 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective
Sep 18, 2022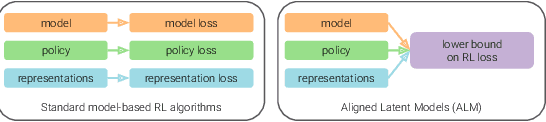
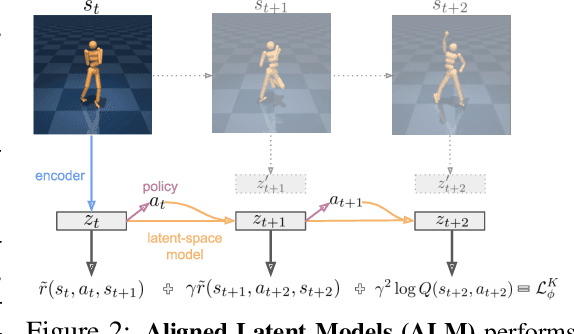
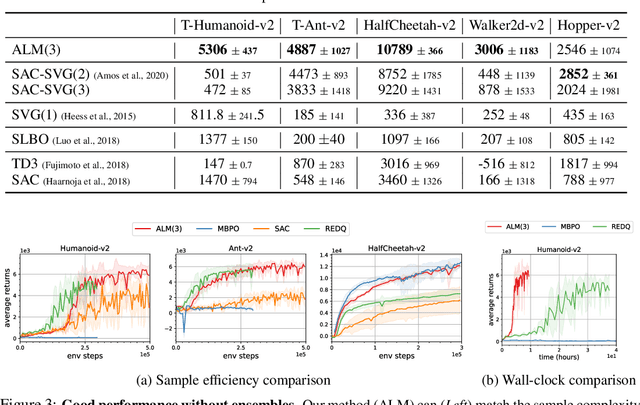
While reinforcement learning (RL) methods that learn an internal model of the environment have the potential to be more sample efficient than their model-free counterparts, learning to model raw observations from high dimensional sensors can be challenging. Prior work has addressed this challenge by learning low-dimensional representation of observations through auxiliary objectives, such as reconstruction or value prediction. However, the alignment between these auxiliary objectives and the RL objective is often unclear. In this work, we propose a single objective which jointly optimizes a latent-space model and policy to achieve high returns while remaining self-consistent. This objective is a lower bound on expected returns. Unlike prior bounds for model-based RL on policy exploration or model guarantees, our bound is directly on the overall RL objective. We demonstrate that the resulting algorithm matches or improves the sample-efficiency of the best prior model-based and model-free RL methods. While such sample efficient methods typically are computationally demanding, our method attains the performance of SAC in about 50\% less wall-clock time.
Scalable Privacy-enhanced Benchmark Graph Generative Model for Graph Convolutional Networks
Jul 10, 2022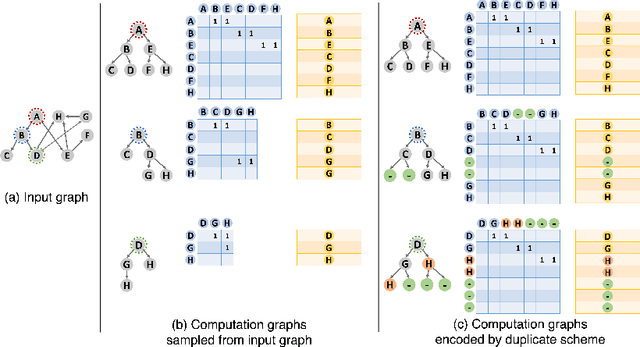
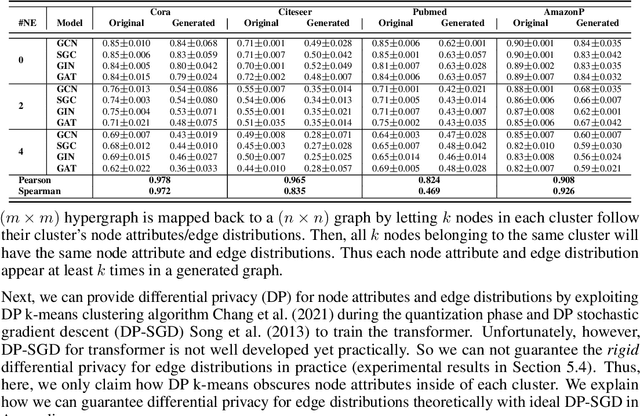
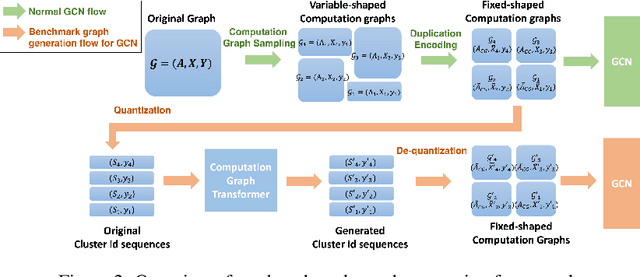
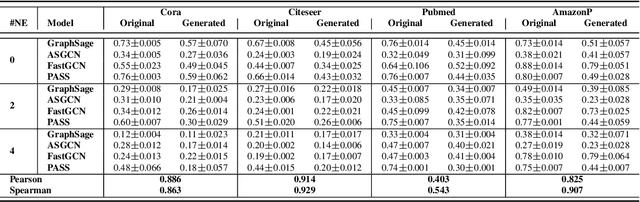
A surge of interest in Graph Convolutional Networks (GCN) has produced thousands of GCN variants, with hundreds introduced every year. In contrast, many GCN models re-use only a handful of benchmark datasets as many graphs of interest, such as social or commercial networks, are proprietary. We propose a new graph generation problem to enable generating a diverse set of benchmark graphs for GCNs following the distribution of a source graph -- possibly proprietary -- with three requirements: 1) benchmark effectiveness as a substitute for the source graph for GCN research, 2) scalability to process large-scale real-world graphs, and 3) a privacy guarantee for end-users. With a novel graph encoding scheme, we reframe large-scale graph generation problem into medium-length sequence generation problem and apply the strong generation power of the Transformer architecture to the graph domain. Extensive experiments across a vast body of graph generative models show that our model can successfully generate benchmark graphs with the realistic graph structure, node attributes, and node labels required to benchmark GCNs on node classification tasks.
MultiViz: An Analysis Benchmark for Visualizing and Understanding Multimodal Models
Jun 30, 2022


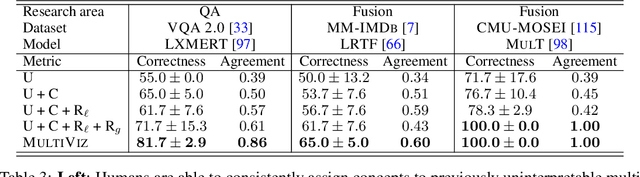
The promise of multimodal models for real-world applications has inspired research in visualizing and understanding their internal mechanics with the end goal of empowering stakeholders to visualize model behavior, perform model debugging, and promote trust in machine learning models. However, modern multimodal models are typically black-box neural networks, which makes it challenging to understand their internal mechanics. How can we visualize the internal modeling of multimodal interactions in these models? Our paper aims to fill this gap by proposing MultiViz, a method for analyzing the behavior of multimodal models by scaffolding the problem of interpretability into 4 stages: (1) unimodal importance: how each modality contributes towards downstream modeling and prediction, (2) cross-modal interactions: how different modalities relate with each other, (3) multimodal representations: how unimodal and cross-modal interactions are represented in decision-level features, and (4) multimodal prediction: how decision-level features are composed to make a prediction. MultiViz is designed to operate on diverse modalities, models, tasks, and research areas. Through experiments on 8 trained models across 6 real-world tasks, we show that the complementary stages in MultiViz together enable users to (1) simulate model predictions, (2) assign interpretable concepts to features, (3) perform error analysis on model misclassifications, and (4) use insights from error analysis to debug models. MultiViz is publicly available, will be regularly updated with new interpretation tools and metrics, and welcomes inputs from the community.
A Simple Approach for Visual Rearrangement: 3D Mapping and Semantic Search
Jun 21, 2022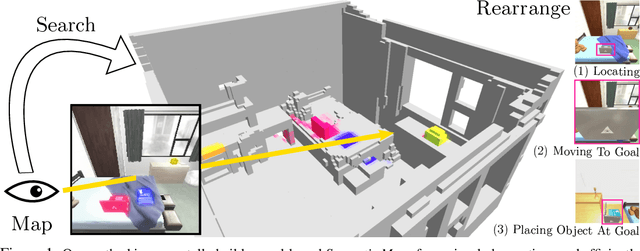
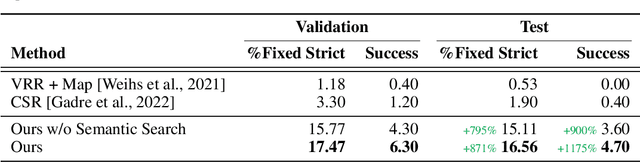
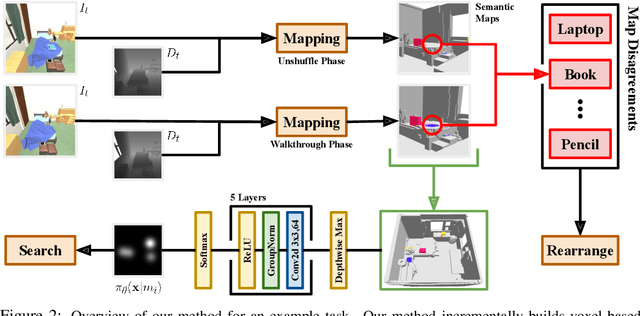
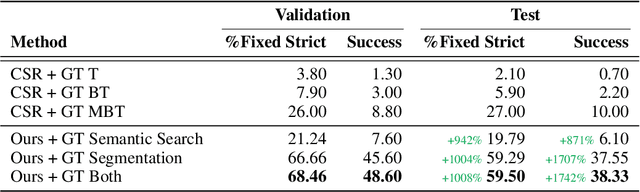
Physically rearranging objects is an important capability for embodied agents. Visual room rearrangement evaluates an agent's ability to rearrange objects in a room to a desired goal based solely on visual input. We propose a simple yet effective method for this problem: (1) search for and map which objects need to be rearranged, and (2) rearrange each object until the task is complete. Our approach consists of an off-the-shelf semantic segmentation model, voxel-based semantic map, and semantic search policy to efficiently find objects that need to be rearranged. On the AI2-THOR Rearrangement Challenge, our method improves on current state-of-the-art end-to-end reinforcement learning-based methods that learn visual rearrangement policies from 0.53% correct rearrangement to 16.56%, using only 2.7% as many samples from the environment.
Contrastive Learning as Goal-Conditioned Reinforcement Learning
Jun 15, 2022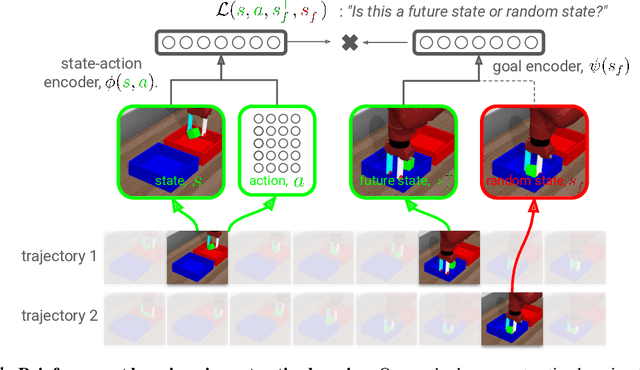
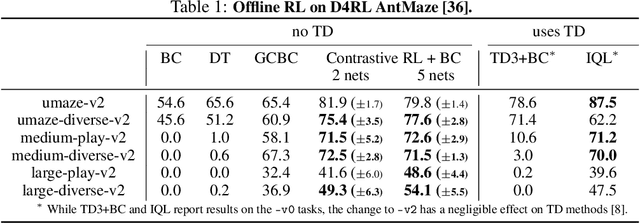
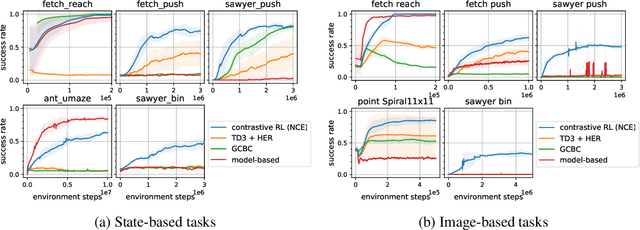
In reinforcement learning (RL), it is easier to solve a task if given a good representation. While deep RL should automatically acquire such good representations, prior work often finds that learning representations in an end-to-end fashion is unstable and instead equip RL algorithms with additional representation learning parts (e.g., auxiliary losses, data augmentation). How can we design RL algorithms that directly acquire good representations? In this paper, instead of adding representation learning parts to an existing RL algorithm, we show (contrastive) representation learning methods can be cast as RL algorithms in their own right. To do this, we build upon prior work and apply contrastive representation learning to action-labeled trajectories, in such a way that the (inner product of) learned representations exactly corresponds to a goal-conditioned value function. We use this idea to reinterpret a prior RL method as performing contrastive learning, and then use the idea to propose a much simpler method that achieves similar performance. Across a range of goal-conditioned RL tasks, we demonstrate that contrastive RL methods achieve higher success rates than prior non-contrastive methods, including in the offline RL setting. We also show that contrastive RL outperforms prior methods on image-based tasks, without using data augmentation or auxiliary objectives.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Imitating Past Successes can be Very Suboptimal
Jun 07, 2022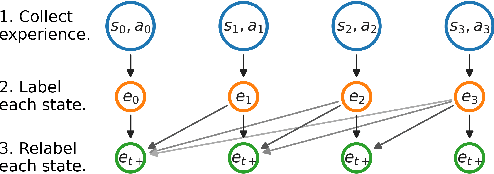
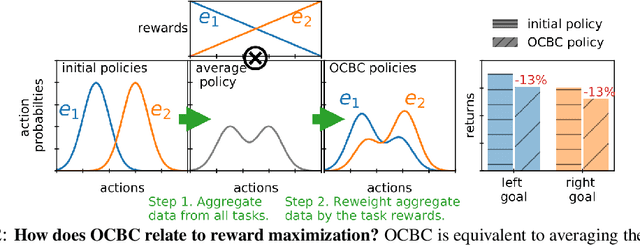
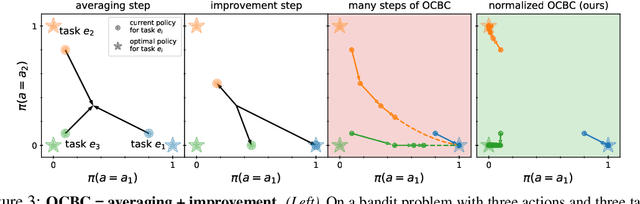
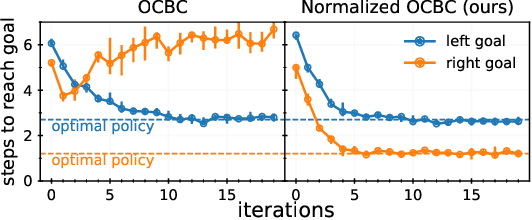
Prior work has proposed a simple strategy for reinforcement learning (RL): label experience with the outcomes achieved in that experience, and then imitate the relabeled experience. These outcome-conditioned imitation learning methods are appealing because of their simplicity, strong performance, and close ties with supervised learning. However, it remains unclear how these methods relate to the standard RL objective, reward maximization. In this paper, we prove that existing outcome-conditioned imitation learning methods do not necessarily improve the policy; rather, in some settings they can decrease the expected reward. Nonetheless, we show that a simple modification results in a method that does guarantee policy improvement, under some assumptions. Our aim is not to develop an entirely new method, but rather to explain how a variant of outcome-conditioned imitation learning can be used to maximize rewards.
Reasoning over Logically Interacted Conditions for Question Answering
May 25, 2022

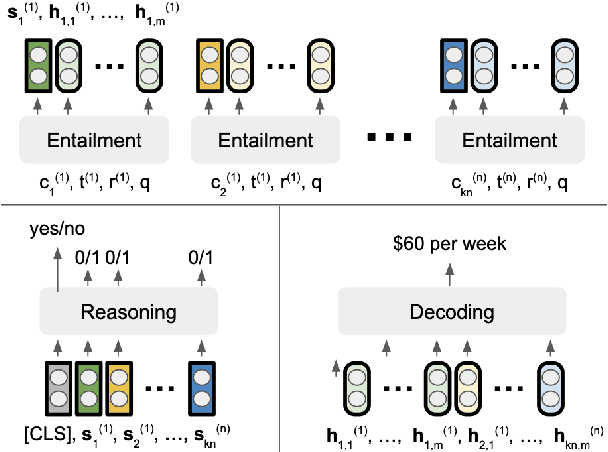
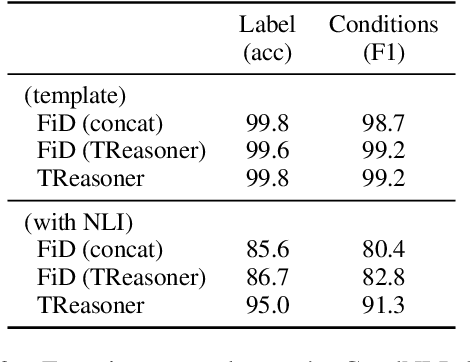
Some questions have multiple answers that are not equally correct, i.e. answers are different under different conditions. Conditions are used to distinguish answers as well as to provide additional information to support them. In this paper, we study a more challenging task where answers are constrained by a list of conditions that logically interact, which requires performing logical reasoning over the conditions to determine the correctness of the answers. Even more challenging, we only provide evidences for a subset of the conditions, so some questions may not have deterministic answers. In such cases, models are asked to find probable answers and identify conditions that need to be satisfied to make the answers correct. We propose a new model, TReasoner, for this challenging reasoning task. TReasoner consists of an entailment module, a reasoning module, and a generation module (if the answers are free-form text spans). TReasoner achieves state-of-the-art performance on two benchmark conditional QA datasets, outperforming the previous state-of-the-art by 3-10 points.
PACS: A Dataset for Physical Audiovisual CommonSense Reasoning
Mar 21, 2022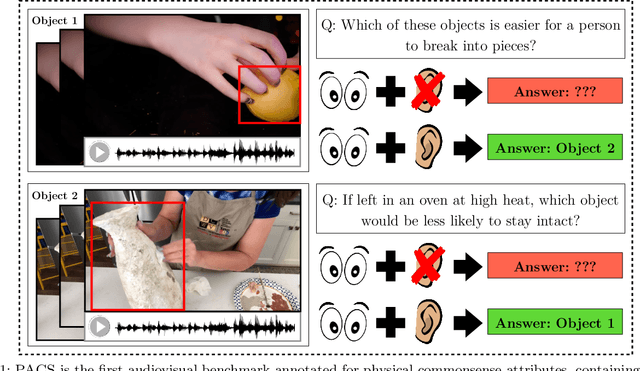
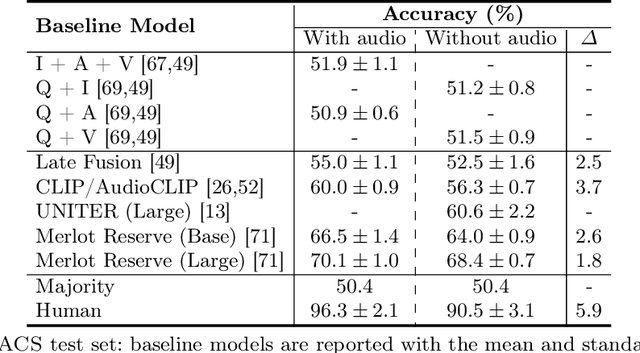
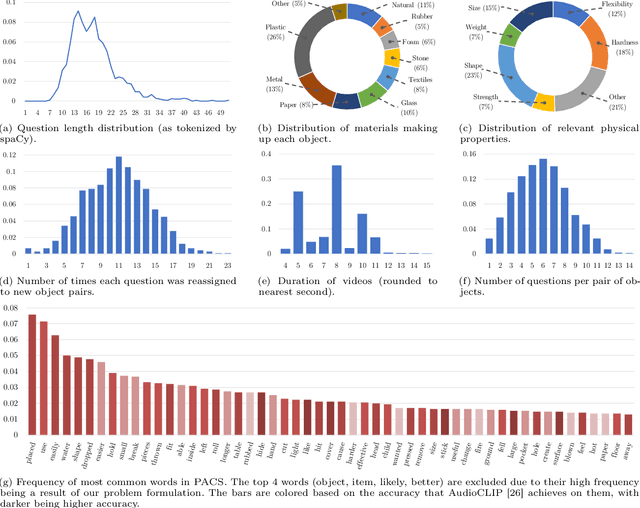
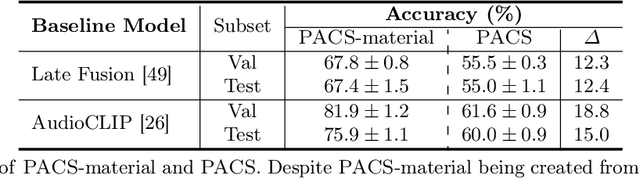
In order for AI to be safely deployed in real-world scenarios such as hospitals, schools, and the workplace, they should be able to reason about the physical world by understanding the physical properties and affordances of available objects, how they can be manipulated, and how they interact with other physical objects. This research field of physical commonsense reasoning is fundamentally a multi-sensory task since physical properties are manifested through multiple modalities, two of them being vision and acoustics. Our paper takes a step towards real-world physical commonsense reasoning by contributing PACS: the first audiovisual benchmark annotated for physical commonsense attributes. PACS contains a total of 13,400 question-answer pairs, involving 1,377 unique physical commonsense questions and 1,526 videos. Our dataset provides new opportunities to advance the research field of physical reasoning by bringing audio as a core component of this multimodal problem. Using PACS, we evaluate multiple state-of-the-art models on this new challenging task. While some models show promising results (70% accuracy), they all fall short of human performance (95% accuracy). We conclude the paper by demonstrating the importance of multimodal reasoning and providing possible avenues for future research.
HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
Mar 04, 2022
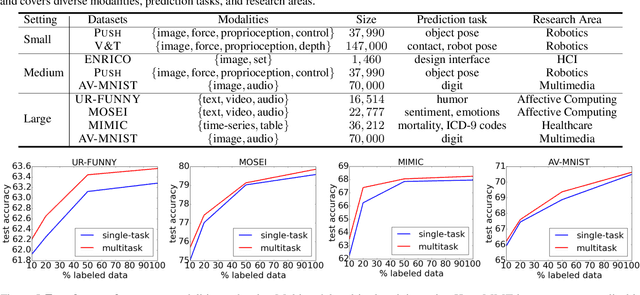
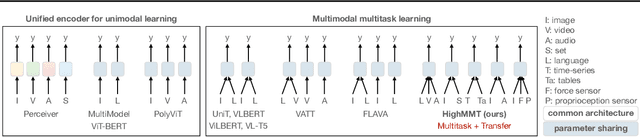
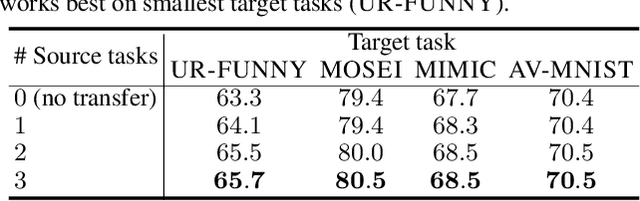
Learning multimodal representations involves discovering correspondences and integrating information from multiple heterogeneous sources of data. While recent research has begun to explore the design of more general-purpose multimodal models (contrary to prior focus on domain and modality-specific architectures), these methods are still largely focused on a small set of modalities in the language, vision, and audio space. In order to accelerate generalization towards diverse and understudied modalities, we investigate methods for high-modality (a large set of diverse modalities) and partially-observable (each task only defined on a small subset of modalities) scenarios. To tackle these challenges, we design a general multimodal model that enables multitask and transfer learning: multitask learning with shared parameters enables stable parameter counts (addressing scalability), and cross-modal transfer learning enables information sharing across modalities and tasks (addressing partial observability). Our resulting model generalizes across text, image, video, audio, time-series, sensors, tables, and set modalities from different research areas, improves the tradeoff between performance and efficiency, transfers to new modalities and tasks, and reveals surprising insights on the nature of information sharing in multitask models. We release our code and benchmarks which we hope will present a unified platform for subsequent theoretical and empirical analysis: https://github.com/pliang279/HighMMT.