 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Structured Prediction with Language Models
Nov 17, 2022



Recent years have seen a paradigm shift in NLP towards using pretrained language models ({PLM}) for a wide range of tasks. However, there are many difficult design decisions to represent structures (e.g. tagged text, coreference chains) in a way such that they can be captured by PLMs. Prior work on structured prediction with PLMs typically flattens the structured output into a sequence, which limits the quality of structural information being learned and leads to inferior performance compared to classic discriminative models. In this work, we describe an approach to model structures as sequences of actions in an autoregressive manner with PLMs, allowing in-structure dependencies to be learned without any loss. Our approach achieves the new state-of-the-art on all the structured prediction tasks we looked at, namely, named entity recognition, end-to-end relation extraction, and coreference resolution.
The Architectural Bottleneck Principle
Nov 11, 2022In this paper, we seek to measure how much information a component in a neural network could extract from the representations fed into it. Our work stands in contrast to prior probing work, most of which investigates how much information a model's representations contain. This shift in perspective leads us to propose a new principle for probing, the architectural bottleneck principle: In order to estimate how much information a given component could extract, a probe should look exactly like the component. Relying on this principle, we estimate how much syntactic information is available to transformers through our attentional probe, a probe that exactly resembles a transformer's self-attention head. Experimentally, we find that, in three models (BERT, ALBERT, and RoBERTa), a sentence's syntax tree is mostly extractable by our probe, suggesting these models have access to syntactic information while composing their contextual representations. Whether this information is actually used by these models, however, remains an open question.
Mutual Information Alleviates Hallucinations in Abstractive Summarization
Oct 29, 2022Despite significant progress in the quality of language generated from abstractive summarization models, these models still exhibit the tendency to hallucinate, i.e., output content not supported by the source document. A number of works have tried to fix--or at least uncover the source of--the problem with limited success. In this paper, we identify a simple criterion under which models are significantly more likely to assign more probability to hallucinated content during generation: high model uncertainty. This finding offers a potential explanation for hallucinations: models default to favoring text with high marginal probability, i.e., high-frequency occurrences in the training set, when uncertain about a continuation. It also motivates possible routes for real-time intervention during decoding to prevent such hallucinations. We propose a decoding strategy that switches to optimizing for pointwise mutual information of the source and target token--rather than purely the probability of the target token--when the model exhibits uncertainty. Experiments on the XSum dataset show that our method decreases the probability of hallucinated tokens while maintaining the Rouge and BertS scores of top-performing decoding strategies.
A Bilingual Parallel Corpus with Discourse Annotations
Oct 26, 2022



Machine translation (MT) has almost achieved human parity at sentence-level translation. In response, the MT community has, in part, shifted its focus to document-level translation. However, the development of document-level MT systems is hampered by the lack of parallel document corpora. This paper describes BWB, a large parallel corpus first introduced in Jiang et al. (2022), along with an annotated test set. The BWB corpus consists of Chinese novels translated by experts into English, and the annotated test set is designed to probe the ability of machine translation systems to model various discourse phenomena. Our resource is freely available, and we hope it will serve as a guide and inspiration for more work in document-level machine translation.
Investigating the Role of Centering Theory in the Context of Neural Coreference Resolution Systems
Oct 26, 2022Centering theory (CT; Grosz et al., 1995) provides a linguistic analysis of the structure of discourse. According to the theory, local coherence of discourse arises from the manner and extent to which successive utterances make reference to the same entities. In this paper, we investigate the connection between centering theory and modern coreference resolution systems. We provide an operationalization of centering and systematically investigate if neural coreference resolvers adhere to the rules of centering theory by defining various discourse metrics and developing a search-based methodology. Our information-theoretic analysis reveals a positive dependence between coreference and centering; but also shows that high-quality neural coreference resolvers may not benefit much from explicitly modeling centering ideas. Our analysis further shows that contextualized embeddings contain much of the coherence information, which helps explain why CT can only provide little gains to modern neural coreference resolvers which make use of pretrained representations. Finally, we discuss factors that contribute to coreference which are not modeled by CT such as world knowledge and recency bias. We formulate a version of CT that also models recency and show that it captures coreference information better compared to vanilla CT.
Algorithms for Weighted Pushdown Automata
Oct 19, 2022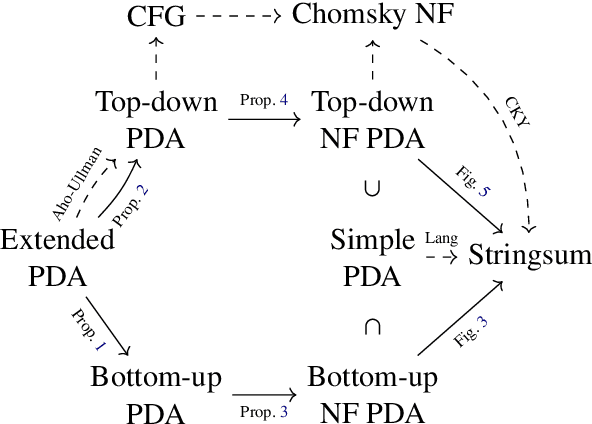
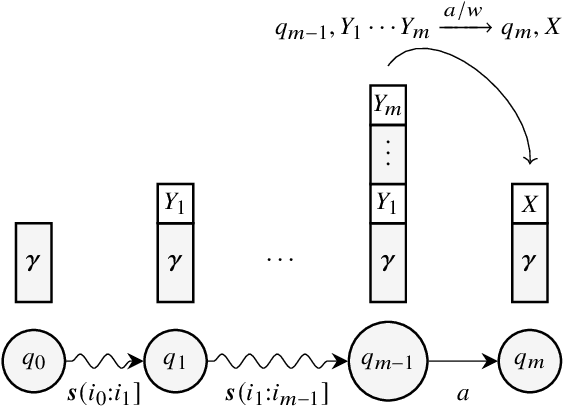
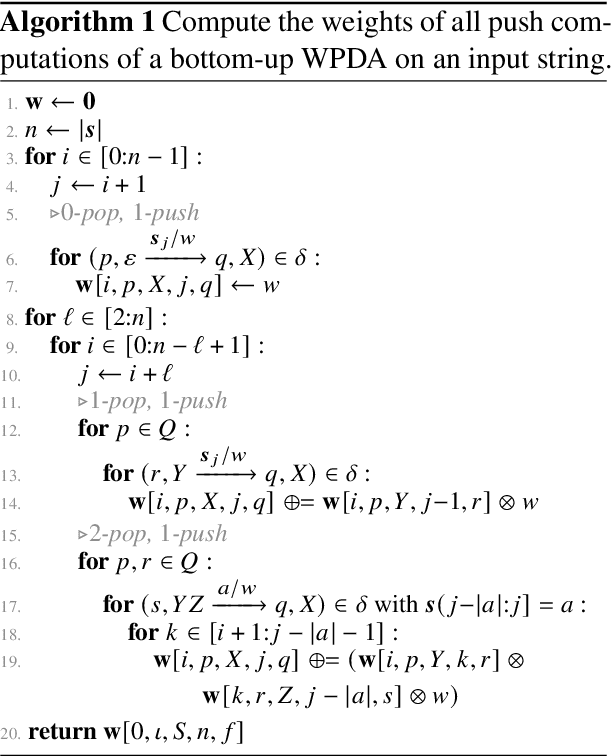
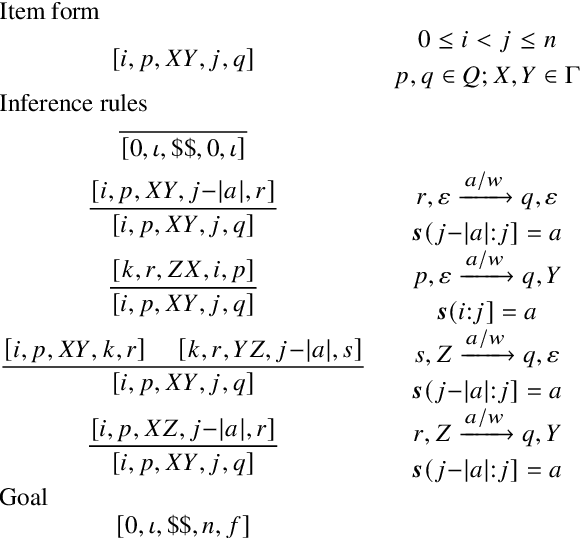
Weighted pushdown automata (WPDAs) are at the core of many natural language processing tasks, like syntax-based statistical machine translation and transition-based dependency parsing. As most existing dynamic programming algorithms are designed for context-free grammars (CFGs), algorithms for PDAs often resort to a PDA-to-CFG conversion. In this paper, we develop novel algorithms that operate directly on WPDAs. Our algorithms are inspired by Lang's algorithm, but use a more general definition of pushdown automaton and either reduce the space requirements by a factor of $|\Gamma|$ (the size of the stack alphabet) or reduce the runtime by a factor of more than $|Q|$ (the number of states). When run on the same class of PDAs as Lang's algorithm, our algorithm is both more space-efficient by a factor of $|\Gamma|$ and more time-efficient by a factor of $|Q| \cdot |\Gamma|$.
Linear Guardedness and its Implications
Oct 18, 2022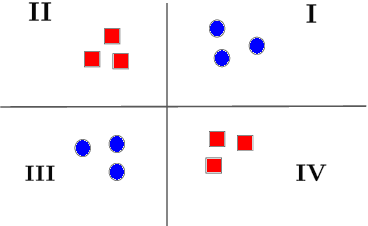
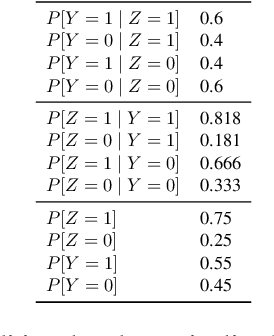
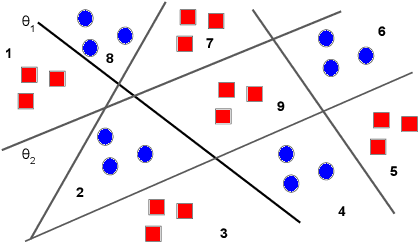
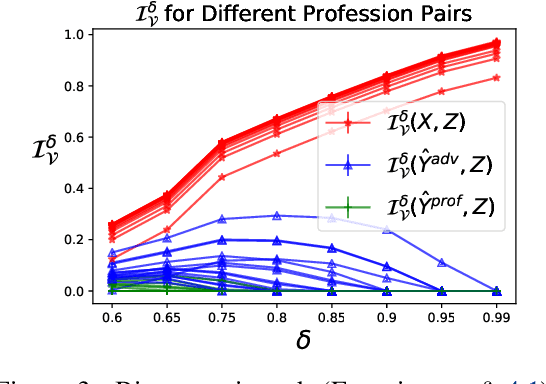
Previous work on concept identification in neural representations has focused on linear concept subspaces and their neutralization. In this work, we formulate the notion of linear guardedness -- the inability to directly predict a given concept from the representation -- and study its implications. We show that, in the binary case, the neutralized concept cannot be recovered by an additional linear layer. However, we point out that -- contrary to what was implicitly argued in previous works -- multiclass softmax classifiers can be constructed that indirectly recover the concept. Thus, linear guardedness does not guarantee that linear classifiers do not utilize the neutralized concepts, shedding light on theoretical limitations of linear information removal methods.
State-of-the-art generalisation research in NLP: a taxonomy and review
Oct 10, 2022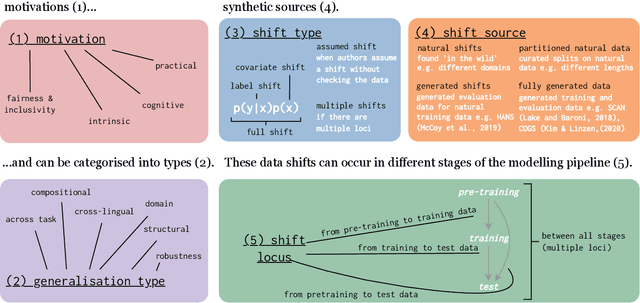
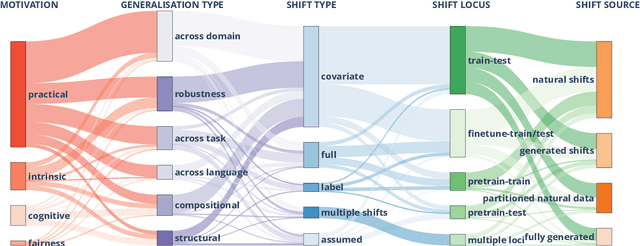
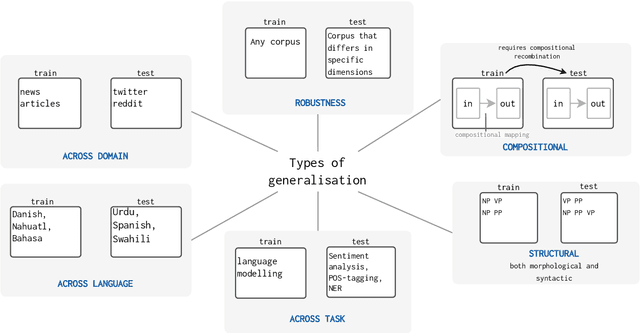

The ability to generalise well is one of the primary desiderata of natural language processing (NLP). Yet, what `good generalisation' entails and how it should be evaluated is not well understood, nor are there any common standards to evaluate it. In this paper, we aim to lay the ground-work to improve both of these issues. We present a taxonomy for characterising and understanding generalisation research in NLP, we use that taxonomy to present a comprehensive map of published generalisation studies, and we make recommendations for which areas might deserve attention in the future. Our taxonomy is based on an extensive literature review of generalisation research, and contains five axes along which studies can differ: their main motivation, the type of generalisation they aim to solve, the type of data shift they consider, the source by which this data shift is obtained, and the locus of the shift within the modelling pipeline. We use our taxonomy to classify over 400 previous papers that test generalisation, for a total of more than 600 individual experiments. Considering the results of this review, we present an in-depth analysis of the current state of generalisation research in NLP, and make recommendations for the future. Along with this paper, we release a webpage where the results of our review can be dynamically explored, and which we intend to up-date as new NLP generalisation studies are published. With this work, we aim to make steps towards making state-of-the-art generalisation testing the new status quo in NLP.
An Ordinal Latent Variable Model of Conflict Intensity
Oct 08, 2022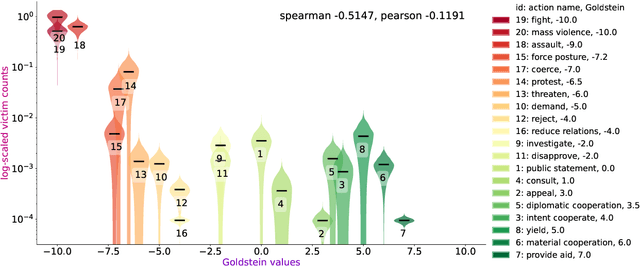
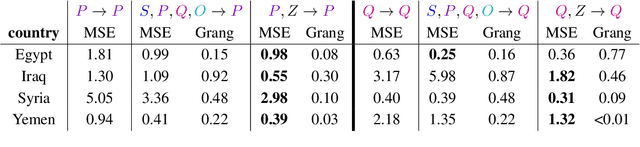
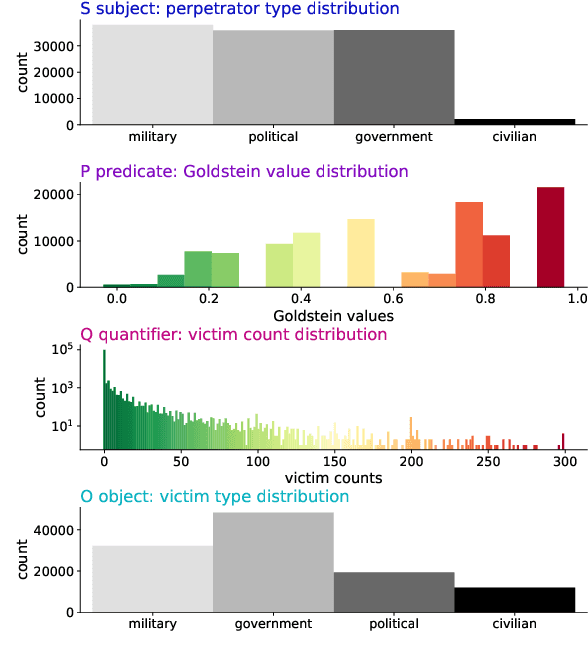

For the quantitative monitoring of international relations, political events are extracted from the news and parsed into "who-did-what-to-whom" patterns. This has resulted in large data collections which require aggregate statistics for analysis. The Goldstein Scale is an expert-based measure that ranks individual events on a one-dimensional scale from conflictual to cooperative. However, the scale disregards fatality counts as well as perpetrator and victim types involved in an event. This information is typically considered in qualitative conflict assessment. To address this limitation, we propose a probabilistic generative model over the full subject-predicate-quantifier-object tuples associated with an event. We treat conflict intensity as an interpretable, ordinal latent variable that correlates conflictual event types with high fatality counts. Taking a Bayesian approach, we learn a conflict intensity scale from data and find the optimal number of intensity classes. We evaluate the model by imputing missing data. Our scale proves to be more informative than the original Goldstein Scale in autoregressive forecasting and when compared with global online attention towards armed conflicts.
Equivariant Transduction through Invariant Alignment
Sep 22, 2022



The ability to generalize compositionally is key to understanding the potentially infinite number of sentences that can be constructed in a human language from only a finite number of words. Investigating whether NLP models possess this ability has been a topic of interest: SCAN (Lake and Baroni, 2018) is one task specifically proposed to test for this property. Previous work has achieved impressive empirical results using a group-equivariant neural network that naturally encodes a useful inductive bias for SCAN (Gordon et al., 2020). Inspired by this, we introduce a novel group-equivariant architecture that incorporates a group-invariant hard alignment mechanism. We find that our network's structure allows it to develop stronger equivariance properties than existing group-equivariant approaches. We additionally find that it outperforms previous group-equivariant networks empirically on the SCAN task. Our results suggest that integrating group-equivariance into a variety of neural architectures is a potentially fruitful avenue of research, and demonstrate the value of careful analysis of the theoretical properties of such architectures.