve state-of-the-art performance in Machine Translation (MT) and multilingual natural language generation tasks. The system support of efficient MoE training has been implemented and open-sourced with the DeepSpeed library.
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
Apr 16, 2021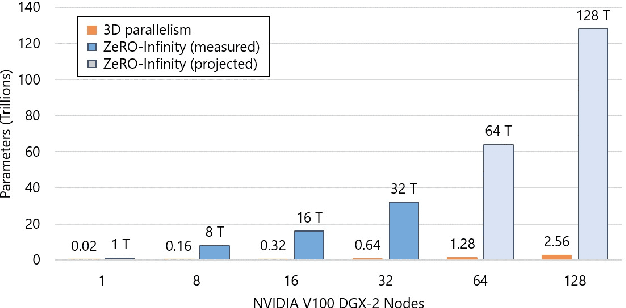


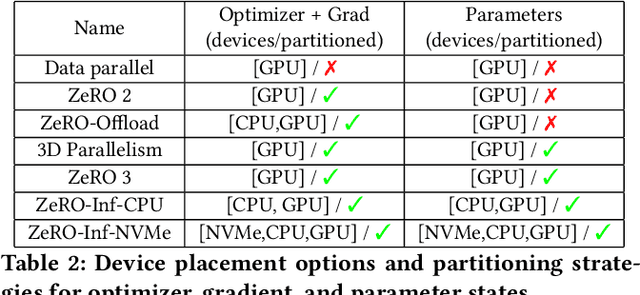
In the last three years, the largest dense deep learning models have grown over 1000x to reach hundreds of billions of parameters, while the GPU memory has only grown by 5x (16 GB to 80 GB). Therefore, the growth in model scale has been supported primarily though system innovations that allow large models to fit in the aggregate GPU memory of multiple GPUs. However, we are getting close to the GPU memory wall. It requires 800 NVIDIA V100 GPUs just to fit a trillion parameter model for training, and such clusters are simply out of reach for most data scientists. In addition, training models at that scale requires complex combinations of parallelism techniques that puts a big burden on the data scientists to refactor their model. In this paper we present ZeRO-Infinity, a novel heterogeneous system technology that leverages GPU, CPU, and NVMe memory to allow for unprecedented model scale on limited resources without requiring model code refactoring. At the same time it achieves excellent training throughput and scalability, unencumbered by the limited CPU or NVMe bandwidth. ZeRO-Infinity can fit models with tens and even hundreds of trillions of parameters for training on current generation GPU clusters. It can be used to fine-tune trillion parameter models on a single NVIDIA DGX-2 node, making large models more accessible. In terms of training throughput and scalability, it sustains over 25 petaflops on 512 NVIDIA V100 GPUs(40% of peak), while also demonstrating super linear scalability. An open source implementation of ZeRO-Infinity is available through DeepSpeed, a deep learning optimization library that makes distributed training easy, efficient, and effective.
1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB's Convergence Speed
Apr 13, 2021
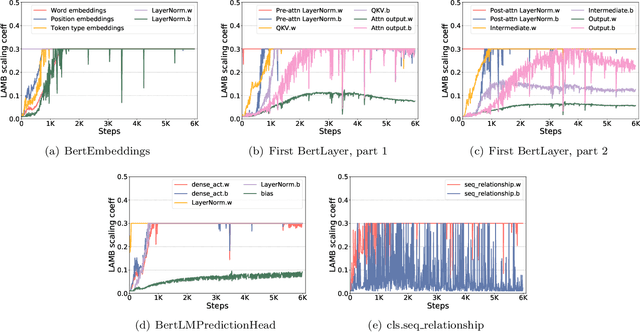
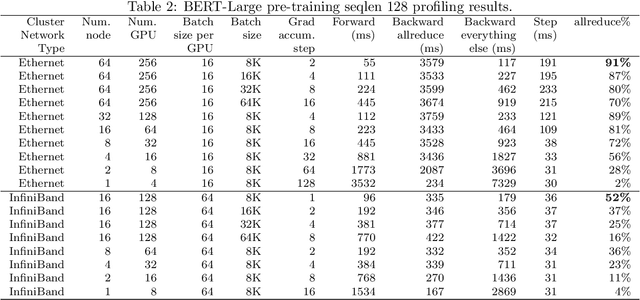
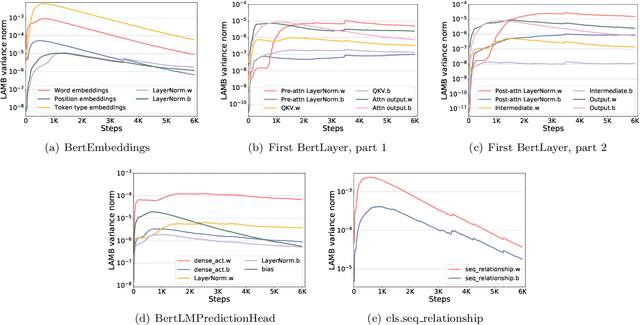
To train large models (like BERT and GPT-3) with hundreds or even thousands of GPUs, the communication has become a major bottleneck, especially on commodity systems with limited-bandwidth TCP interconnects network. On one side large-batch optimization such as LAMB algorithm was proposed to reduce the number of communications. On the other side, communication compression algorithms such as 1-bit SGD and 1-bit Adam help to reduce the volume of each communication. However, we find that simply using one of the techniques is not sufficient to solve the communication challenge, especially on low-bandwidth Ethernet networks. Motivated by this we aim to combine the power of large-batch optimization and communication compression, but we find that existing compression strategies cannot be directly applied to LAMB due to its unique adaptive layerwise learning rates. To this end, we design a new communication-efficient algorithm, 1-bit LAMB, which introduces a novel way to support adaptive layerwise learning rates even when communication is compressed. In addition, we introduce a new system implementation for compressed communication using the NCCL backend of PyTorch distributed, which improves both usability and performance compared to existing MPI-based implementation. For BERT-Large pre-training task with batch sizes from 8K to 64K, our evaluations on up to 256 GPUs demonstrate that 1-bit LAMB with NCCL-based backend is able to achieve up to 4.6x communication volume reduction, up to 2.8x end-to-end speedup (in terms of number of training samples per second), and the same convergence speed (in terms of number of pre-training samples to reach the same accuracy on fine-tuning tasks) compared to uncompressed LAMB.
1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
Feb 04, 2021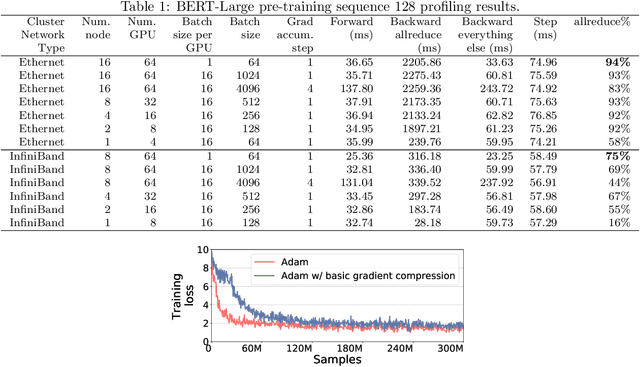
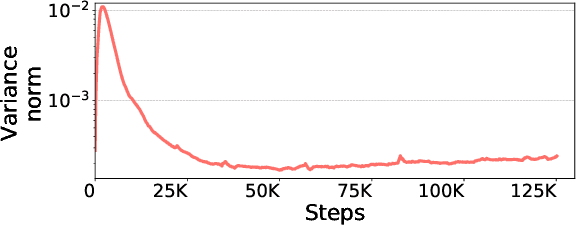
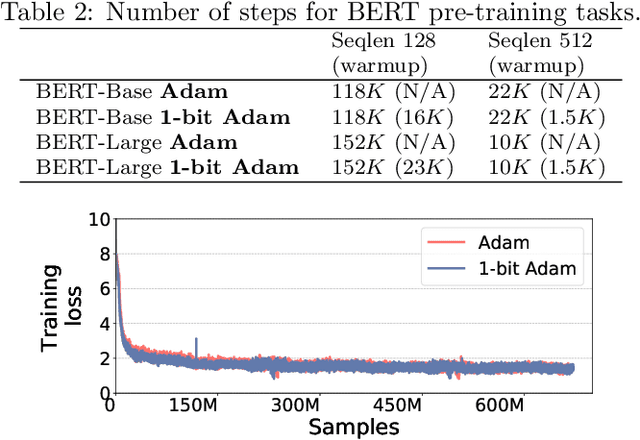

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to $5\times$, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to $3.3\times$ higher throughput for BERT-Large pre-training and up to $2.9\times$ higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.
ZeRO-Offload: Democratizing Billion-Scale Model Training
Jan 18, 2021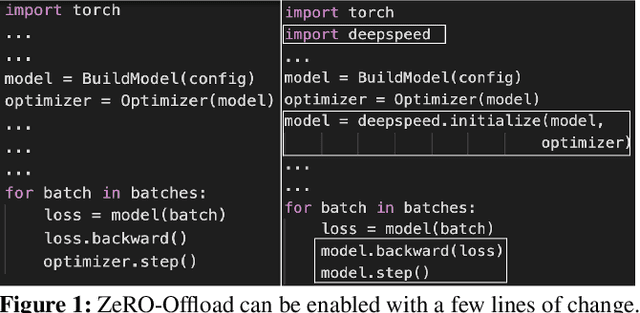
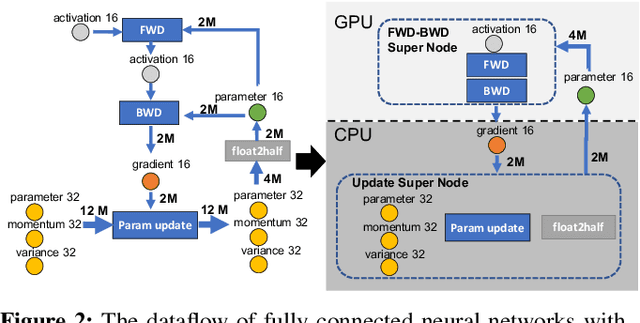
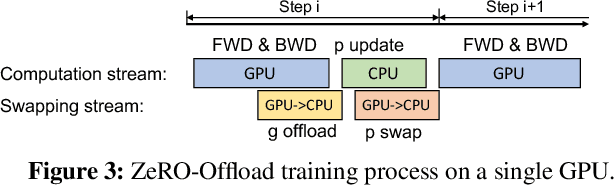
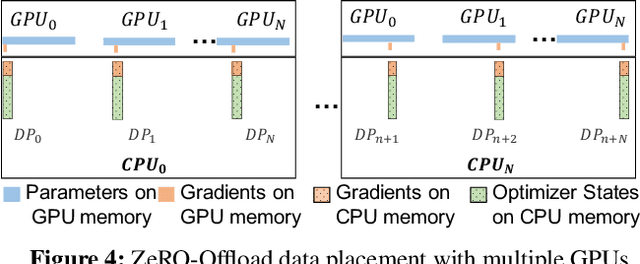
Large-scale model training has been a playing ground for a limited few requiring complex model refactoring and access to prohibitively expensive GPU clusters. ZeRO-Offload changes the large model training landscape by making large model training accessible to nearly everyone. It can train models with over 13 billion parameters on a single GPU, a 10x increase in size compared to popular framework such as PyTorch, and it does so without requiring any model change from the data scientists or sacrificing computational efficiency. ZeRO-Offload enables large model training by offloading data and compute to CPU. To preserve compute efficiency, it is designed to minimize the data movement to/from GPU, and reduce CPU compute time while maximizing memory savings on GPU. As a result, ZeRO-Offload can achieve 40 TFlops/GPU on a single NVIDIA V100 GPU for 10B parameter model compared to 30TF using PyTorch alone for a 1.4B parameter model, the largest that can be trained without running out of memory. ZeRO-Offload is also designed to scale on multiple-GPUs when available, offering near linear speedup on up to 128 GPUs. Additionally, it can work together with model parallelism to train models with over 70 billion parameters on a single DGX-2 box, a 4.5x increase in model size compared to using model parallelism alone. By combining compute and memory efficiency with ease-of-use, ZeRO-Offload democratizes large-scale model training making it accessible to even data scientists with access to just a single GPU.
APMSqueeze: A Communication Efficient Adam-Preconditioned Momentum SGD Algorithm
Aug 28, 2020
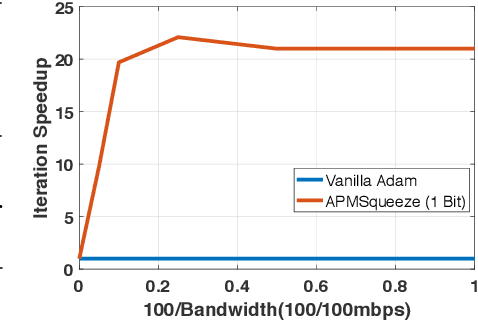
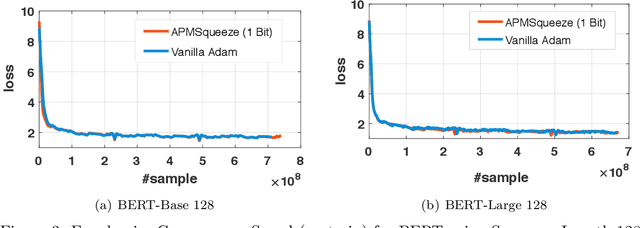
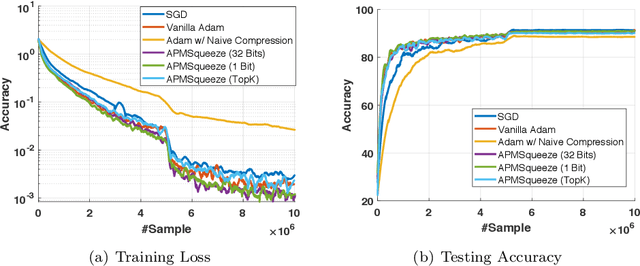
Adam is the important optimization algorithm to guarantee efficiency and accuracy for training many important tasks such as BERT and ImageNet. However, Adam is generally not compatible with information (gradient) compression technology. Therefore, the communication usually becomes the bottleneck for parallelizing Adam. In this paper, we propose a communication efficient {\bf A}DAM {\bf p}reconditioned {\bf M}omentum SGD algorithm-- named APMSqueeze-- through an error compensated method compressing gradients. The proposed algorithm achieves a similar convergence efficiency to Adam in term of epochs, but significantly reduces the running time per epoch. In terms of end-to-end performance (including the full-precision pre-condition step), APMSqueeze is able to provide {sometimes by up to $2-10\times$ speed-up depending on network bandwidth.} We also conduct theoretical analysis on the convergence and efficiency.
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Oct 07, 2019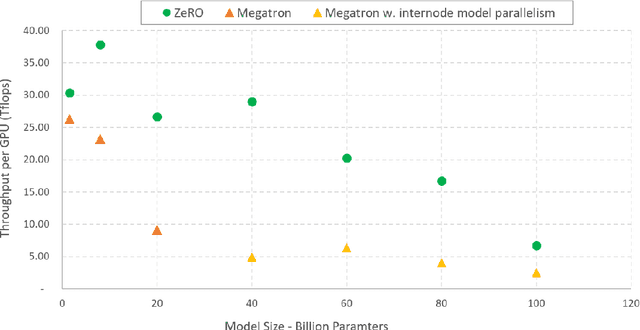
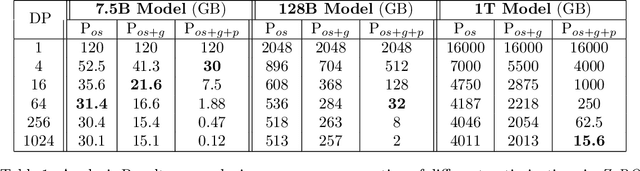
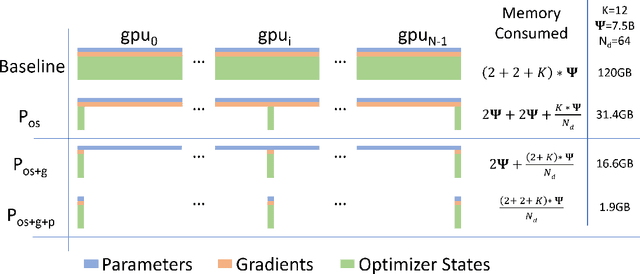
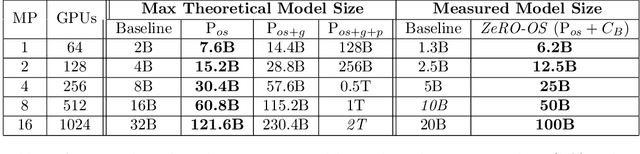
Training large DL models with billions and potentially trillions of parameters is challenging. Existing solutions exhibit fundamental limitations to obtain both memory and scaling (computation/communication) efficiency together. Data parallelism does not help reduce memory footprint per device: a model with 1.5 billion parameters or more runs out of memory. Model parallelism hardly scales efficiently beyond multiple devices of a single node due to fine-grained computation and expensive communication. We develop a novel solution, Zero Redundancy Optimizer (ZeRO), to optimize memory, achieving both memory efficiency and scaling efficiency. Unlike basic data parallelism where memory states are replicated across data-parallel processes, ZeRO partitions model states instead, to scale the model size linearly with the number of devices. Furthermore, it retains scaling efficiency via computation and communication rescheduling and by reducing the model parallelism degree required to run large models. Our analysis on memory requirements and communication volume demonstrates: ZeRO has the potential to scale beyond 1 Trillion parameters using today's hardware (e.g., 1024 GPUs, 64 DGX-2 nodes). To meet near-term scaling goals and serve as a demonstration of ZeRO's capability, we implemented stage-1 optimizations of ZeRO (out of 3 stages in total described in the paper) and tested this ZeRO-OS version. ZeRO-OS reduces memory and boosts model size by 4x compared with the state-of-art, scaling up to 100B parameters. Moving forward, we will work on unlocking stage-2 optimizations, with up to 8x memory savings per device, and ultimately stage-3 optimizations, reducing memory linearly with respect to the number of devices and potentially scaling to models of arbitrary size. We are excited to transform very large models from impossible to train to feasible and efficient to train!