 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SIGMORPHON 2022 Shared Task on Morpheme Segmentation
Jun 15, 2022
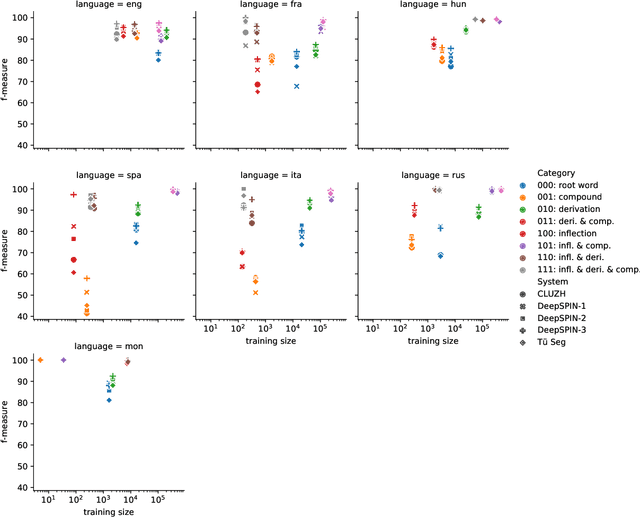
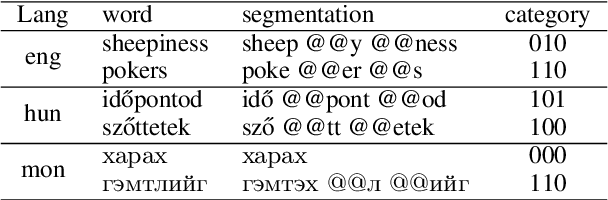
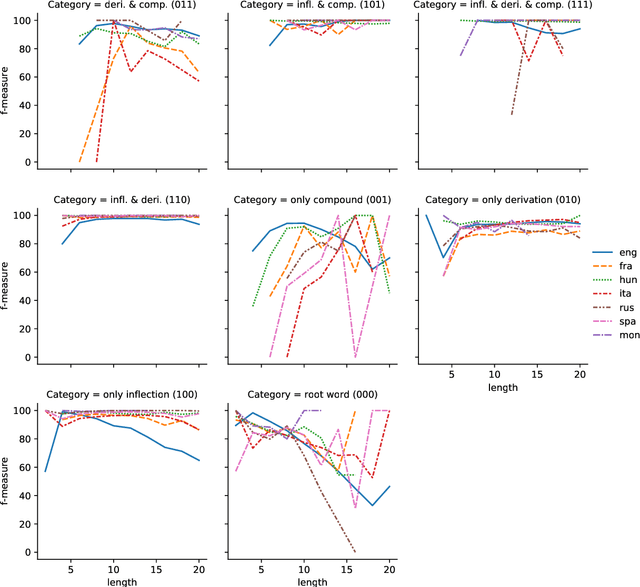
The SIGMORPHON 2022 shared task on morpheme segmentation challenged systems to decompose a word into a sequence of morphemes and covered most types of morphology: compounds, derivations, and inflections. Subtask 1, word-level morpheme segmentation, covered 5 million words in 9 languages (Czech, English, Spanish, Hungarian, French, Italian, Russian, Latin, Mongolian) and received 13 system submissions from 7 teams and the best system averaged 97.29% F1 score across all languages, ranging English (93.84%) to Latin (99.38%). Subtask 2, sentence-level morpheme segmentation, covered 18,735 sentences in 3 languages (Czech, English, Mongolian), received 10 system submissions from 3 teams, and the best systems outperformed all three state-of-the-art subword tokenization methods (BPE, ULM, Morfessor2) by 30.71% absolute. To facilitate error analysis and support any type of future studies, we released all system predictions, the evaluation script, and all gold standard datasets.
Using Linguistic Typology to Enrich Multilingual Lexicons: the Case of Lexical Gaps in Kinship
Apr 11, 2022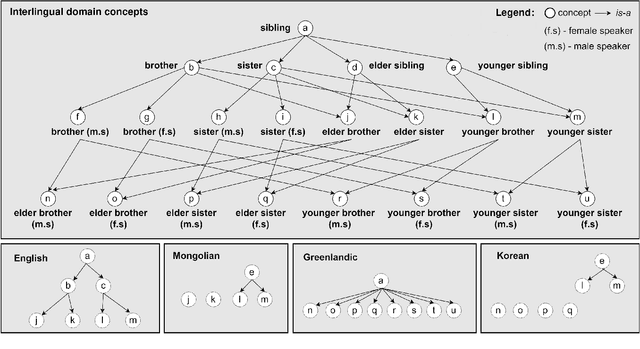
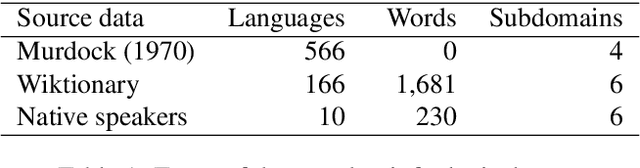
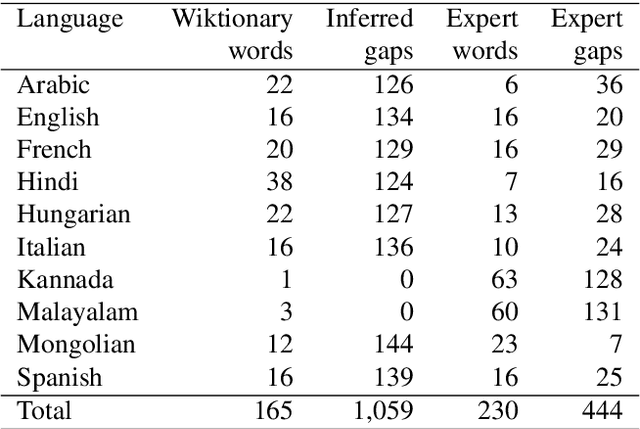

This paper describes a method to enrich lexical resources with content relating to linguistic diversity, based on knowledge from the field of lexical typology. We capture the phenomenon of diversity through the notions of lexical gap and language-specific word and use a systematic method to infer gaps semi-automatically on a large scale. As a first result obtained for the domain of kinship terminology, known to be very diverse throughout the world, we publish a lexico-semantic resource consisting of 198 domain concepts, 1,911 words, and 37,370 gaps covering 699 languages. We see potential in the use of resources such as ours for the improvement of a variety of cross-lingual NLP tasks, which we demonstrate through a downstream application for the evaluation of machine translation systems.