 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
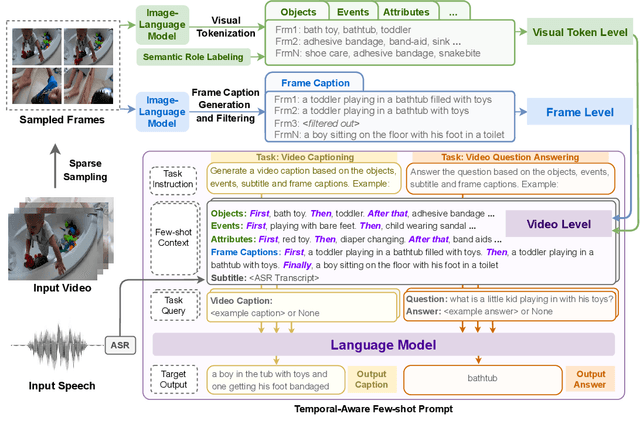
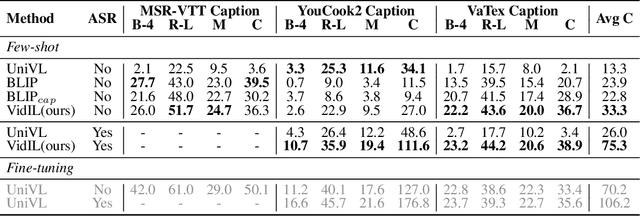

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
Mar 16, 2022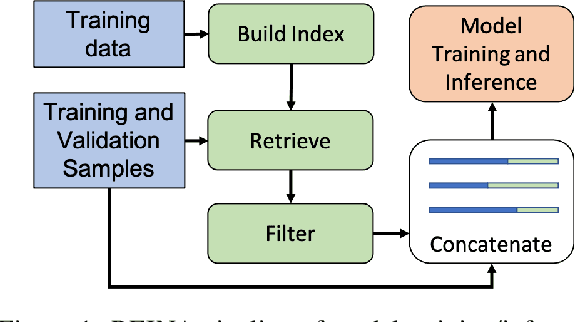
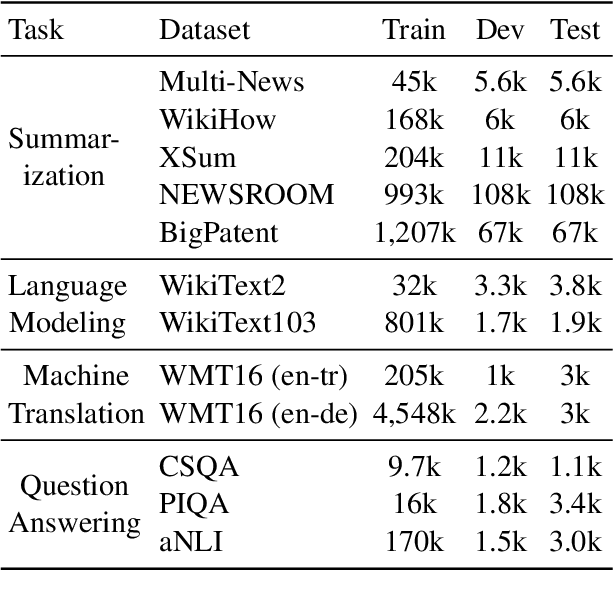
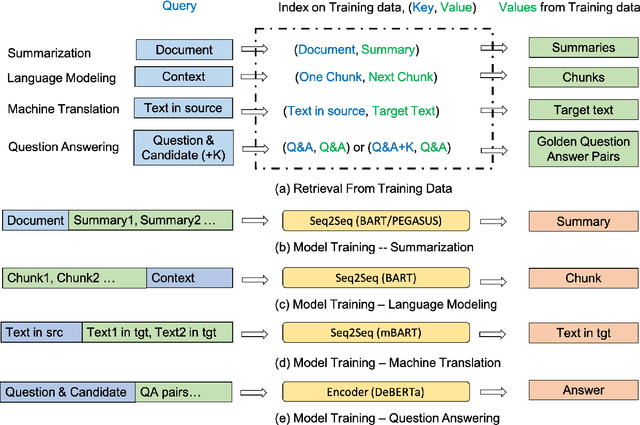
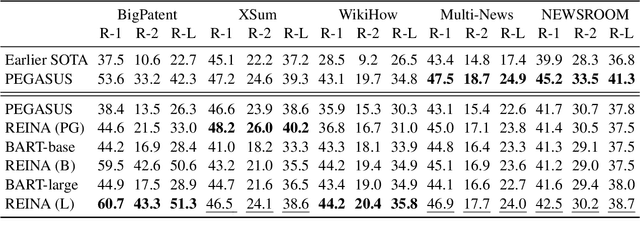
Retrieval-based methods have been shown to be effective in NLP tasks via introducing external knowledge. However, the indexing and retrieving of large-scale corpora bring considerable computational cost. Surprisingly, we found that REtrieving from the traINing datA (REINA) only can lead to significant gains on multiple NLG and NLU tasks. We retrieve the labeled training instances most similar to the input text and then concatenate them with the input to feed into the model to generate the output. Experimental results show that this simple method can achieve significantly better performance on a variety of NLU and NLG tasks, including summarization, machine translation, language modeling, and question answering tasks. For instance, our proposed method achieved state-of-the-art results on XSum, BigPatent, and CommonsenseQA. Our code is released, https://github.com/microsoft/REINA .
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
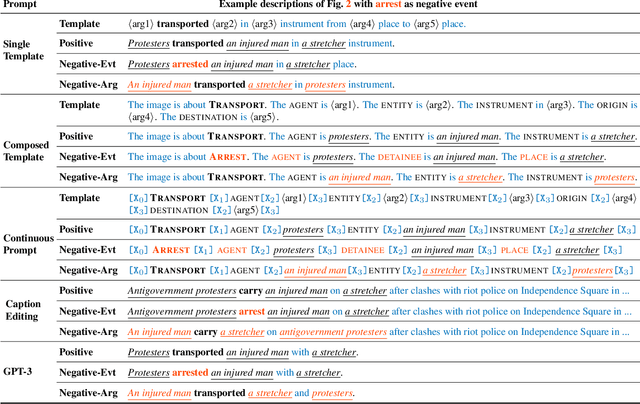
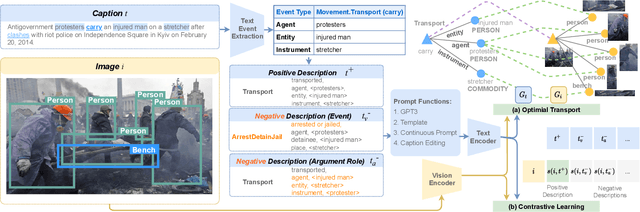

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
Leveraging Knowledge in Multilingual Commonsense Reasoning
Oct 16, 2021

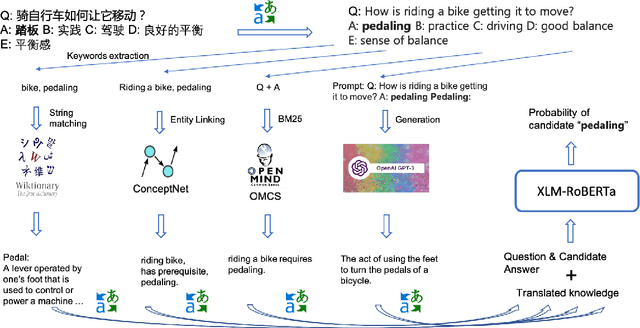
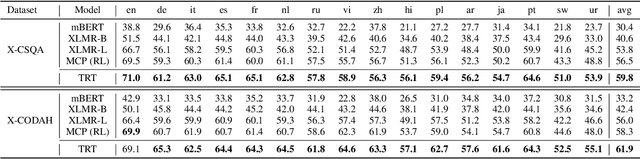
Commonsense reasoning (CSR) requires the model to be equipped with general world knowledge. While CSR is a language-agnostic process, most comprehensive knowledge sources are in few popular languages, especially English. Thus, it remains unclear how to effectively conduct multilingual commonsense reasoning (XCSR) for various languages. In this work, we propose to utilize English knowledge sources via a translate-retrieve-translate (TRT) strategy. For multilingual commonsense questions and choices, we collect related knowledge via translation and retrieval from the knowledge sources. The retrieved knowledge is then translated into the target language and integrated into a pre-trained multilingual language model via visible knowledge attention. Then we utilize a diverse of 4 English knowledge sources to provide more comprehensive coverage of knowledge in different formats. Extensive results on the XCSR benchmark demonstrate that TRT with external knowledge can significantly improve multilingual commonsense reasoning in both zero-shot and translate-train settings, outperforming 3.3 and 3.6 points over the previous state-of-the-art on XCSR benchmark datasets (X-CSQA and X-CODAH).
Does Knowledge Help General NLU? An Empirical Study
Sep 01, 2021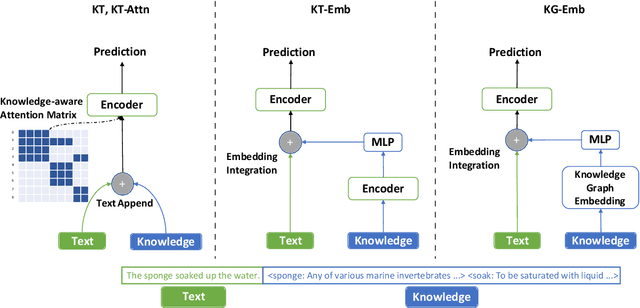

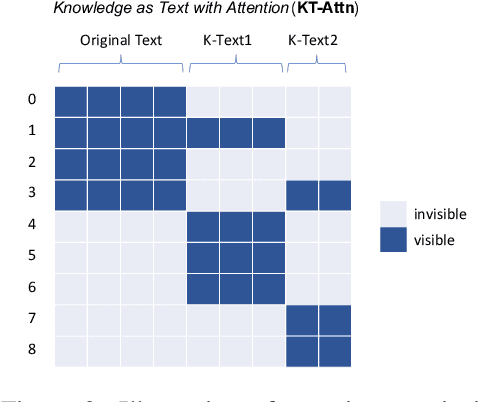
It is often observed in knowledge-centric tasks (e.g., common sense question and answering, relation classification) that the integration of external knowledge such as entity representation into language models can help provide useful information to boost the performance. However, it is still unclear whether this benefit can extend to general natural language understanding (NLU) tasks. In this work, we empirically investigated the contribution of external knowledge by measuring the end-to-end performance of language models with various knowledge integration methods. We find that the introduction of knowledge can significantly improve the results on certain tasks while having no adverse effects on other tasks. We then employ mutual information to reflect the difference brought by knowledge and a neural interpretation model to reveal how a language model utilizes external knowledge. Our study provides valuable insights and guidance for practitioners to equip NLP models with knowledge.
Fusing Context Into Knowledge Graph for Commonsense Reasoning
Dec 09, 2020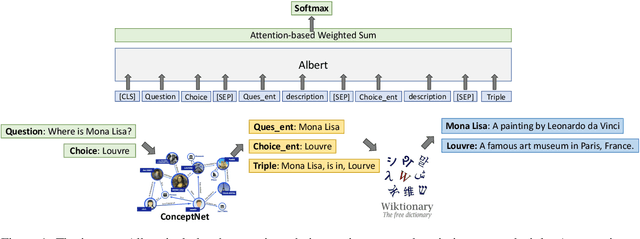

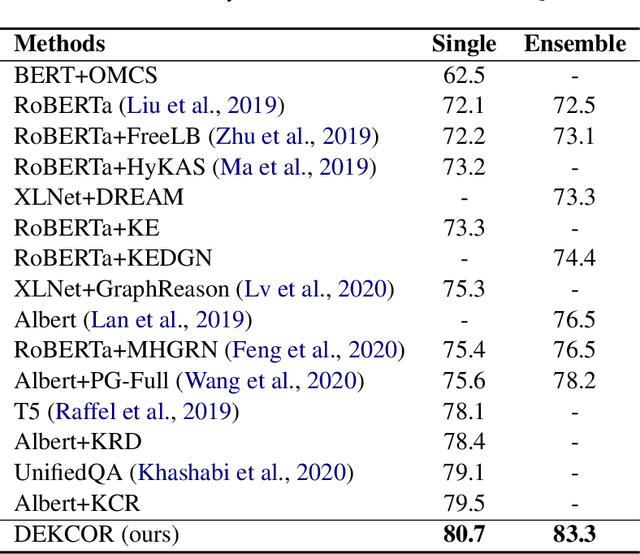

Commonsense reasoning requires a model to make presumptions about world events via language understanding. Many methods couple pre-trained language models with knowledge graphs in order to combine the merits in language modeling and entity-based relational learning. However, although a knowledge graph contains rich structural information, it lacks the context to provide a more precise understanding of the concepts and relations. This creates a gap when fusing knowledge graphs into language modeling, especially in the scenario of insufficient paired text-knowledge data. In this paper, we propose to utilize external entity description to provide contextual information for graph entities. For the CommonsenseQA task, our model first extracts concepts from the question and choice, and then finds a related triple between these concepts. Next, it retrieves the descriptions of these concepts from Wiktionary and feed them as additional input to a pre-trained language model, together with the triple. The resulting model can attain much more effective commonsense reasoning capability, achieving state-of-the-art results in the CommonsenseQA dataset with an accuracy of 80.7% (single model) and 83.3% (ensemble model) on the official leaderboard.
Mixed-Lingual Pre-training for Cross-lingual Summarization
Oct 18, 2020
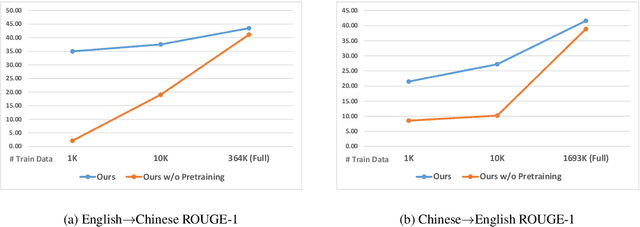
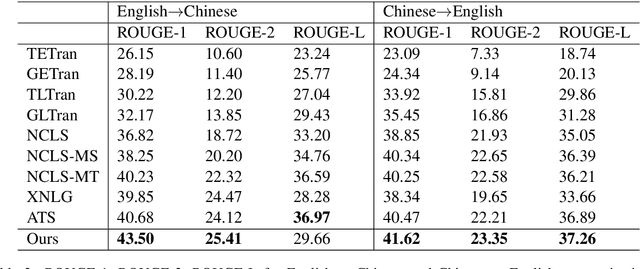
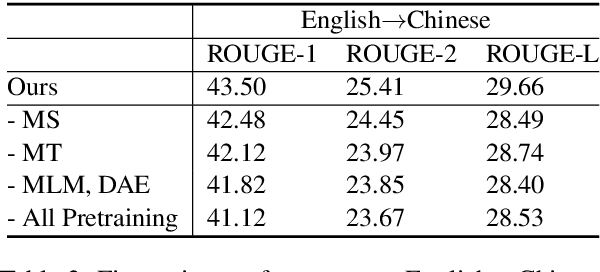
Cross-lingual Summarization (CLS) aims at producing a summary in the target language for an article in the source language. Traditional solutions employ a two-step approach, i.e. translate then summarize or summarize then translate. Recently, end-to-end models have achieved better results, but these approaches are mostly limited by their dependence on large-scale labeled data. We propose a solution based on mixed-lingual pre-training that leverages both cross-lingual tasks such as translation and monolingual tasks like masked language models. Thus, our model can leverage the massive monolingual data to enhance its modeling of language. Moreover, the architecture has no task-specific components, which saves memory and increases optimization efficiency. We show in experiments that this pre-training scheme can effectively boost the performance of cross-lingual summarization. In Neural Cross-Lingual Summarization (NCLS) dataset, our model achieves an improvement of 2.82 (English to Chinese) and 1.15 (Chinese to English) ROUGE-1 scores over state-of-the-art results.
Predicting Performance for Natural Language Processing Tasks
May 02, 2020
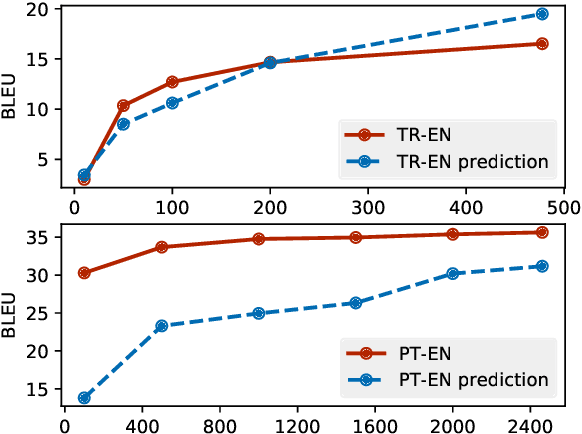
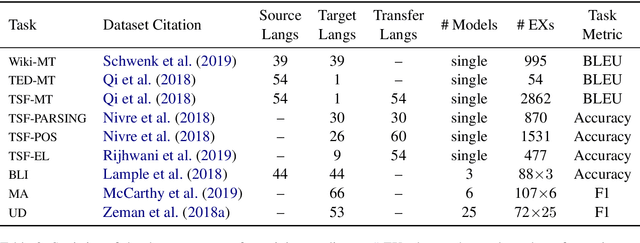
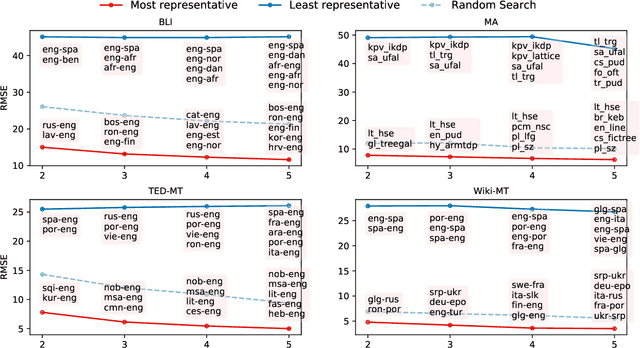
Given the complexity of combinations of tasks, languages, and domains in natural language processing (NLP) research, it is computationally prohibitive to exhaustively test newly proposed models on each possible experimental setting. In this work, we attempt to explore the possibility of gaining plausible judgments of how well an NLP model can perform under an experimental setting, without actually training or testing the model. To do so, we build regression models to predict the evaluation score of an NLP experiment given the experimental settings as input. Experimenting on 9 different NLP tasks, we find that our predictors can produce meaningful predictions over unseen languages and different modeling architectures, outperforming reasonable baselines as well as human experts. Going further, we outline how our predictor can be used to find a small subset of representative experiments that should be run in order to obtain plausible predictions for all other experimental settings.
End-to-End Abstractive Summarization for Meetings
Apr 22, 2020
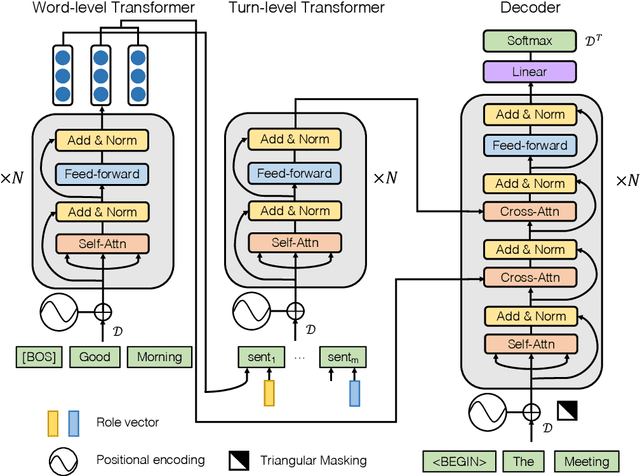
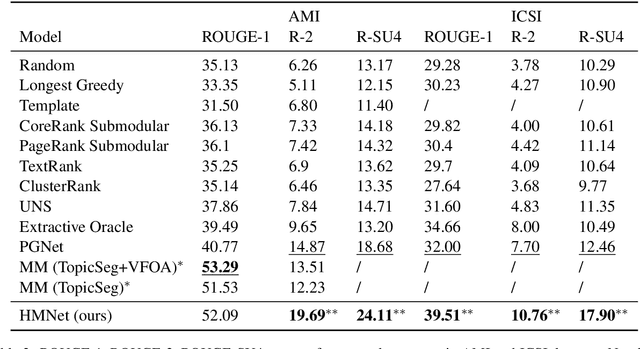
With the abundance of automatic meeting transcripts, meeting summarization is of great interest to both participants and other parties. Traditional methods of summarizing meetings depend on complex multi-step pipelines that make joint optimization intractable. Meanwhile, there are a handful of deep neural models for text summarization and dialogue systems. However, the semantic structure and styles of meeting transcripts are quite different from articles and conversations. In this paper, we propose a novel end-to-end abstractive summary network that adapts to the meeting scenario. We design a role vector to depict the difference among speakers and a hierarchical structure to accommodate long meeting transcripts. Empirical results show that our model considerably outperforms previous approaches in both automatic metrics and human evaluation. For example, in the ICSI dataset, the ROUGE-1 score increases from 32.00% to 39.51%.
Boosting Factual Correctness of Abstractive Summarization
Apr 04, 2020
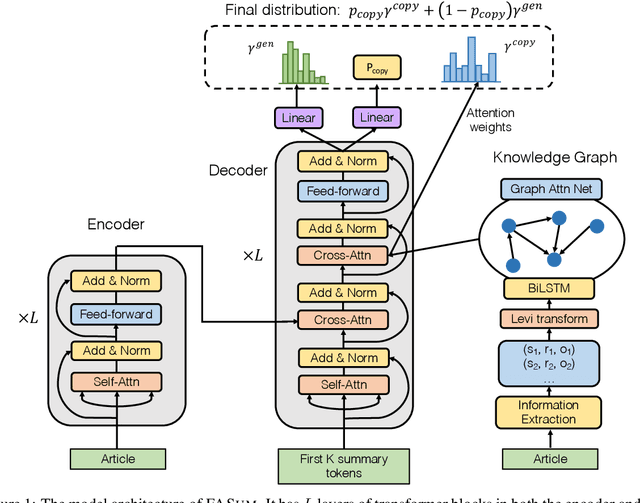
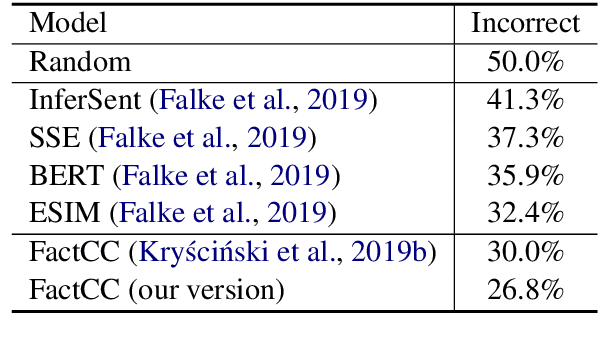
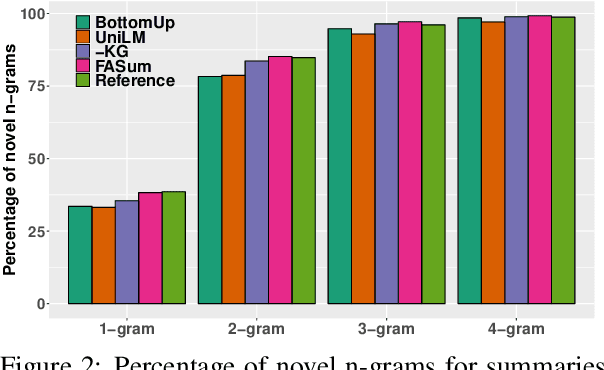
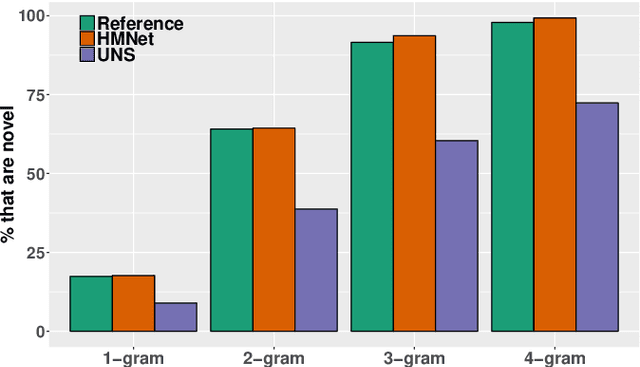
A commonly observed problem with abstractive summarization is the distortion or fabrication of factual information in the article. This inconsistency between summary and original text has led to various concerns over its applicability. In this paper, we firstly propose a Fact-Aware Summarization model, FASum, which extracts factual relations from the article and integrates this knowledge into the decoding process via neural graph computation. Then, we propose a Factual Corrector model, FC, that can modify abstractive summaries generated by any model to improve factual correctness. Empirical results show that FASum generates summaries with significantly higher factual correctness compared with state-of-the-art abstractive summarization systems, both under an independently trained factual correctness evaluator and human evaluation. And FC improves the factual correctness of summaries generated by various models via only modifying several entity tokens.