 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Exact Computation with an Infinitely Wide Neural Net
Paper and Code
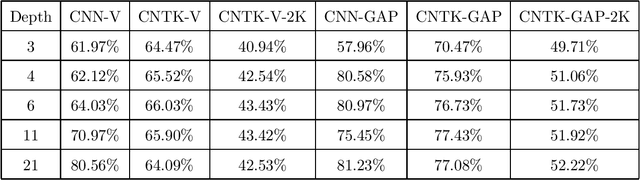
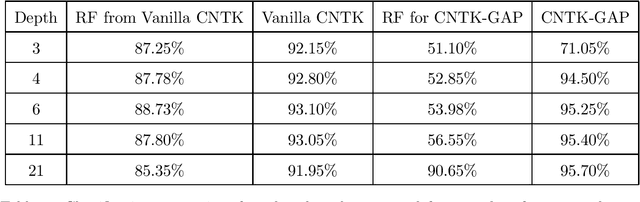
How well does a classic deep net architecture like AlexNet or VGG19 classify on a standard dataset such as CIFAR-10 when its "width" --- namely, number of channels in convolutional layers, and number of nodes in fully-connected internal layers --- is allowed to increase to infinity? Such questions have come to the forefront in the quest to theoretically understand deep learning and its mysteries about optimization and generalization. They also connect deep learning to notions such as Gaussian processes and kernels. A recent paper [Jacot et al., 2018] introduced the Neural Tangent Kernel (NTK) which captures the behavior of fully-connected deep nets in the infinite width limit trained by gradient descent; this object was implicit in some other recent papers. A subsequent paper [Lee et al., 2019] gave heuristic Monte Carlo methods to estimate the NTK and its extension, Convolutional Neural Tangent Kernel (CNTK) and used this to try to understand the limiting behavior on datasets like CIFAR-10. The current paper gives the first efficient exact algorithm (based upon dynamic programming) for computing CNTK as well as an efficient GPU implementation of this algorithm. This results in a significant new benchmark for performance of a pure kernel-based method on CIFAR-10, being 10% higher than the methods reported in [Novak et al., 2019], and only 5% lower than the performance of the corresponding finite deep net architecture (once batch normalization etc. are turned off). We give the first non-asymptotic proof showing that a fully-trained sufficiently wide net is indeed equivalent to the kernel regression predictor using NTK. Our experiments also demonstrate that earlier Monte Carlo approximation can degrade the performance significantly, thus highlighting the power of our exact kernel computation, which we have applied even to the full CIFAR-10 dataset and 20-layer nets.