 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaLM: Encoder-Decoder Pre-training for Language Generation and Translation by Augmenting Pretrained Multilingual Encoders
Jun 25, 2021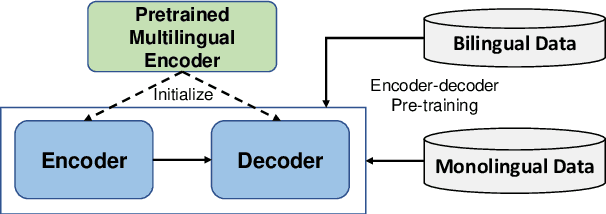

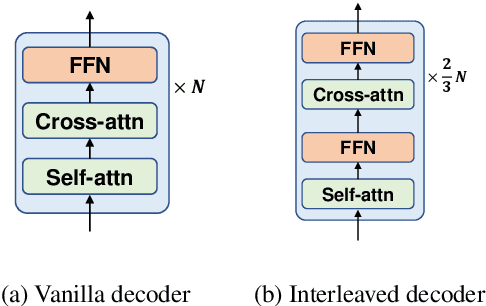
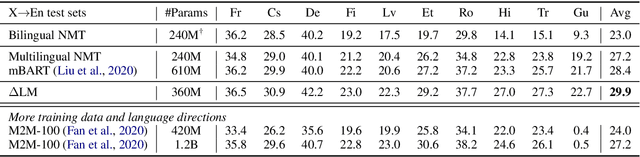
While pretrained encoders have achieved success in various natural language understanding (NLU) tasks, there is a gap between these pretrained encoders and natural language generation (NLG). NLG tasks are often based on the encoder-decoder framework, where the pretrained encoders can only benefit part of it. To reduce this gap, we introduce DeltaLM, a pretrained multilingual encoder-decoder model that regards the decoder as the task layer of off-the-shelf pretrained encoders. Specifically, we augment the pretrained multilingual encoder with a decoder and pre-train it in a self-supervised way. To take advantage of both the large-scale monolingual data and bilingual data, we adopt the span corruption and translation span corruption as the pre-training tasks. Experiments show that DeltaLM outperforms various strong baselines on both natural language generation and translation tasks, including machine translation, abstractive text summarization, data-to-text, and question generation.
Consistency Regularization for Cross-Lingual Fine-Tuning
Jun 15, 2021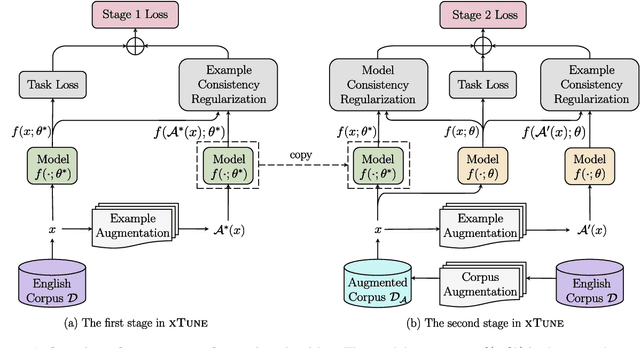
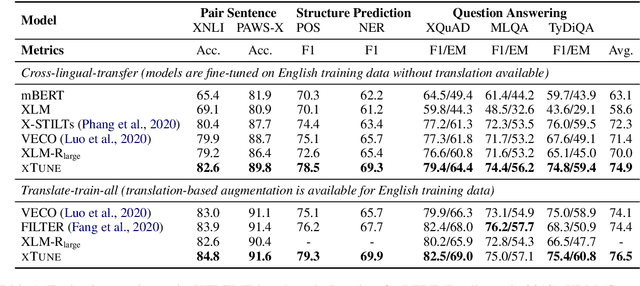
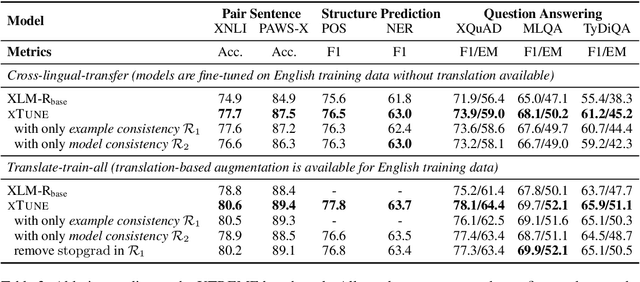
Fine-tuning pre-trained cross-lingual language models can transfer task-specific supervision from one language to the others. In this work, we propose to improve cross-lingual fine-tuning with consistency regularization. Specifically, we use example consistency regularization to penalize the prediction sensitivity to four types of data augmentations, i.e., subword sampling, Gaussian noise, code-switch substitution, and machine translation. In addition, we employ model consistency to regularize the models trained with two augmented versions of the same training set. Experimental results on the XTREME benchmark show that our method significantly improves cross-lingual fine-tuning across various tasks, including text classification, question answering, and sequence labeling.
XLM-T: Scaling up Multilingual Machine Translation with Pretrained Cross-lingual Transformer Encoders
Dec 31, 2020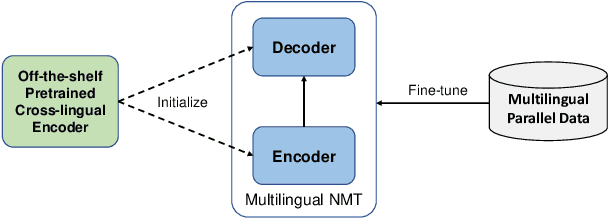
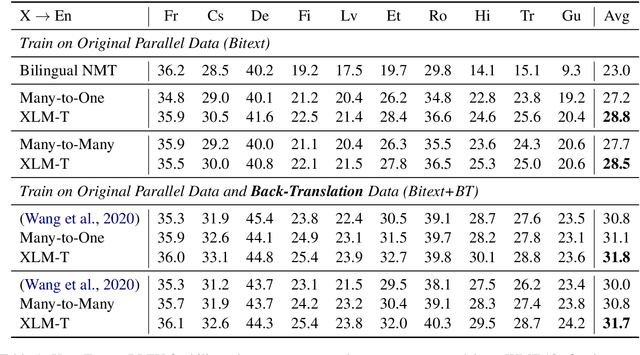
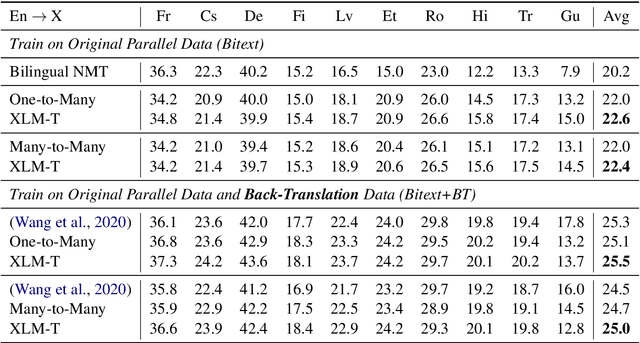

Multilingual machine translation enables a single model to translate between different languages. Most existing multilingual machine translation systems adopt a randomly initialized Transformer backbone. In this work, inspired by the recent success of language model pre-training, we present XLM-T, which initializes the model with an off-the-shelf pretrained cross-lingual Transformer encoder and fine-tunes it with multilingual parallel data. This simple method achieves significant improvements on a WMT dataset with 10 language pairs and the OPUS-100 corpus with 94 pairs. Surprisingly, the method is also effective even upon the strong baseline with back-translation. Moreover, extensive analysis of XLM-T on unsupervised syntactic parsing, word alignment, and multilingual classification explains its effectiveness for machine translation. The code will be at https://aka.ms/xlm-t.
InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training
Jul 15, 2020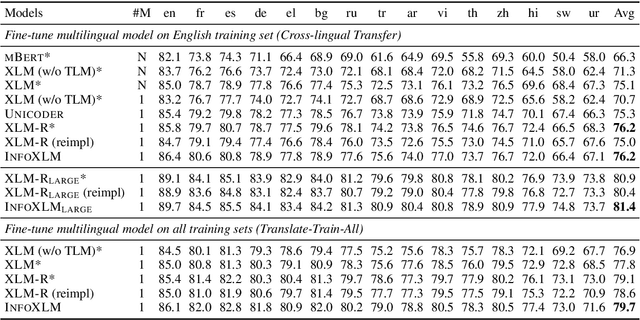
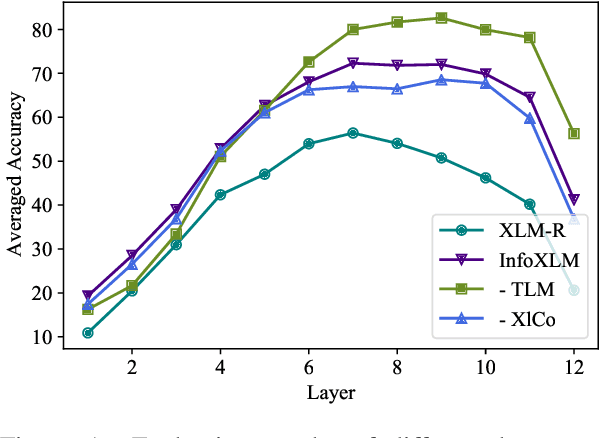
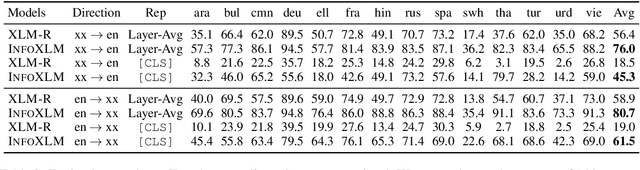
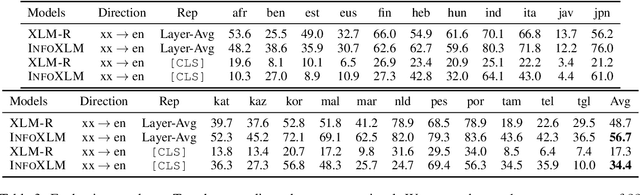
In this work, we formulate cross-lingual language model pre-training as maximizing mutual information between multilingual-multi-granularity texts. The unified view helps us to better understand the existing methods for learning cross-lingual representations. More importantly, the information-theoretic framework inspires us to propose a pre-training task based on contrastive learning. Given a bilingual sentence pair, we regard them as two views of the same meaning, and encourage their encoded representations to be more similar than the negative examples. By leveraging both monolingual and parallel corpora, we jointly train the pretext tasks to improve the cross-lingual transferability of pre-trained models. Experimental results on several benchmarks show that our approach achieves considerably better performance. The code and pre-trained models are available at http://aka.ms/infoxlm.