 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training
Paper and Code
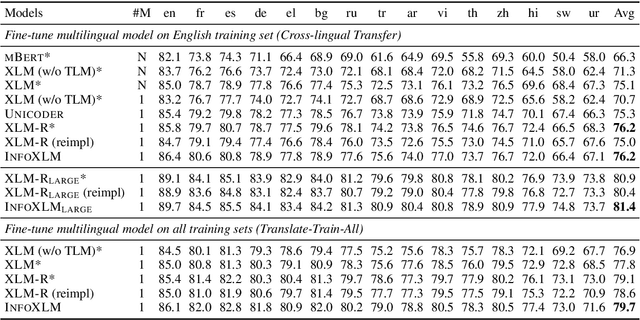
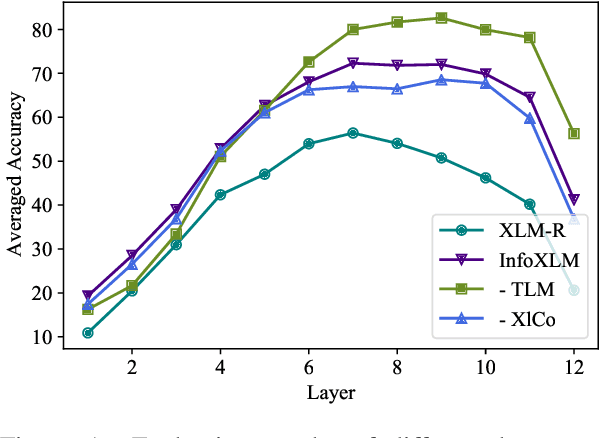
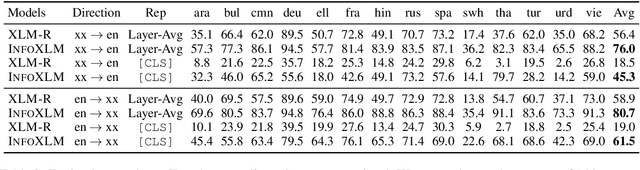
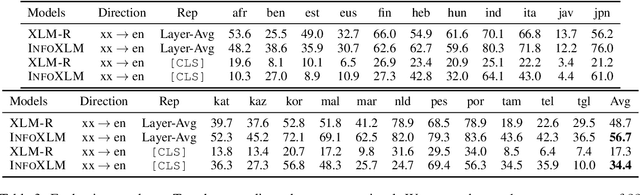
In this work, we formulate cross-lingual language model pre-training as maximizing mutual information between multilingual-multi-granularity texts. The unified view helps us to better understand the existing methods for learning cross-lingual representations. More importantly, the information-theoretic framework inspires us to propose a pre-training task based on contrastive learning. Given a bilingual sentence pair, we regard them as two views of the same meaning, and encourage their encoded representations to be more similar than the negative examples. By leveraging both monolingual and parallel corpora, we jointly train the pretext tasks to improve the cross-lingual transferability of pre-trained models. Experimental results on several benchmarks show that our approach achieves considerably better performance. The code and pre-trained models are available at http://aka.ms/infoxlm.