 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan, Eliminate, and Track -- Language Models are Good Teachers for Embodied Agents
May 07, 2023Pre-trained large language models (LLMs) capture procedural knowledge about the world. Recent work has leveraged LLM's ability to generate abstract plans to simplify challenging control tasks, either by action scoring, or action modeling (fine-tuning). However, the transformer architecture inherits several constraints that make it difficult for the LLM to directly serve as the agent: e.g. limited input lengths, fine-tuning inefficiency, bias from pre-training, and incompatibility with non-text environments. To maintain compatibility with a low-level trainable actor, we propose to instead use the knowledge in LLMs to simplify the control problem, rather than solving it. We propose the Plan, Eliminate, and Track (PET) framework. The Plan module translates a task description into a list of high-level sub-tasks. The Eliminate module masks out irrelevant objects and receptacles from the observation for the current sub-task. Finally, the Track module determines whether the agent has accomplished each sub-task. On the AlfWorld instruction following benchmark, the PET framework leads to a significant 15% improvement over SOTA for generalization to human goal specifications.
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.
Effective Data Augmentation With Diffusion Models
Feb 07, 2023Data augmentation is one of the most prevalent tools in deep learning, underpinning many recent advances, including those from classification, generative models, and representation learning. The standard approach to data augmentation combines simple transformations like rotations and flips to generate new images from existing ones. However, these new images lack diversity along key semantic axes present in the data. Consider the task of recognizing different animals. Current augmentations fail to produce diversity in task-relevant high-level semantic attributes like the species of the animal. We address the lack of diversity in data augmentation with image-to-image transformations parameterized by pre-trained text-to-image diffusion models. Our method edits images to change their semantics using an off-the-shelf diffusion model, and generalizes to novel visual concepts from a few labelled examples. We evaluate our approach on image classification tasks in a few-shot setting, and on a real-world weed recognition task, and observe an improvement in accuracy in tested domains.
Grounding Language Models to Images for Multimodal Generation
Jan 31, 2023



We propose an efficient method to ground pretrained text-only language models to the visual domain, enabling them to process and generate arbitrarily interleaved image-and-text data. Our method leverages the abilities of language models learnt from large scale text-only pretraining, such as in-context learning and free-form text generation. We keep the language model frozen, and finetune input and output linear layers to enable cross-modality interactions. This allows our model to process arbitrarily interleaved image-and-text inputs, and generate free-form text interleaved with retrieved images. We achieve strong zero-shot performance on grounded tasks such as contextual image retrieval and multimodal dialogue, and showcase compelling interactive abilities. Our approach works with any off-the-shelf language model and paves the way towards an effective, general solution for leveraging pretrained language models in visually grounded settings.
Cross-modal Attention Congruence Regularization for Vision-Language Relation Alignment
Dec 20, 2022



Despite recent progress towards scaling up multimodal vision-language models, these models are still known to struggle on compositional generalization benchmarks such as Winoground. We find that a critical component lacking from current vision-language models is relation-level alignment: the ability to match directional semantic relations in text (e.g., "mug in grass") with spatial relationships in the image (e.g., the position of the mug relative to the grass). To tackle this problem, we show that relation alignment can be enforced by encouraging the directed language attention from 'mug' to 'grass' (capturing the semantic relation 'in') to match the directed visual attention from the mug to the grass. Tokens and their corresponding objects are softly identified using the cross-modal attention. We prove that this notion of soft relation alignment is equivalent to enforcing congruence between vision and language attention matrices under a 'change of basis' provided by the cross-modal attention matrix. Intuitively, our approach projects visual attention into the language attention space to calculate its divergence from the actual language attention, and vice versa. We apply our Cross-modal Attention Congruence Regularization (CACR) loss to UNITER and improve on the state-of-the-art approach to Winoground.
Object Goal Navigation with End-to-End Self-Supervision
Dec 09, 2022



A household robot should be able to navigate to target locations without requiring users to first annotate everything in their home. Current approaches to this object navigation challenge do not test on real robots and rely on expensive semantically labeled 3D meshes. In this work, our aim is an agent that builds self-supervised models of the world via exploration, the same as a child might. We propose an end-to-end self-supervised embodied agent that leverages exploration to train a semantic segmentation model of 3D objects, and uses those representations to learn an object navigation policy purely from self-labeled 3D meshes. The key insight is that embodied agents can leverage location consistency as a supervision signal - collecting images from different views/angles and applying contrastive learning to fine-tune a semantic segmentation model. In our experiments, we observe that our framework performs better than other self-supervised baselines and competitively with supervised baselines, in both simulation and when deployed in real houses.
Nano: Nested Human-in-the-Loop Reward Learning for Few-shot Language Model Control
Nov 10, 2022



Pretrained language models have demonstrated extraordinary capabilities in language generation. However, real-world tasks often require controlling the distribution of generated text in order to mitigate bias, promote fairness, and achieve personalization. Existing techniques for controlling the distribution of generated text only work with quantified distributions, which require pre-defined categories, proportions of the distribution, or an existing corpus following the desired distributions. However, many important distributions, such as personal preferences, are unquantified. In this work, we tackle the problem of generating text following arbitrary distributions (quantified and unquantified) by proposing Nano, a few-shot human-in-the-loop training algorithm that continuously learns from human feedback. Nano achieves state-of-the-art results on single topic/attribute as well as quantified distribution control compared to previous works. We also show that Nano is able to learn unquantified distributions, achieves personalization, and captures differences between different individuals' personal preferences with high sample efficiency.
Don't Copy the Teacher: Data and Model Challenges in Embodied Dialogue
Oct 11, 2022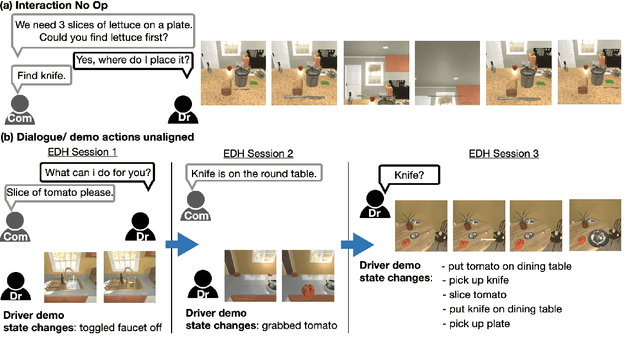
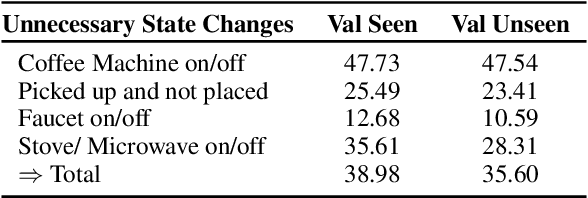
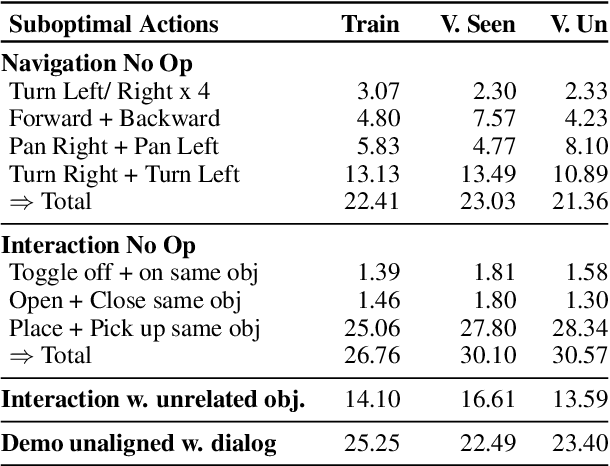
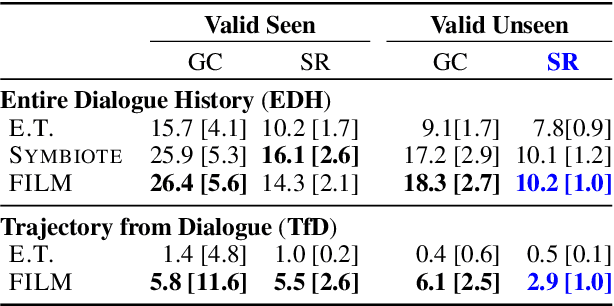
Embodied dialogue instruction following requires an agent to complete a complex sequence of tasks from a natural language exchange. The recent introduction of benchmarks (Padmakumar et al., 2022) raises the question of how best to train and evaluate models for this multi-turn, multi-agent, long-horizon task. This paper contributes to that conversation, by arguing that imitation learning (IL) and related low-level metrics are actually misleading and do not align with the goals of embodied dialogue research and may hinder progress. We provide empirical comparisons of metrics, analysis of three models, and make suggestions for how the field might best progress. First, we observe that models trained with IL take spurious actions during evaluation. Second, we find that existing models fail to ground query utterances, which are essential for task completion. Third, we argue evaluation should focus on higher-level semantic goals.
Uncertainty Quantification with Pre-trained Language Models: A Large-Scale Empirical Analysis
Oct 10, 2022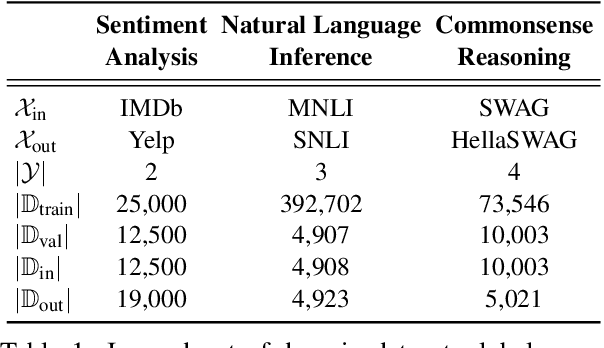
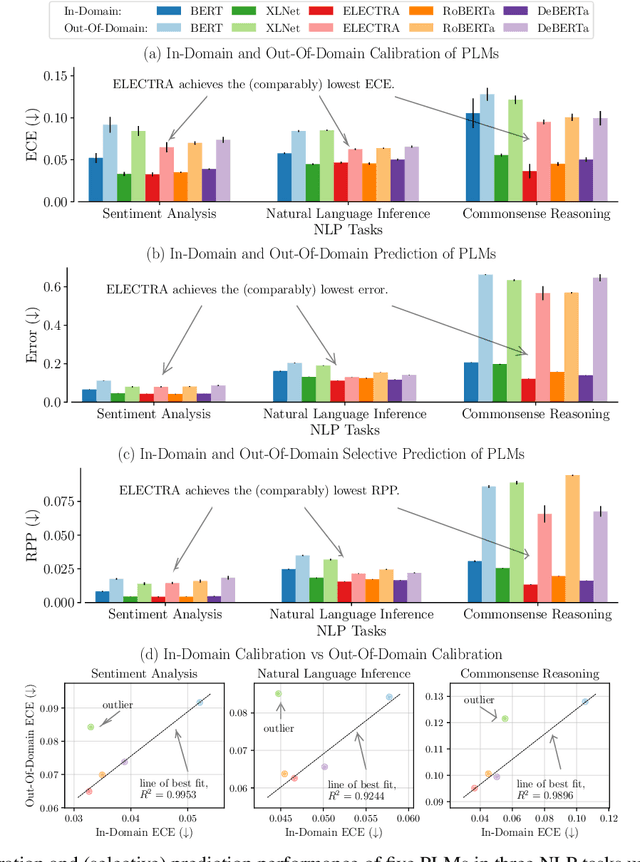
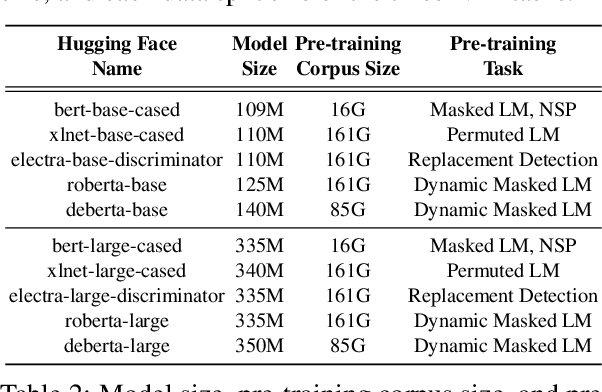
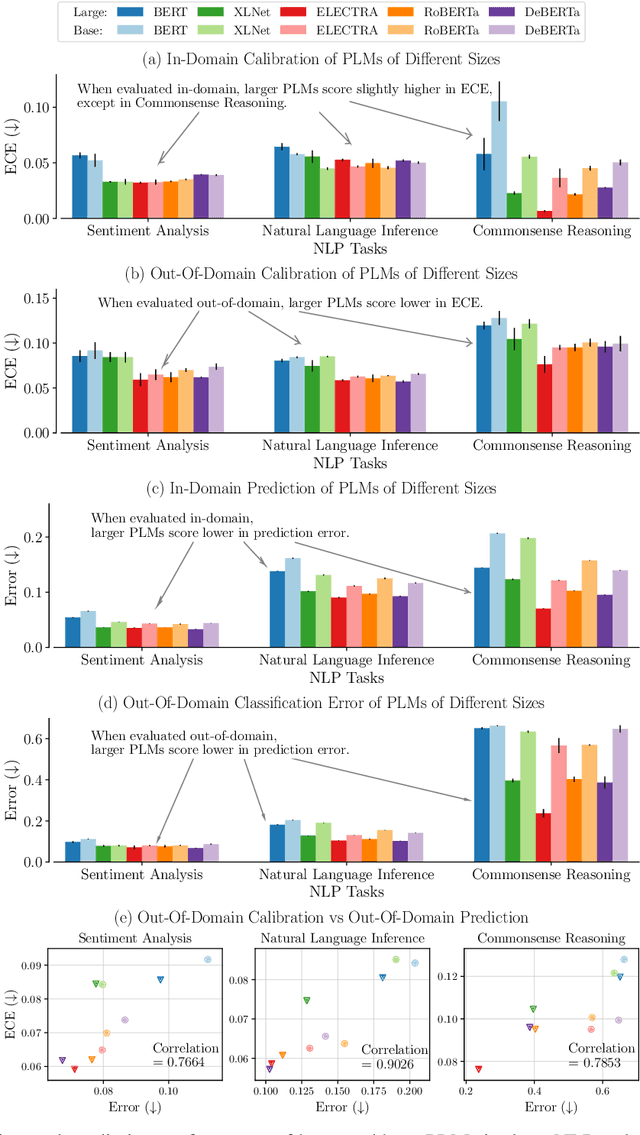
Pre-trained language models (PLMs) have gained increasing popularity due to their compelling prediction performance in diverse natural language processing (NLP) tasks. When formulating a PLM-based prediction pipeline for NLP tasks, it is also crucial for the pipeline to minimize the calibration error, especially in safety-critical applications. That is, the pipeline should reliably indicate when we can trust its predictions. In particular, there are various considerations behind the pipeline: (1) the choice and (2) the size of PLM, (3) the choice of uncertainty quantifier, (4) the choice of fine-tuning loss, and many more. Although prior work has looked into some of these considerations, they usually draw conclusions based on a limited scope of empirical studies. There still lacks a holistic analysis on how to compose a well-calibrated PLM-based prediction pipeline. To fill this void, we compare a wide range of popular options for each consideration based on three prevalent NLP classification tasks and the setting of domain shift. In response, we recommend the following: (1) use ELECTRA for PLM encoding, (2) use larger PLMs if possible, (3) use Temp Scaling as the uncertainty quantifier, and (4) use Focal Loss for fine-tuning.
Paraphrasing Is All You Need for Novel Object Captioning
Sep 25, 2022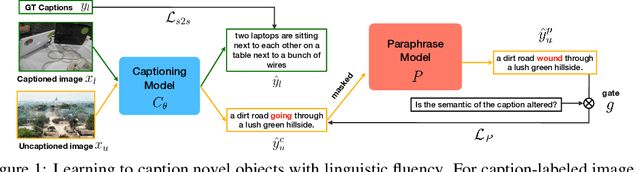
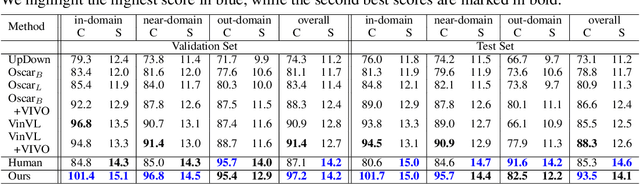
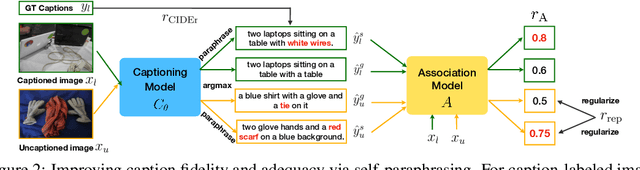
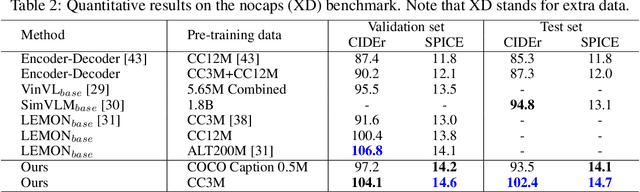
Novel object captioning (NOC) aims to describe images containing objects without observing their ground truth captions during training. Due to the absence of caption annotation, captioning models cannot be directly optimized via sequence-to-sequence training or CIDEr optimization. As a result, we present Paraphrasing-to-Captioning (P2C), a two-stage learning framework for NOC, which would heuristically optimize the output captions via paraphrasing. With P2C, the captioning model first learns paraphrasing from a language model pre-trained on text-only corpus, allowing expansion of the word bank for improving linguistic fluency. To further enforce the output caption sufficiently describing the visual content of the input image, we perform self-paraphrasing for the captioning model with fidelity and adequacy objectives introduced. Since no ground truth captions are available for novel object images during training, our P2C leverages cross-modality (image-text) association modules to ensure the above caption characteristics can be properly preserved. In the experiments, we not only show that our P2C achieves state-of-the-art performances on nocaps and COCO Caption datasets, we also verify the effectiveness and flexibility of our learning framework by replacing language and cross-modality association models for NOC. Implementation details and code are available in the supplementary materials.