 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Factual Correctness of Abstractive Summarization
Apr 04, 2020
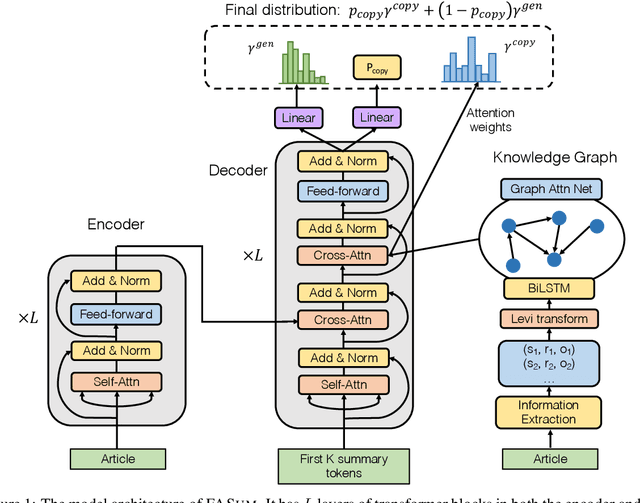
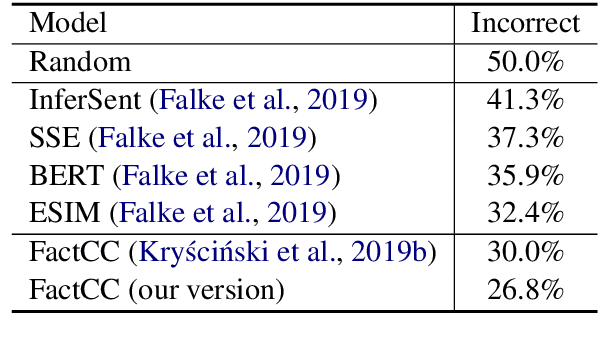
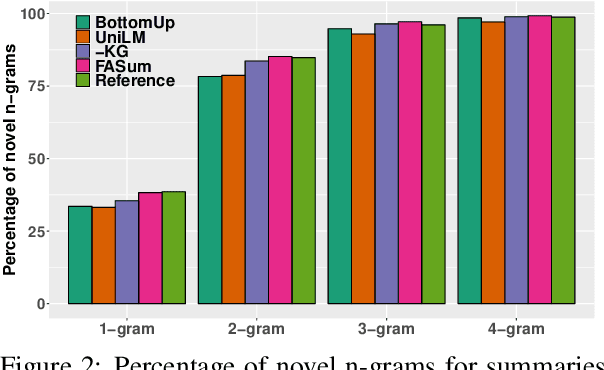
A commonly observed problem with abstractive summarization is the distortion or fabrication of factual information in the article. This inconsistency between summary and original text has led to various concerns over its applicability. In this paper, we firstly propose a Fact-Aware Summarization model, FASum, which extracts factual relations from the article and integrates this knowledge into the decoding process via neural graph computation. Then, we propose a Factual Corrector model, FC, that can modify abstractive summaries generated by any model to improve factual correctness. Empirical results show that FASum generates summaries with significantly higher factual correctness compared with state-of-the-art abstractive summarization systems, both under an independently trained factual correctness evaluator and human evaluation. And FC improves the factual correctness of summaries generated by various models via only modifying several entity tokens.
Combining Acoustics, Content and Interaction Features to Find Hot Spots in Meetings
Oct 24, 2019
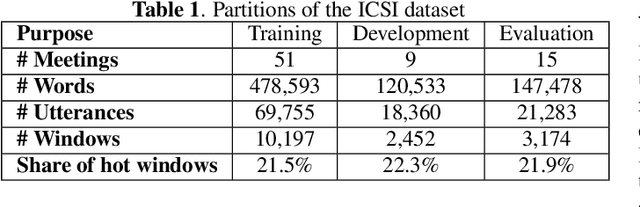
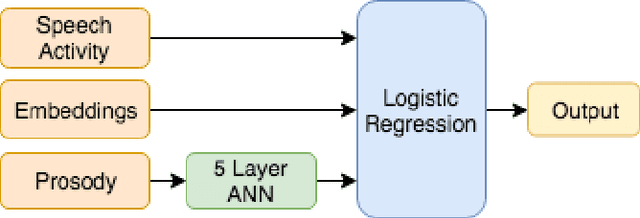
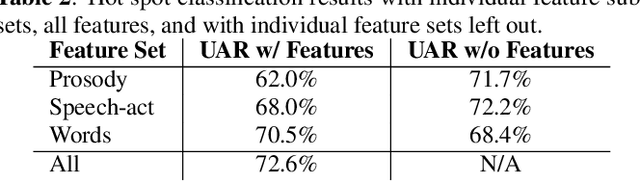
Involvement hot spots have been proposed as a useful concept for meeting analysis and studied off and on for over 15 years. These are regions of meetings that are marked by high participant involvement, as judged by human annotators. However, prior work was either not conducted in a formal machine learning setting, or focused on only a subset of possible meeting features or downstream applications (such as summarization). In this paper we investigate to what extent various acoustic, linguistic and pragmatic aspects of the meetings can help detect hot spots, both in isolation and jointly. In this context, the openSMILE toolkit \cite{opensmile} is to used to extract features based on acoustic-prosodic cues, BERT word embeddings \cite{BERT} are used for modeling the lexical content, and a variety of statistics based on the speech activity are used to describe the verbal interaction among participants. In experiments on the annotated ICSI meeting corpus, we find that the lexical modeling part is the most informative, with incremental contributions from interaction and acoustic-prosodic model components.
Meeting Transcription Using Virtual Microphone Arrays
May 03, 2019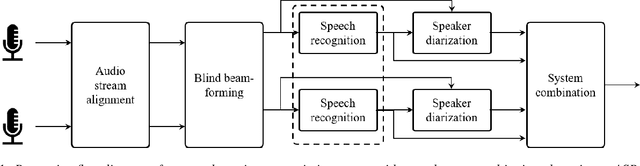
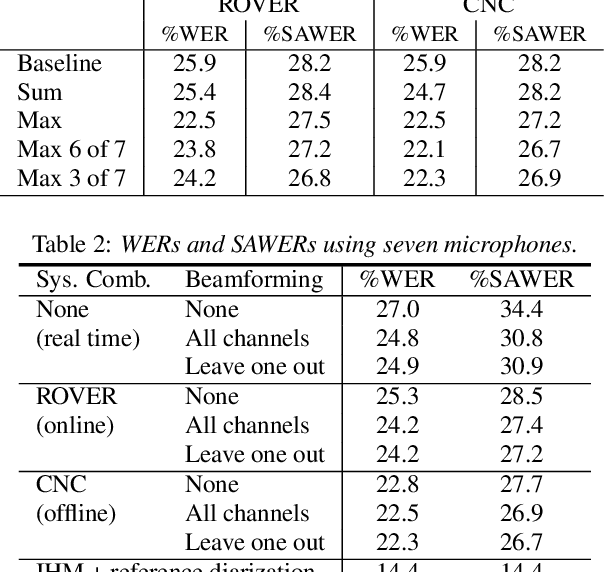
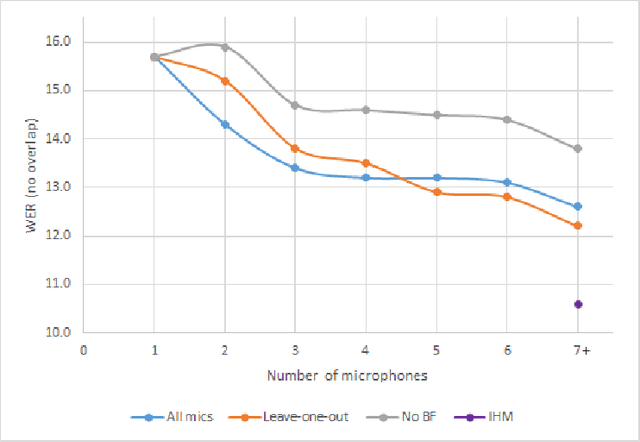

We describe a system that generates speaker-annotated transcripts of meetings by using a virtual microphone array, a set of spatially distributed asynchronous recording devices such as laptops and mobile phones. The system is composed of continuous audio stream alignment, blind beamforming, speech recognition, speaker diarization using prior speaker information, and system combination. With seven input audio streams, our system achieves a word error rate (WER) of 22.3% and comes within 3% of the close-talking microphone WER on the non-overlapping speech segments. The speaker-attributed WER (SAWER) is 26.7%. The relative gains in SAWER over a single-device system are 14.8%, 20.3%, and 22.4% for three, five, and seven microphones, respectively. The presented system achieves a 13.6% diarization error rate when 10% of the speech duration contains more than one speaker. The contribution of each component to the overall performance is also investigated.