 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025



This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
The 1st Solution for 4th PVUW MeViS Challenge: Unleashing the Potential of Large Multimodal Models for Referring Video Segmentation
Apr 07, 2025



Motion expression video segmentation is designed to segment objects in accordance with the input motion expressions. In contrast to the conventional Referring Video Object Segmentation (RVOS), it places emphasis on motion as well as multi-object expressions, making it more arduous. Recently, Large Multimodal Models (LMMs) have begun to shine in RVOS due to their powerful vision-language perception capabilities. In this work, we propose a simple and effective inference optimization method to fully unleash the potential of LMMs in referring video segmentation. Firstly, we use Sa2VA as our baseline, which is a unified LMM for dense grounded understanding of both images and videos. Secondly, we uniformly sample the video frames during the inference process to enhance the model's understanding of the entire video. Finally, we integrate the results of multiple expert models to mitigate the erroneous predictions of a single model. Our solution achieved 61.98% J&F on the MeViS test set and ranked 1st place in the 4th PVUW Challenge MeViS Track at CVPR 2025.
Unleashing Correlation and Continuity for Hyperspectral Reconstruction from RGB Images
Jan 02, 2025



Reconstructing Hyperspectral Images (HSI) from RGB images can yield high spatial resolution HSI at a lower cost, demonstrating significant application potential. This paper reveals that local correlation and global continuity of the spectral characteristics are crucial for HSI reconstruction tasks. Therefore, we fully explore these inter-spectral relationships and propose a Correlation and Continuity Network (CCNet) for HSI reconstruction from RGB images. For the correlation of local spectrum, we introduce the Group-wise Spectral Correlation Modeling (GrSCM) module, which efficiently establishes spectral band similarity within a localized range. For the continuity of global spectrum, we design the Neighborhood-wise Spectral Continuity Modeling (NeSCM) module, which employs memory units to recursively model the progressive variation characteristics at the global level. In order to explore the inherent complementarity of these two modules, we design the Patch-wise Adaptive Fusion (PAF) module to efficiently integrate global continuity features into the spectral features in a patch-wise adaptive manner. These innovations enhance the quality of reconstructed HSI. We perform comprehensive comparison and ablation experiments on the mainstream datasets NTIRE2022 and NTIRE2020 for the spectral reconstruction task. Compared to the current advanced spectral reconstruction algorithms, our designed algorithm achieves State-Of-The-Art (SOTA) performance.
LSVOS Challenge Report: Large-scale Complex and Long Video Object Segmentation
Sep 09, 2024



Despite the promising performance of current video segmentation models on existing benchmarks, these models still struggle with complex scenes. In this paper, we introduce the 6th Large-scale Video Object Segmentation (LSVOS) challenge in conjunction with ECCV 2024 workshop. This year's challenge includes two tasks: Video Object Segmentation (VOS) and Referring Video Object Segmentation (RVOS). In this year, we replace the classic YouTube-VOS and YouTube-RVOS benchmark with latest datasets MOSE, LVOS, and MeViS to assess VOS under more challenging complex environments. This year's challenge attracted 129 registered teams from more than 20 institutes across over 8 countries. This report include the challenge and dataset introduction, and the methods used by top 7 teams in two tracks. More details can be found in our homepage https://lsvos.github.io/.
Video Object Segmentation via SAM 2: The 4th Solution for LSVOS Challenge VOS Track
Aug 19, 2024Video Object Segmentation (VOS) task aims to segmenting a particular object instance throughout the entire video sequence given only the object mask of the first frame. Recently, Segment Anything Model 2 (SAM 2) is proposed, which is a foundation model towards solving promptable visual segmentation in images and videos. SAM 2 builds a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. SAM 2 is a simple transformer architecture with streaming memory for real-time video processing, which trained on the date provides strong performance across a wide range of tasks. In this work, we evaluate the zero-shot performance of SAM 2 on the more challenging VOS datasets MOSE and LVOS. Without fine-tuning on the training set, SAM 2 achieved 75.79 J&F on the test set and ranked 4th place for 6th LSVOS Challenge VOS Track.
UNINEXT-Cutie: The 1st Solution for LSVOS Challenge RVOS Track
Aug 19, 2024Referring video object segmentation (RVOS) relies on natural language expressions to segment target objects in video. In this year, LSVOS Challenge RVOS Track replaced the origin YouTube-RVOS benchmark with MeViS. MeViS focuses on referring the target object in a video through its motion descriptions instead of static attributes, posing a greater challenge to RVOS task. In this work, we integrate strengths of that leading RVOS and VOS models to build up a simple and effective pipeline for RVOS. Firstly, We finetune the state-of-the-art RVOS model to obtain mask sequences that are correlated with language descriptions. Secondly, based on a reliable and high-quality key frames, we leverage VOS model to enhance the quality and temporal consistency of the mask results. Finally, we further improve the performance of the RVOS model using semi-supervised learning. Our solution achieved 62.57 J&F on the MeViS test set and ranked 1st place for 6th LSVOS Challenge RVOS Track.
Strike a Balance in Continual Panoptic Segmentation
Jul 23, 2024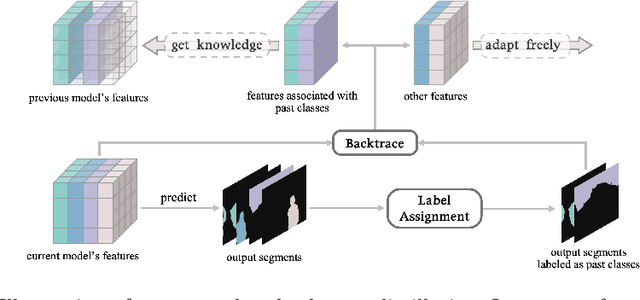
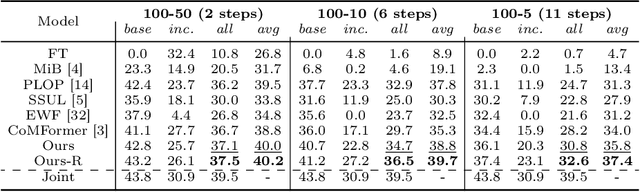
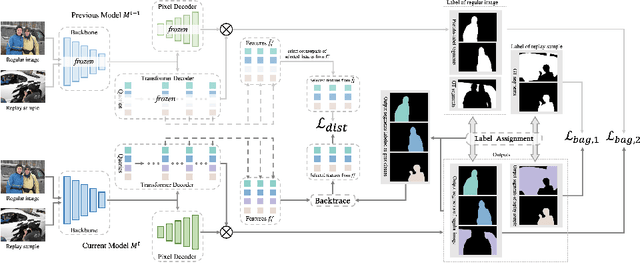
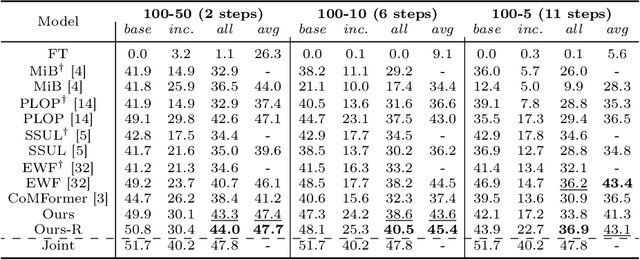
This study explores the emerging area of continual panoptic segmentation, highlighting three key balances. First, we introduce past-class backtrace distillation to balance the stability of existing knowledge with the adaptability to new information. This technique retraces the features associated with past classes based on the final label assignment results, performing knowledge distillation targeting these specific features from the previous model while allowing other features to flexibly adapt to new information. Additionally, we introduce a class-proportional memory strategy, which aligns the class distribution in the replay sample set with that of the historical training data. This strategy maintains a balanced class representation during replay, enhancing the utility of the limited-capacity replay sample set in recalling prior classes. Moreover, recognizing that replay samples are annotated only for the classes of their original step, we devise balanced anti-misguidance losses, which combat the impact of incomplete annotations without incurring classification bias. Building upon these innovations, we present a new method named Balanced Continual Panoptic Segmentation (BalConpas). Our evaluation on the challenging ADE20K dataset demonstrates its superior performance compared to existing state-of-the-art methods. The official code is available at https://github.com/jinpeng0528/BalConpas.
Diving into Underwater: Segment Anything Model Guided Underwater Salient Instance Segmentation and A Large-scale Dataset
Jun 10, 2024With the breakthrough of large models, Segment Anything Model (SAM) and its extensions have been attempted to apply in diverse tasks of computer vision. Underwater salient instance segmentation is a foundational and vital step for various underwater vision tasks, which often suffer from low segmentation accuracy due to the complex underwater circumstances and the adaptive ability of models. Moreover, the lack of large-scale datasets with pixel-level salient instance annotations has impeded the development of machine learning techniques in this field. To address these issues, we construct the first large-scale underwater salient instance segmentation dataset (USIS10K), which contains 10,632 underwater images with pixel-level annotations in 7 categories from various underwater scenes. Then, we propose an Underwater Salient Instance Segmentation architecture based on Segment Anything Model (USIS-SAM) specifically for the underwater domain. We devise an Underwater Adaptive Visual Transformer (UA-ViT) encoder to incorporate underwater domain visual prompts into the segmentation network. We further design an out-of-the-box underwater Salient Feature Prompter Generator (SFPG) to automatically generate salient prompters instead of explicitly providing foreground points or boxes as prompts in SAM. Comprehensive experimental results show that our USIS-SAM method can achieve superior performance on USIS10K datasets compared to the state-of-the-art methods. Datasets and codes are released on https://github.com/LiamLian0727/USIS10K.
Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
Jun 02, 2024



Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.