 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimestep Rescheduling in Diffusion Inversion
Jun 13, 2026Diffusion inversion, which maps images back to the Gaussian latent space of a diffusion model, is a critical task for image reconstruction and editing. While DDIM enables fast deterministic inversion, it inherently introduces deviations that accumulate into noticeable inversion errors. Existing methods often address this by solving a fixed-point problem but largely overlook how the selection of the diffusion timestep in the noise scheduler influences inversion fidelity. In this work, we reveal that the deviation scale in diffusion inversion is strongly dependent on the timestep size, and exhibits a parabolic trend, with larger errors concentrated at both small and large timesteps. Based on this finding, we propose a simple yet effective nonuniform timestep scheduler that integrates a global rescaling with a local dynamic programming based rescheduling, enabling a strategic allocation of computational effort that minimizes the overall inversion error and preserves higher inversion accuracy. Our method serves as an off-the-shelf enhancement for existing inversion techniques and requires no extra parameters or computational overhead. Through extensive experiments, we verify that integrating our scheduler consistently boosts the performance of existing inversion methods, achieving superior results in image reconstruction and editing.
NeuroSeg Meets DINOv3: Transferring 2D Self-Supervised Visual Priors to 3D Neuron Segmentation via DINOv3 Initialization
Mar 24, 20262D visual foundation models, such as DINOv3, a self-supervised model trained on large-scale natural images, have demonstrated strong zero-shot generalization, capturing both rich global context and fine-grained structural cues. However, an analogous 3D foundation model for downstream volumetric neuroimaging remains lacking, largely due to the challenges of 3D image acquisition and the scarcity of high-quality annotations. To address this gap, we propose to adapt the 2D visual representations learned by DINOv3 to a 3D biomedical segmentation model, enabling more data-efficient and morphologically faithful neuronal reconstruction. Specifically, we design an inflation-based adaptation strategy that inflates 2D filters into 3D operators, preserving semantic priors from DINOv3 while adapting to 3D neuronal volume patches. In addition, we introduce a topology-aware skeleton loss to explicitly enforce structural fidelity of graph-based neuronal arbor reconstruction. Extensive experiments on four neuronal imaging datasets, including two from BigNeuron and two public datasets, NeuroFly and CWMBS, demonstrate consistent improvements in reconstruction accuracy over SoTA methods, with average gains of 2.9% in Entire Structure Average, 2.8% in Different Structure Average, and 3.8% in Percentage of Different Structure. Code: https://github.com/yy0007/NeurINO.
VirPro: Visual-referred Probabilistic Prompt Learning for Weakly-Supervised Monocular 3D Detection
Mar 18, 2026Monocular 3D object detection typically relies on pseudo-labeling techniques to reduce dependency on real-world annotations. Recent advances demonstrate that deterministic linguistic cues can serve as effective auxiliary weak supervision signals, providing complementary semantic context. However, hand-crafted textual descriptions struggle to capture the inherent visual diversity of individuals across scenes, limiting the model's ability to learn scene-aware representations. To address this challenge, we propose Visual-referred Probabilistic Prompt Learning (VirPro), an adaptive multi-modal pretraining paradigm that can be seamlessly integrated into diverse weakly supervised monocular 3D detection frameworks. Specifically, we generate a diverse set of learnable, instance-conditioned prompts across scenes and store them in an Adaptive Prompt Bank (APB). Subsequently, we introduce Multi-Gaussian Prompt Modeling (MGPM), which incorporates scene-based visual features into the corresponding textual embeddings, allowing the text prompts to express visual uncertainties. Then, from the fused vision-language embeddings, we decode a prompt-targeted Gaussian, from which we derive a unified object-level prompt embedding for each instance. RoI-level contrastive matching is employed to enforce modality alignment, bringing embeddings of co-occurring objects within the same scene closer in the latent space, thus enhancing semantic coherence. Extensive experiments on the KITTI benchmark demonstrate that integrating our pretraining paradigm consistently yields substantial performance gains, achieving up to a 4.8% average precision improvement than the baseline.
BrainVista: Modeling Naturalistic Brain Dynamics as Multimodal Next-Token Prediction
Feb 04, 2026Naturalistic fMRI characterizes the brain as a dynamic predictive engine driven by continuous sensory streams. However, modeling the causal forward evolution in realistic neural simulation is impeded by the timescale mismatch between multimodal inputs and the complex topology of cortical networks. To address these challenges, we introduce BrainVista, a multimodal autoregressive framework designed to model the causal evolution of brain states. BrainVista incorporates Network-wise Tokenizers to disentangle system-specific dynamics and a Spatial Mixer Head that captures inter-network information flow without compromising functional boundaries. Furthermore, we propose a novel Stimulus-to-Brain (S2B) masking mechanism to synchronize high-frequency sensory stimuli with hemodynamically filtered signals, enabling strict, history-only causal conditioning. We validate our framework on Algonauts 2025, CineBrain, and HAD, achieving state-of-the-art fMRI encoding performance. In long-horizon rollout settings, our model yields substantial improvements over baselines, increasing pattern correlation by 36.0\% and 33.3\% on relative to the strongest baseline Algonauts 2025 and CineBrain, respectively.
Improving Multimodal Brain Encoding Model with Dynamic Subject-awareness Routing
Oct 06, 2025Naturalistic fMRI encoding must handle multimodal inputs, shifting fusion styles, and pronounced inter-subject variability. We introduce AFIRE (Agnostic Framework for Multimodal fMRI Response Encoding), an agnostic interface that standardizes time-aligned post-fusion tokens from varied encoders, and MIND, a plug-and-play Mixture-of-Experts decoder with a subject-aware dynamic gating. Trained end-to-end for whole-brain prediction, AFIRE decouples the decoder from upstream fusion, while MIND combines token-dependent Top-K sparse routing with a subject prior to personalize expert usage without sacrificing generality. Experiments across multiple multimodal backbones and subjects show consistent improvements over strong baselines, enhanced cross-subject generalization, and interpretable expert patterns that correlate with content type. The framework offers a simple attachment point for new encoders and datasets, enabling robust, plug-and-improve performance for naturalistic neuroimaging studies.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
DistillDrive: End-to-End Multi-Mode Autonomous Driving Distillation by Isomorphic Hetero-Source Planning Model
Aug 07, 2025End-to-end autonomous driving has been recently seen rapid development, exerting a profound influence on both industry and academia. However, the existing work places excessive focus on ego-vehicle status as their sole learning objectives and lacks of planning-oriented understanding, which limits the robustness of the overall decision-making prcocess. In this work, we introduce DistillDrive, an end-to-end knowledge distillation-based autonomous driving model that leverages diversified instance imitation to enhance multi-mode motion feature learning. Specifically, we employ a planning model based on structured scene representations as the teacher model, leveraging its diversified planning instances as multi-objective learning targets for the end-to-end model. Moreover, we incorporate reinforcement learning to enhance the optimization of state-to-decision mappings, while utilizing generative modeling to construct planning-oriented instances, fostering intricate interactions within the latent space. We validate our model on the nuScenes and NAVSIM datasets, achieving a 50\% reduction in collision rate and a 3-point improvement in closed-loop performance compared to the baseline model. Code and model are publicly available at https://github.com/YuruiAI/DistillDrive
Stealthy Patch-Wise Backdoor Attack in 3D Point Cloud via Curvature Awareness
Mar 12, 2025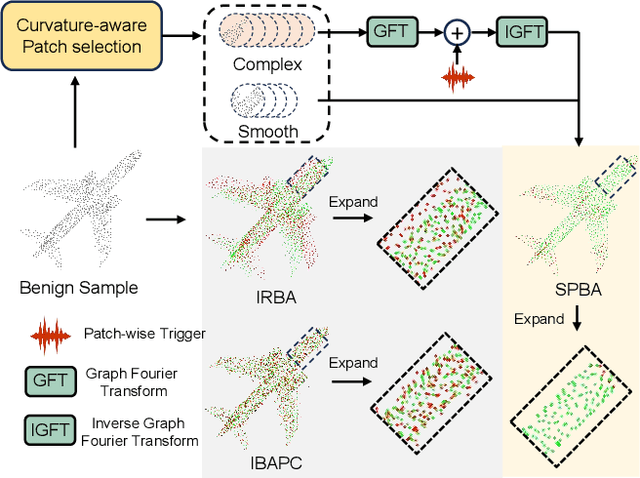
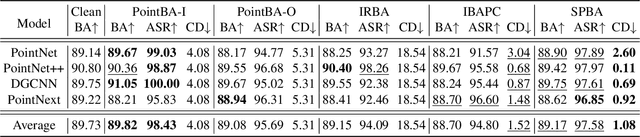
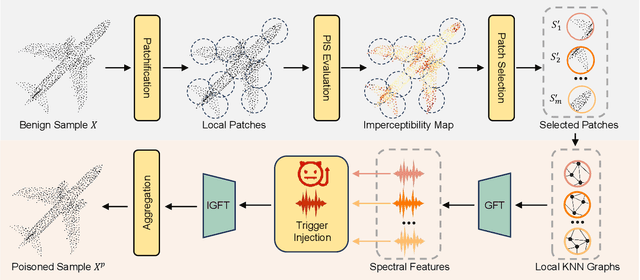
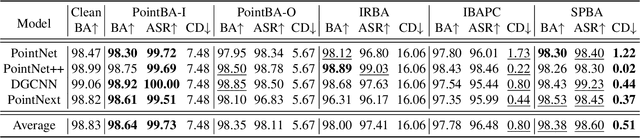
Backdoor attacks pose a severe threat to deep neural networks (DNN) by implanting hidden backdoors that can be activated with predefined triggers to manipulate model behaviors maliciously. Existing 3D point cloud backdoor attacks primarily rely on sample-wise global modifications, resulting in suboptimal stealthiness. To address this limitation, we propose Stealthy Patch-Wise Backdoor Attack (SPBA), which employs the first patch-wise trigger for 3D point clouds and restricts perturbations to local regions, significantly enhancing stealthiness. Specifically, SPBA decomposes point clouds into local patches and evaluates their geometric complexity using a curvature-based patch imperceptibility score, ensuring that the trigger remains less perceptible to the human eye by strategically applying it across multiple geometrically complex patches with lower visual sensitivity. By leveraging the Graph Fourier Transform (GFT), SPBA optimizes a patch-wise spectral trigger that perturbs the spectral features of selected patches, enhancing attack effectiveness while preserving the global geometric structure of the point cloud. Extensive experiments on ModelNet40 and ShapeNetPart demonstrate that SPBA consistently achieves an attack success rate (ASR) exceeding 96.5% across different models while achieving state-of-the-art imperceptibility compared to existing backdoor attack methods.
CA-W3D: Leveraging Context-Aware Knowledge for Weakly Supervised Monocular 3D Detection
Mar 06, 2025Weakly supervised monocular 3D detection, while less annotation-intensive, often struggles to capture the global context required for reliable 3D reasoning. Conventional label-efficient methods focus on object-centric features, neglecting contextual semantic relationships that are critical in complex scenes. In this work, we propose a Context-Aware Weak Supervision for Monocular 3D object detection, namely CA-W3D, to address this limitation in a two-stage training paradigm. Specifically, we first introduce a pre-training stage employing Region-wise Object Contrastive Matching (ROCM), which aligns regional object embeddings derived from a trainable monocular 3D encoder and a frozen open-vocabulary 2D visual grounding model. This alignment encourages the monocular encoder to discriminate scene-specific attributes and acquire richer contextual knowledge. In the second stage, we incorporate a pseudo-label training process with a Dual-to-One Distillation (D2OD) mechanism, which effectively transfers contextual priors into the monocular encoder while preserving spatial fidelity and maintaining computational efficiency during inference. Extensive experiments conducted on the public KITTI benchmark demonstrate the effectiveness of our approach, surpassing the SoTA method over all metrics, highlighting the importance of contextual-aware knowledge in weakly-supervised monocular 3D detection.
DINeuro: Distilling Knowledge from 2D Natural Images via Deformable Tubular Transferring Strategy for 3D Neuron Reconstruction
Oct 29, 2024



Reconstructing neuron morphology from 3D light microscope imaging data is critical to aid neuroscientists in analyzing brain networks and neuroanatomy. With the boost from deep learning techniques, a variety of learning-based segmentation models have been developed to enhance the signal-to-noise ratio of raw neuron images as a pre-processing step in the reconstruction workflow. However, most existing models directly encode the latent representative features of volumetric neuron data but neglect their intrinsic morphological knowledge. To address this limitation, we design a novel framework that distills the prior knowledge from a 2D Vision Transformer pre-trained on extensive 2D natural images to facilitate neuronal morphological learning of our 3D Vision Transformer. To bridge the knowledge gap between the 2D natural image and 3D microscopic morphologic domains, we propose a deformable tubular transferring strategy that adapts the pre-trained 2D natural knowledge to the inherent tubular characteristics of neuronal structure in the latent embedding space. The experimental results on the Janelia dataset of the BigNeuron project demonstrate that our method achieves a segmentation performance improvement of 4.53% in mean Dice and 3.56% in mean 95% Hausdorff distance.