 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Data Manipulation for Augmentation and Weighting
Oct 28, 2019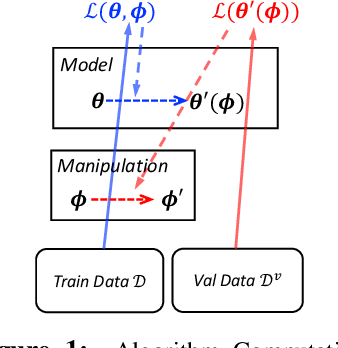
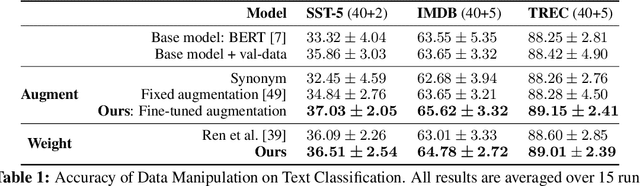
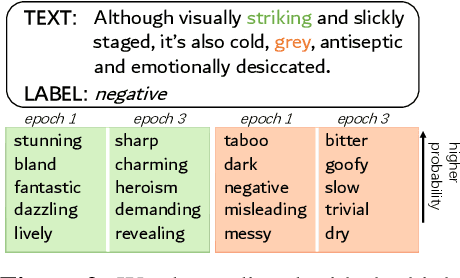
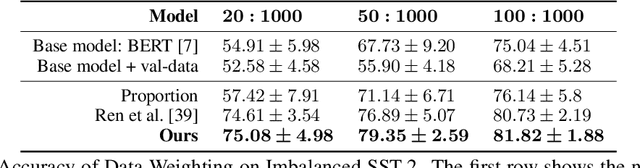
Manipulating data, such as weighting data examples or augmenting with new instances, has been increasingly used to improve model training. Previous work has studied various rule- or learning-based approaches designed for specific types of data manipulation. In this work, we propose a new method that supports learning different manipulation schemes with the same gradient-based algorithm. Our approach builds upon a recent connection of supervised learning and reinforcement learning (RL), and adapts an off-the-shelf reward learning algorithm from RL for joint data manipulation learning and model training. Different parameterization of the "data reward" function instantiates different manipulation schemes. We showcase data augmentation that learns a text transformation network, and data weighting that dynamically adapts the data sample importance. Experiments show the resulting algorithms significantly improve the image and text classification performance in low data regime and class-imbalance problems.
Harnessing the Power of Infinitely Wide Deep Nets on Small-data Tasks
Oct 27, 2019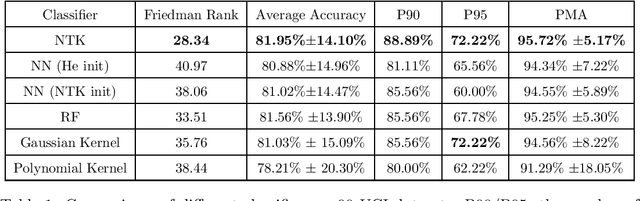
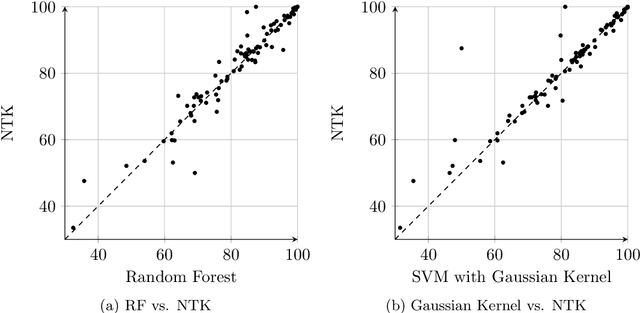
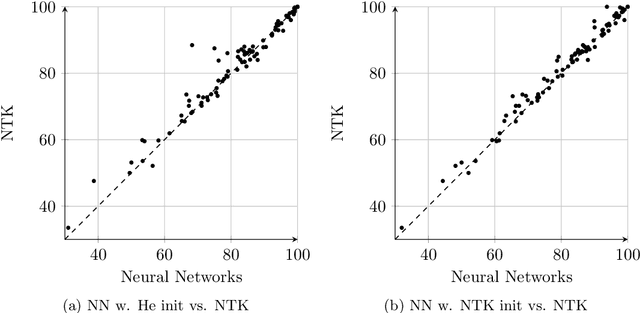
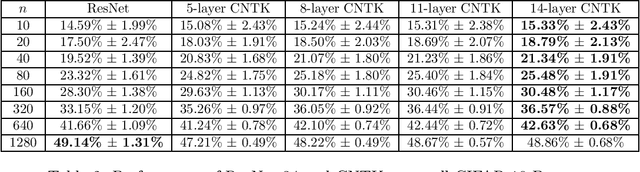
Recent research shows that the following two models are equivalent: (a) infinitely wide neural networks (NNs) trained under l2 loss by gradient descent with infinitesimally small learning rate (b) kernel regression with respect to so-called Neural Tangent Kernels (NTKs) (Jacot et al., 2018). An efficient algorithm to compute the NTK, as well as its convolutional counterparts, appears in Arora et al. (2019a), which allowed studying performance of infinitely wide nets on datasets like CIFAR-10. However, super-quadratic running time of kernel methods makes them best suited for small-data tasks. We report results suggesting neural tangent kernels perform strongly on low-data tasks. 1. On a standard testbed of classification/regression tasks from the UCI database, NTK SVM beats the previous gold standard, Random Forests (RF), and also the corresponding finite nets. 2. On CIFAR-10 with 10 - 640 training samples, Convolutional NTK consistently beats ResNet-34 by 1% - 3%. 3. On VOC07 testbed for few-shot image classification tasks on ImageNet with transfer learning (Goyal et al., 2019), replacing the linear SVM currently used with a Convolutional NTK SVM consistently improves performance. 4. Comparing the performance of NTK with the finite-width net it was derived from, NTK behavior starts at lower net widths than suggested by theoretical analysis(Arora et al., 2019a). NTK's efficacy may trace to lower variance of output.
Complex Transformer: A Framework for Modeling Complex-Valued Sequence
Oct 22, 2019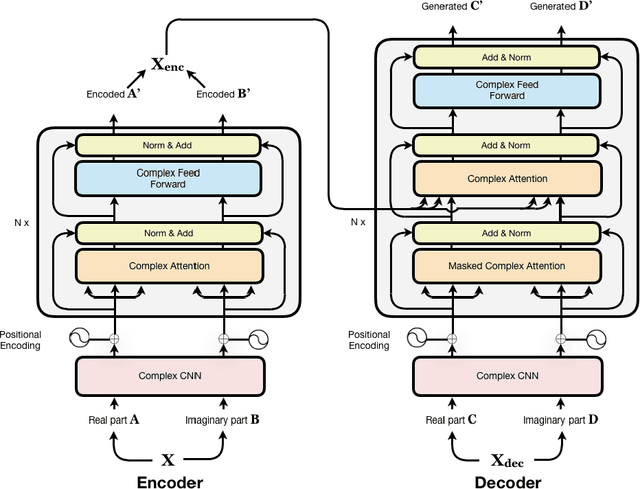
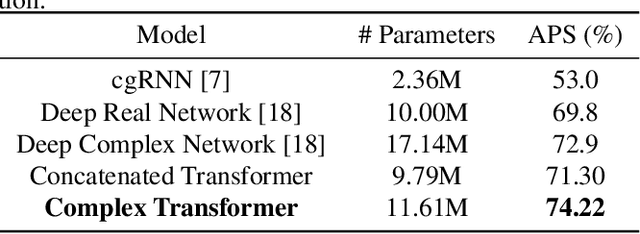
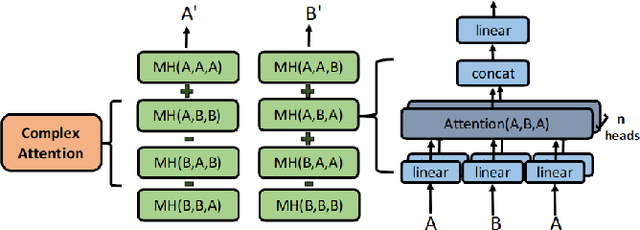

While deep learning has received a surge of interest in a variety of fields in recent years, major deep learning models barely use complex numbers. However, speech, signal and audio data are naturally complex-valued after Fourier Transform, and studies have shown a potentially richer representation of complex nets. In this paper, we propose a Complex Transformer, which incorporates the transformer model as a backbone for sequence modeling; we also develop attention and encoder-decoder network operating for complex input. The model achieves state-of-the-art performance on the MusicNet dataset and an In-phase Quadrature (IQ) signal dataset.
On Universal Approximation by Neural Networks with Uniform Guarantees on Approximation of Infinite Dimensional Maps
Oct 03, 2019The study of universal approximation of arbitrary functions $f: \mathcal{X} \to \mathcal{Y}$ by neural networks has a rich and thorough history dating back to Kolmogorov (1957). In the case of learning finite dimensional maps, many authors have shown various forms of the universality of both fixed depth and fixed width neural networks. However, in many cases, these classical results fail to extend to the recent use of approximations of neural networks with infinitely many units for functional data analysis, dynamical systems identification, and other applications where either $\mathcal{X}$ or $\mathcal{Y}$ become infinite dimensional. Two questions naturally arise: which infinite dimensional analogues of neural networks are sufficient to approximate any map $f: \mathcal{X} \to \mathcal{Y}$, and when do the finite approximations to these analogues used in practice approximate $f$ uniformly over its infinite dimensional domain $\mathcal{X}$? In this paper, we answer the open question of universal approximation of nonlinear operators when $\mathcal{X}$ and $\mathcal{Y}$ are both infinite dimensional. We show that for a large class of different infinite analogues of neural networks, any continuous map can be approximated arbitrarily closely with some mild topological conditions on $\mathcal{X}$. Additionally, we provide the first lower-bound on the minimal number of input and output units required by a finite approximation to an infinite neural network to guarantee that it can uniformly approximate any nonlinear operator using samples from its inputs and outputs.
LSMI-Sinkhorn: Semi-supervised Squared-Loss Mutual Information Estimation with Optimal Transport
Sep 05, 2019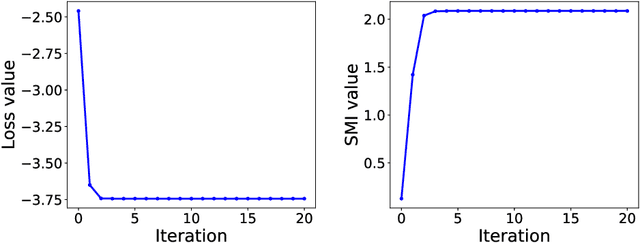
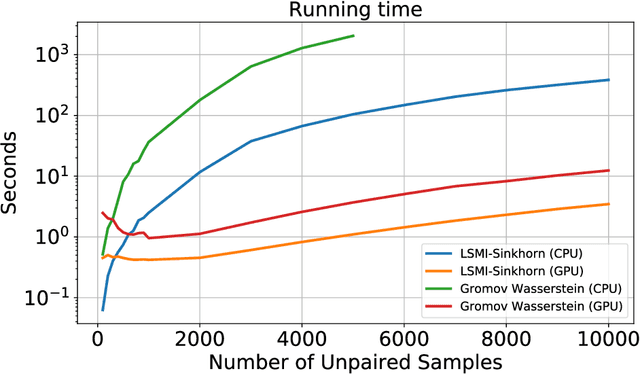
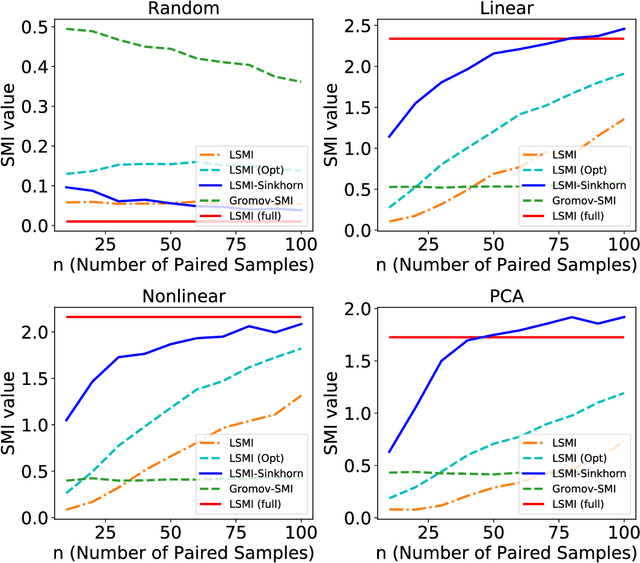
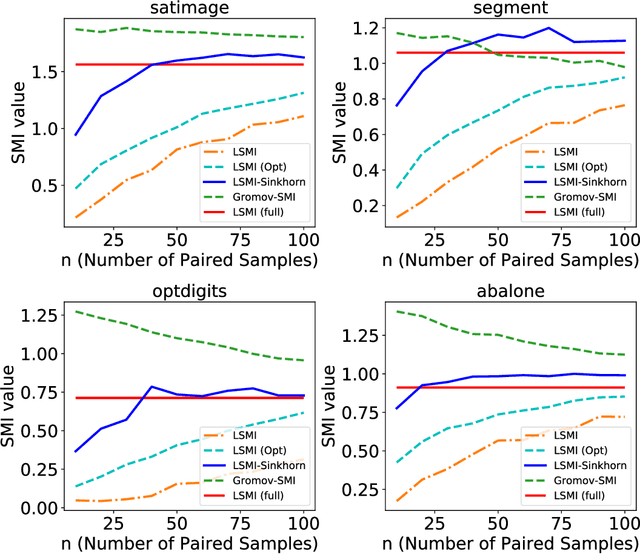
Estimating mutual information is an important machine learning and statistics problem. To estimate the mutual information from data, a common practice is preparing a set of paired samples. However, in some cases, it is difficult to obtain a large number of data pairs. To address this problem, we propose squared-loss mutual information (SMI) estimation using a small number of paired samples and the available unpaired ones. We first represent SMI through the density ratio function, where the expectation is approximated by the samples from marginals and its assignment parameters. The objective is formulated using the optimal transport problem and quadratic programming. Then, we introduce the least-square mutual information-Sinkhorn algorithm (LSMI-Sinkhorn) for efficient optimization. Through experiments, we first demonstrate that the proposed method can estimate the SMI without a large number of paired samples. We also evaluate and show the effectiveness of the proposed LSMI-Sinkhorn on various types of machine learning problems such as image matching and photo album summarization.
Transformer Dissection: An Unified Understanding for Transformer's Attention via the Lens of Kernel
Aug 30, 2019
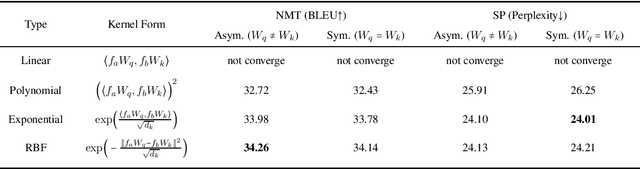

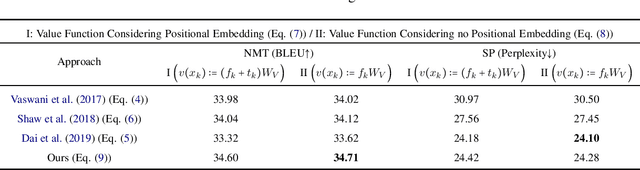
Transformer is a powerful architecture that achieves superior performance on various sequence learning tasks, including neural machine translation, language understanding, and sequence prediction. At the core of the Transformer is the attention mechanism, which concurrently processes all inputs in the streams. In this paper, we present a new formulation of attention via the lens of the kernel. To be more precise, we realize that the attention can be seen as applying kernel smoother over the inputs with the kernel scores being the similarities between inputs. This new formulation gives us a better way to understand individual components of the Transformer's attention, such as the better way to integrate the positional embedding. Another important advantage of our kernel-based formulation is that it paves the way to a larger space of composing Transformer's attention. As an example, we propose a new variant of Transformer's attention which models the input as a product of symmetric kernels. This approach achieves competitive performance to the current state of the art model with less computation. In our experiments, we empirically study different kernel construction strategies on two widely used tasks: neural machine translation and sequence prediction.
MineRL: A Large-Scale Dataset of Minecraft Demonstrations
Jul 29, 2019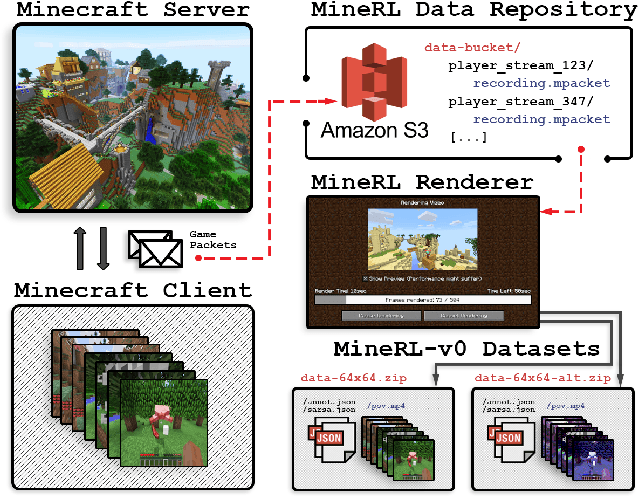
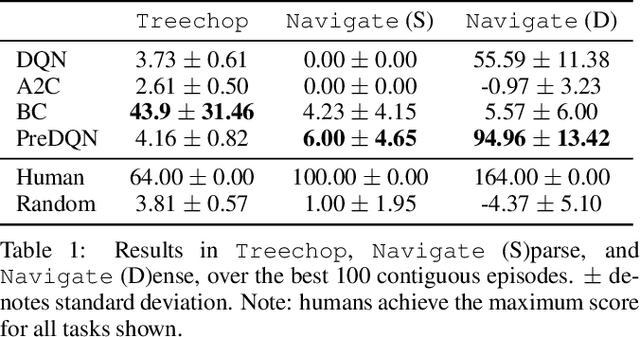
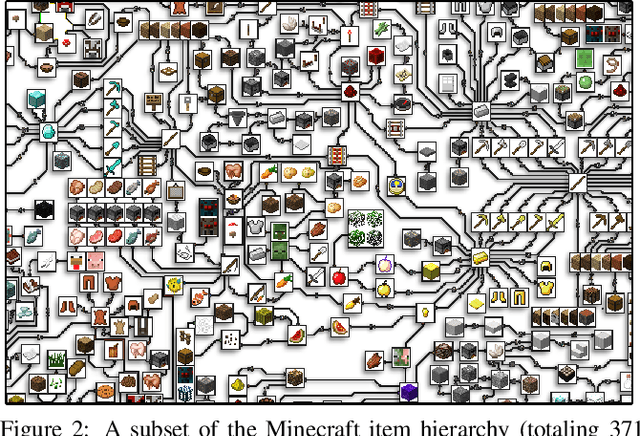

The sample inefficiency of standard deep reinforcement learning methods precludes their application to many real-world problems. Methods which leverage human demonstrations require fewer samples but have been researched less. As demonstrated in the computer vision and natural language processing communities, large-scale datasets have the capacity to facilitate research by serving as an experimental and benchmarking platform for new methods. However, existing datasets compatible with reinforcement learning simulators do not have sufficient scale, structure, and quality to enable the further development and evaluation of methods focused on using human examples. Therefore, we introduce a comprehensive, large-scale, simulator-paired dataset of human demonstrations: MineRL. The dataset consists of over 60 million automatically annotated state-action pairs across a variety of related tasks in Minecraft, a dynamic, 3D, open-world environment. We present a novel data collection scheme which allows for the ongoing introduction of new tasks and the gathering of complete state information suitable for a variety of methods. We demonstrate the hierarchality, diversity, and scale of the MineRL dataset. Further, we show the difficulty of the Minecraft domain along with the potential of MineRL in developing techniques to solve key research challenges within it.
Learning Neural Networks with Adaptive Regularization
Jul 14, 2019



Feed-forward neural networks can be understood as a combination of an intermediate representation and a linear hypothesis. While most previous works aim to diversify the representations, we explore the complementary direction by performing an adaptive and data-dependent regularization motivated by the empirical Bayes method. Specifically, we propose to construct a matrix-variate normal prior (on weights) whose covariance matrix has a Kronecker product structure. This structure is designed to capture the correlations in neurons through backpropagation. Under the assumption of this Kronecker factorization, the prior encourages neurons to borrow statistical strength from one another. Hence, it leads to an adaptive and data-dependent regularization when training networks on small datasets. To optimize the model, we present an efficient block coordinate descent algorithm with analytical solutions. Empirically, we demonstrate that the proposed method helps networks converge to local optima with smaller stable ranks and spectral norms. These properties suggest better generalizations and we present empirical results to support this expectation. We also verify the effectiveness of the approach on multiclass classification and multitask regression problems with various network structures.
Learning Representations from Imperfect Time Series Data via Tensor Rank Regularization
Jul 01, 2019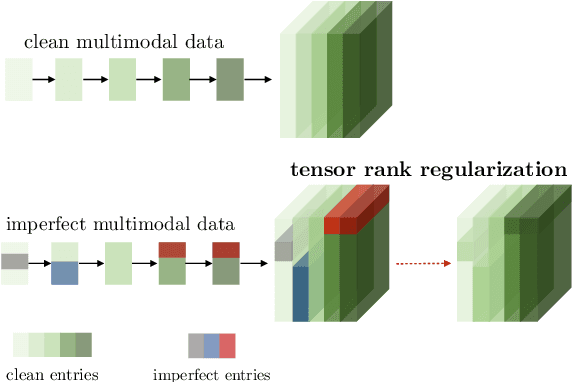
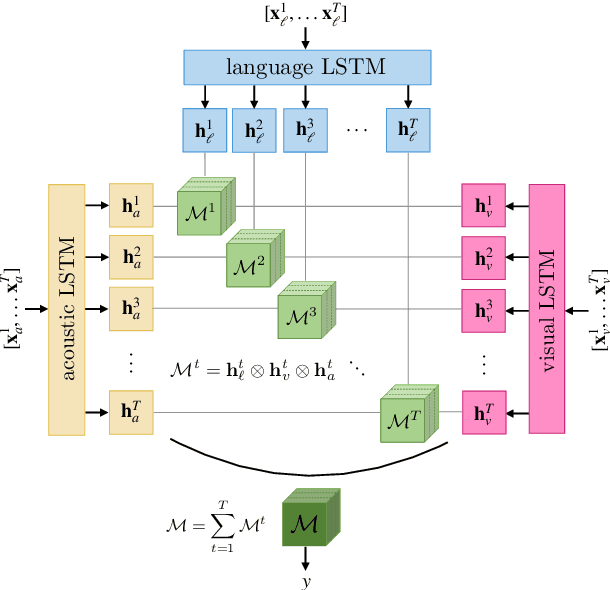
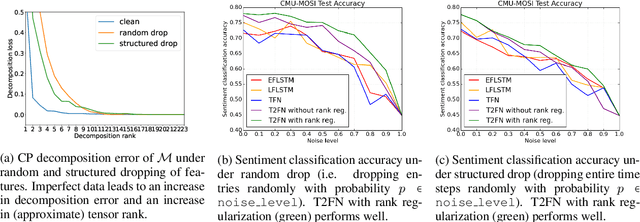
There has been an increased interest in multimodal language processing including multimodal dialog, question answering, sentiment analysis, and speech recognition. However, naturally occurring multimodal data is often imperfect as a result of imperfect modalities, missing entries or noise corruption. To address these concerns, we present a regularization method based on tensor rank minimization. Our method is based on the observation that high-dimensional multimodal time series data often exhibit correlations across time and modalities which leads to low-rank tensor representations. However, the presence of noise or incomplete values breaks these correlations and results in tensor representations of higher rank. We design a model to learn such tensor representations and effectively regularize their rank. Experiments on multimodal language data show that our model achieves good results across various levels of imperfection.
Deep Gamblers: Learning to Abstain with Portfolio Theory
Jun 29, 2019


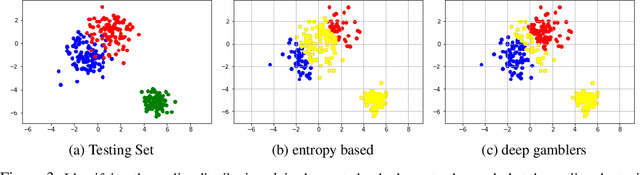
We deal with the \textit{selective classification} problem (supervised-learning problem with a rejection option), where we want to achieve the best performance at a certain level of coverage of the data. We transform the original $m$-class classification problem to $(m+1)$-class where the $(m+1)$-th class represents the model abstaining from making a prediction due to uncertainty. Inspired by portfolio theory, we propose a loss function for the selective classification problem based on the doubling rate of gambling. We show that minimizing this loss function has a natural interpretation as maximizing the return of a \textit{horse race}, where a player aims to balance between betting on an outcome (making a prediction) when confident and reserving one's winnings (abstaining) when not confident. This loss function allows us to train neural networks and characterize the uncertainty of prediction in an end-to-end fashion. In comparison with previous methods, our method requires almost no modification to the model inference algorithm or neural architecture. Experimentally, we show that our method can identify both uncertain and outlier data points, and achieves strong results on SVHN and CIFAR10 at various coverages of the data.