 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Discovery of Quantitative and Formal Models in Social Science
Oct 02, 2022In social science, formal and quantitative models, such as ones describing economic growth and collective action, are used to formulate mechanistic explanations, provide predictions, and uncover questions about observed phenomena. Here, we demonstrate the use of a machine learning system to aid the discovery of symbolic models that capture nonlinear and dynamical relationships in social science datasets. By extending neuro-symbolic methods to find compact functions and differential equations in noisy and longitudinal data, we show that our system can be used to discover interpretable models from real-world data in economics and sociology. Augmenting existing workflows with symbolic regression can help uncover novel relationships and explore counterfactual models during the scientific process. We propose that this AI-assisted framework can bridge parametric and non-parametric models commonly employed in social science research by systematically exploring the space of nonlinear models and enabling fine-grained control over expressivity and interpretability.
Discovering Conservation Laws using Optimal Transport and Manifold Learning
Aug 31, 2022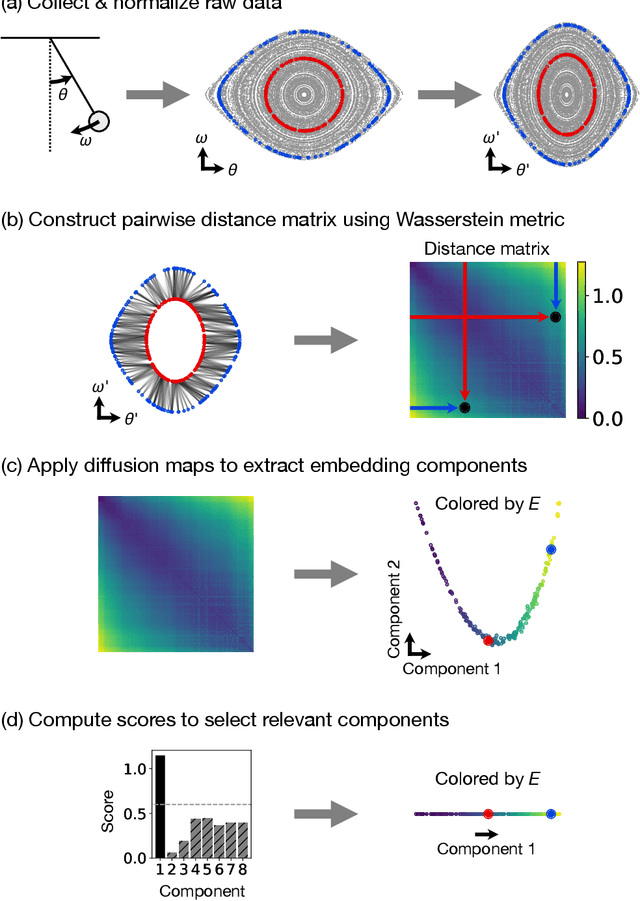
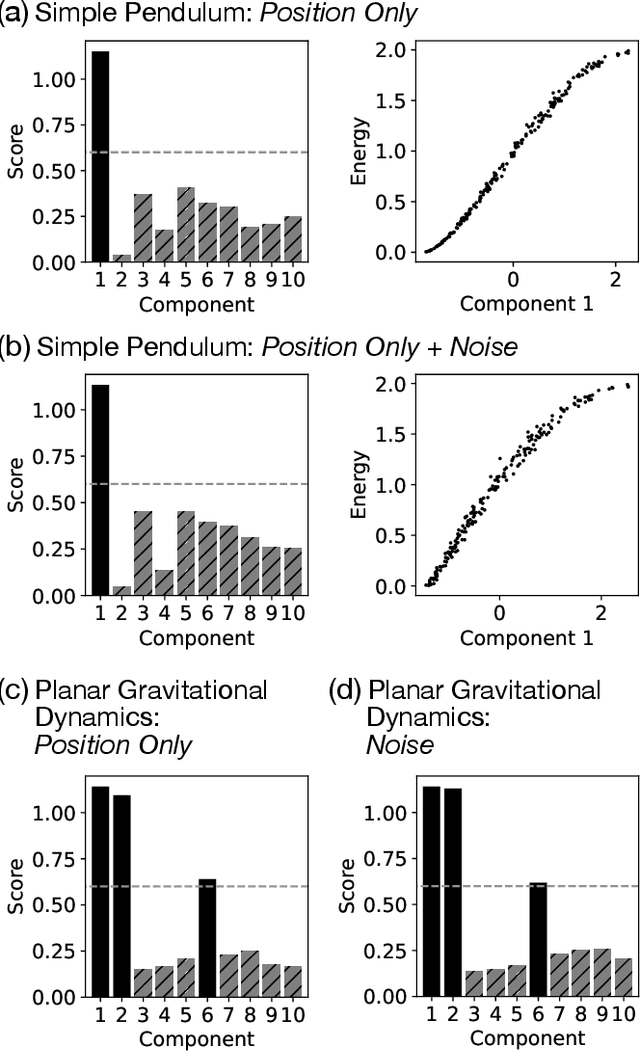
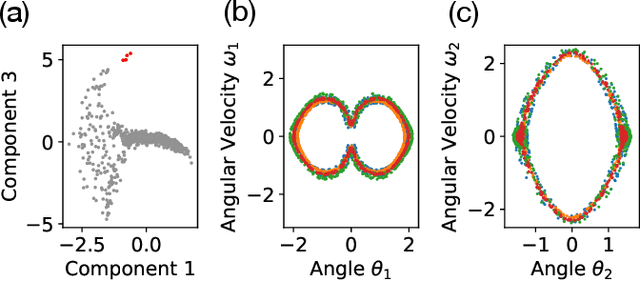
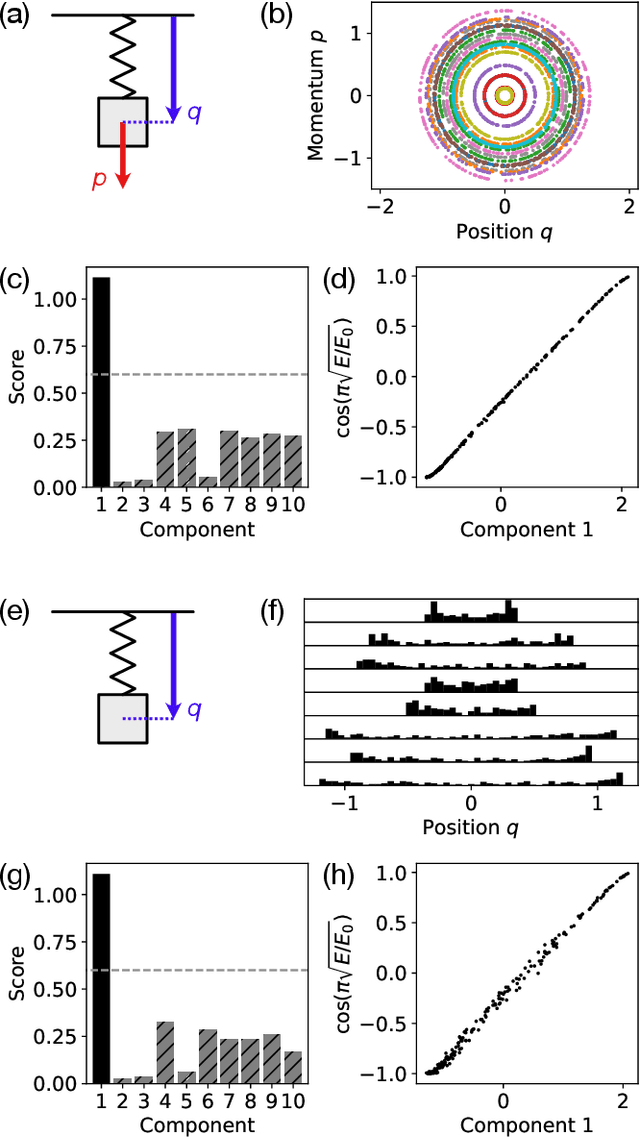
Conservation laws are key theoretical and practical tools for understanding, characterizing, and modeling nonlinear dynamical systems. However, for many complex dynamical systems, the corresponding conserved quantities are difficult to identify, making it hard to analyze their dynamics and build efficient, stable predictive models. Current approaches for discovering conservation laws often depend on detailed dynamical information, such as the equation of motion or fine-grained time measurements, with many recent proposals also relying on black box parametric deep learning methods. We instead reformulate this task as a manifold learning problem and propose a non-parametric approach, combining the Wasserstein metric from optimal transport with diffusion maps, to discover conserved quantities that vary across trajectories sampled from a dynamical system. We test this new approach on a variety of physical systems$\unicode{x2014}$including conservative Hamiltonian systems, dissipative systems, and spatiotemporal systems$\unicode{x2014}$and demonstrate that our manifold learning method is able to both identify the number of conserved quantities and extract their values. Using tools from optimal transport theory and manifold learning, our proposed method provides a direct geometric approach to identifying conservation laws that is both robust and interpretable without requiring an explicit model of the system nor accurate time information.
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Apr 21, 2022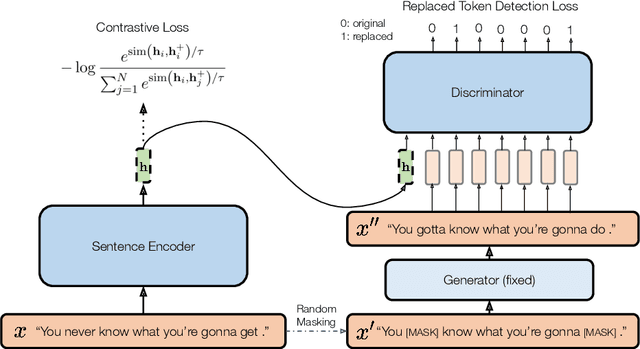
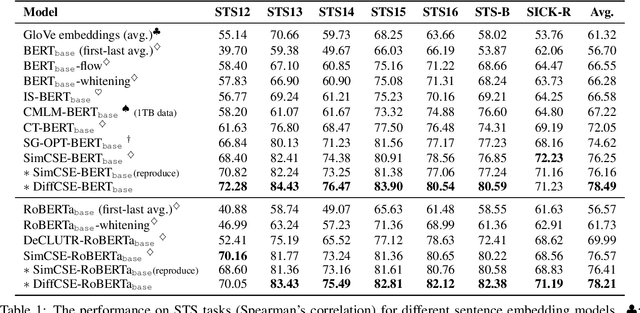
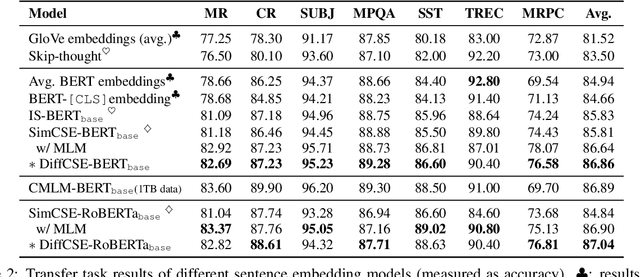
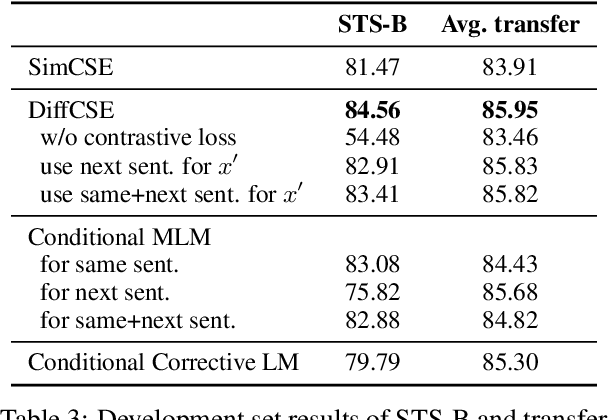
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
Meta-Learning and Self-Supervised Pretraining for Real World Image Translation
Dec 22, 2021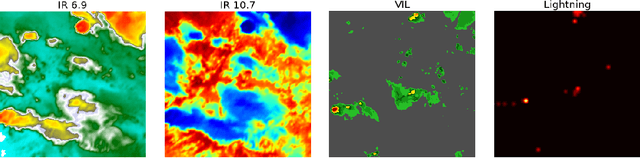
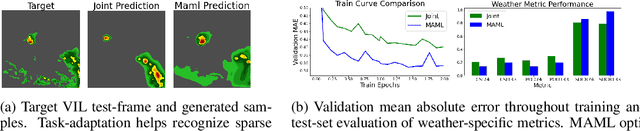
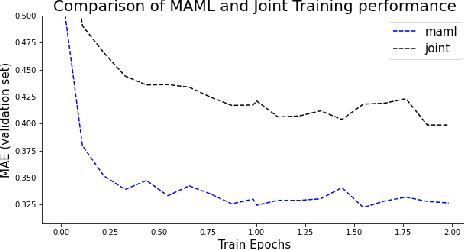

Recent advances in deep learning, in particular enabled by hardware advances and big data, have provided impressive results across a wide range of computational problems such as computer vision, natural language, or reinforcement learning. Many of these improvements are however constrained to problems with large-scale curated data-sets which require a lot of human labor to gather. Additionally, these models tend to generalize poorly under both slight distributional shifts and low-data regimes. In recent years, emerging fields such as meta-learning or self-supervised learning have been closing the gap between proof-of-concept results and real-life applications of machine learning by extending deep-learning to the semi-supervised and few-shot domains. We follow this line of work and explore spatio-temporal structure in a recently introduced image-to-image translation problem in order to: i) formulate a novel multi-task few-shot image generation benchmark and ii) explore data augmentations in contrastive pre-training for image translation downstream tasks. We present several baselines for the few-shot problem and discuss trade-offs between different approaches. Our code is available at https://github.com/irugina/meta-image-translation.
Equivariant Contrastive Learning
Oct 28, 2021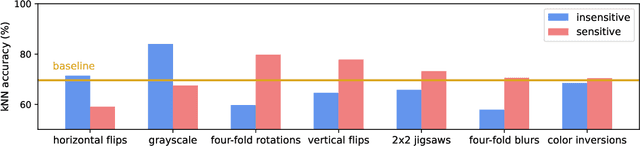
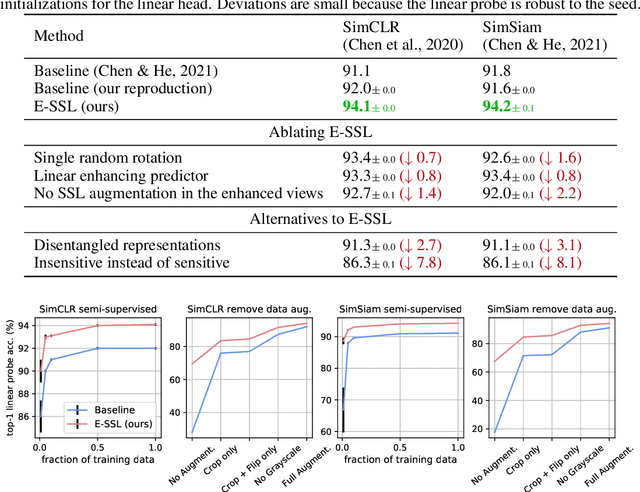


In state-of-the-art self-supervised learning (SSL) pre-training produces semantically good representations by encouraging them to be invariant under meaningful transformations prescribed from human knowledge. In fact, the property of invariance is a trivial instance of a broader class called equivariance, which can be intuitively understood as the property that representations transform according to the way the inputs transform. Here, we show that rather than using only invariance, pre-training that encourages non-trivial equivariance to some transformations, while maintaining invariance to other transformations, can be used to improve the semantic quality of representations. Specifically, we extend popular SSL methods to a more general framework which we name Equivariant Self-Supervised Learning (E-SSL). In E-SSL, a simple additional pre-training objective encourages equivariance by predicting the transformations applied to the input. We demonstrate E-SSL's effectiveness empirically on several popular computer vision benchmarks. Furthermore, we demonstrate usefulness of E-SSL for applications beyond computer vision; in particular, we show its utility on regression problems in photonics science. We will release our code.
Surrogate- and invariance-boosted contrastive learning for data-scarce applications in science
Oct 15, 2021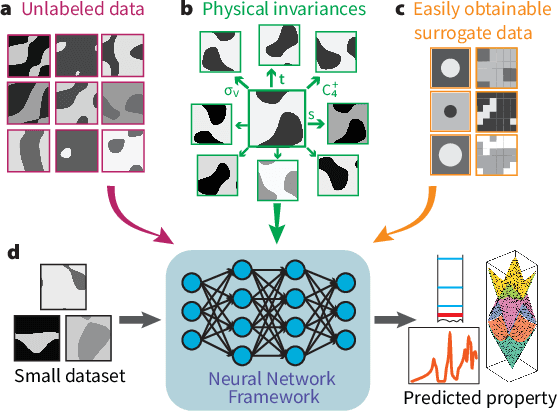
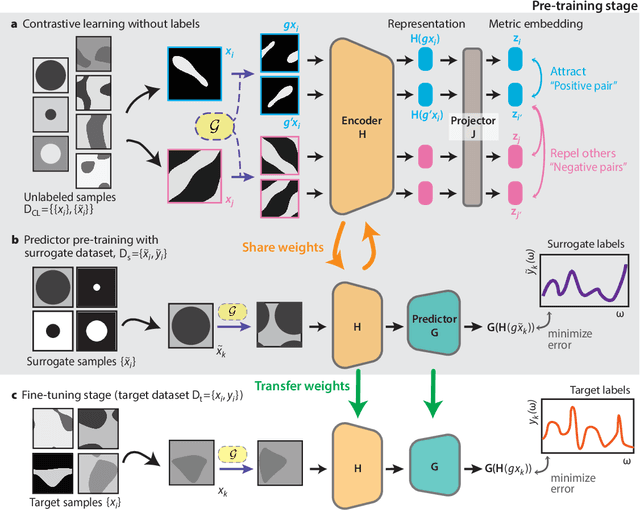
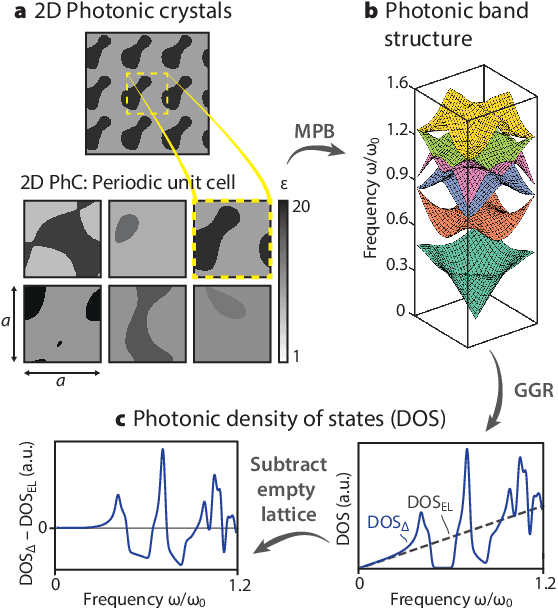
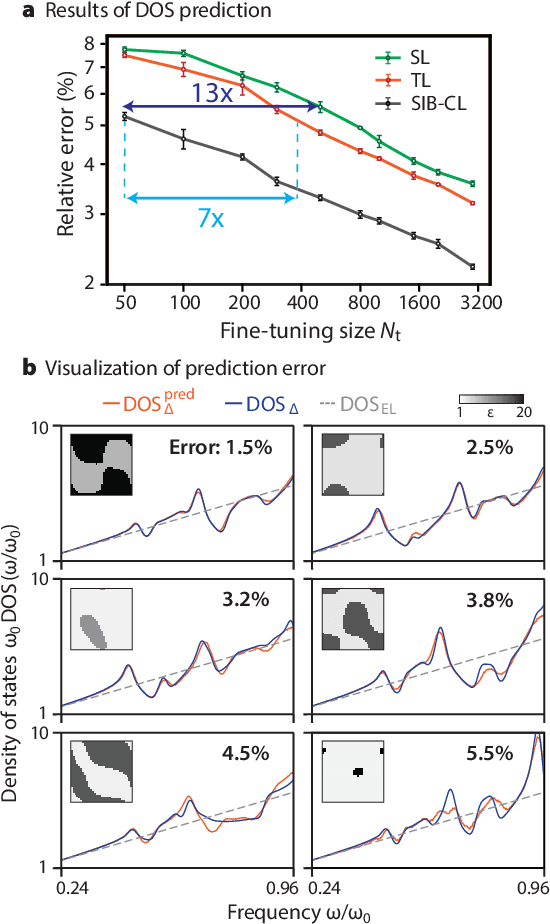
Deep learning techniques have been increasingly applied to the natural sciences, e.g., for property prediction and optimization or material discovery. A fundamental ingredient of such approaches is the vast quantity of labelled data needed to train the model; this poses severe challenges in data-scarce settings where obtaining labels requires substantial computational or labor resources. Here, we introduce surrogate- and invariance-boosted contrastive learning (SIB-CL), a deep learning framework which incorporates three ``inexpensive'' and easily obtainable auxiliary information sources to overcome data scarcity. Specifically, these are: 1)~abundant unlabeled data, 2)~prior knowledge of symmetries or invariances and 3)~surrogate data obtained at near-zero cost. We demonstrate SIB-CL's effectiveness and generality on various scientific problems, e.g., predicting the density-of-states of 2D photonic crystals and solving the 3D time-independent Schrodinger equation. SIB-CL consistently results in orders of magnitude reduction in the number of labels needed to achieve the same network accuracies.
Data-Informed Global Sparseness in Attention Mechanisms for Deep Neural Networks
Nov 20, 2020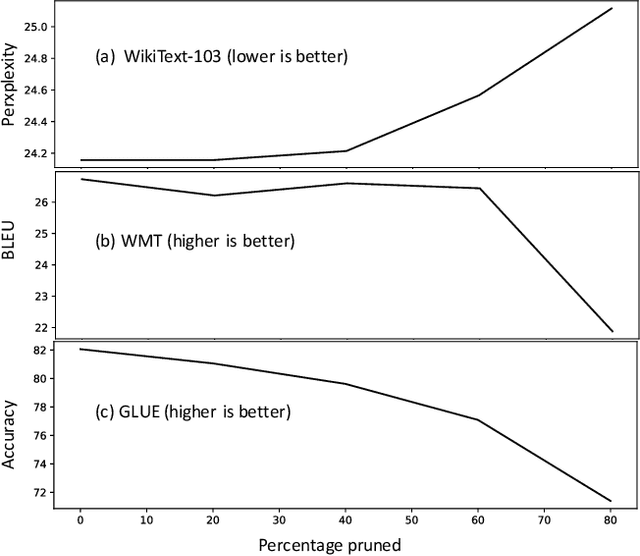
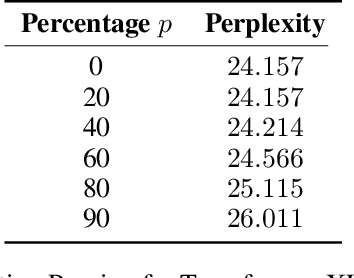
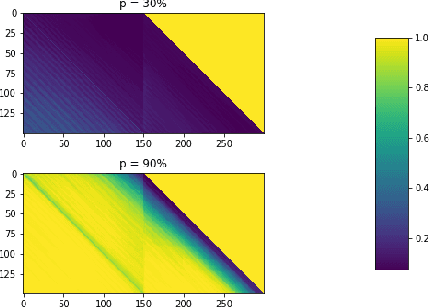
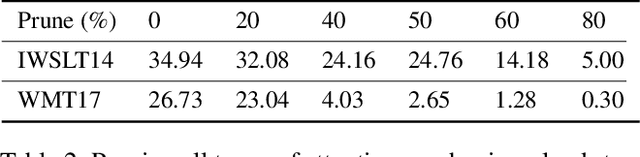
The attention mechanism is a key component of the neural revolution in Natural Language Processing (NLP). As the size of attention-based models has been scaling with the available computational resources, a number of pruning techniques have been developed to detect and to exploit sparseness in such models in order to make them more efficient. The majority of such efforts have focused on looking for attention patterns and then hard-coding them to achieve sparseness, or pruning the weights of the attention mechanisms based on statistical information from the training data. In this paper, we marry these two lines of research by proposing Attention Pruning (AP): a novel pruning framework that collects observations about the attention patterns in a fixed dataset and then induces a global sparseness mask for the model. Through attention pruning, we find that about 90% of the attention computation can be reduced for language modelling and about 50% for machine translation and %natural language inference prediction with BERT on GLUE tasks, while maintaining the quality of the results. Additionally, using our method, we discovered important distinctions between self- and cross-attention patterns, which could guide future NLP research in attention-based modelling. Our approach could help develop better models for existing or for new NLP applications, and generally for any model that relies on attention mechanisms. Our implementation and instructions to reproduce the experiments are available at https://github.com/irugina/AP.
Vector-Vector-Matrix Architecture: A Novel Hardware-Aware Framework for Low-Latency Inference in NLP Applications
Oct 06, 2020
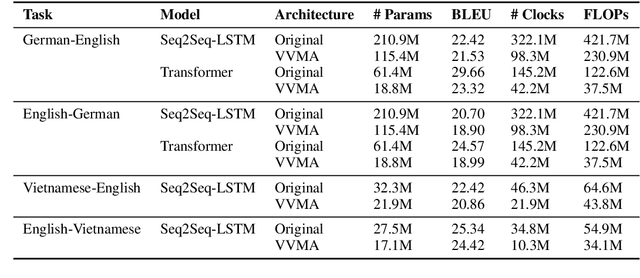
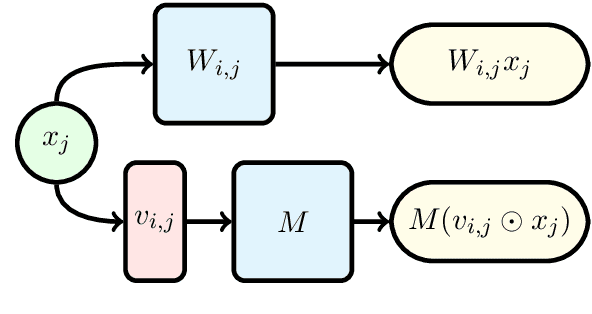
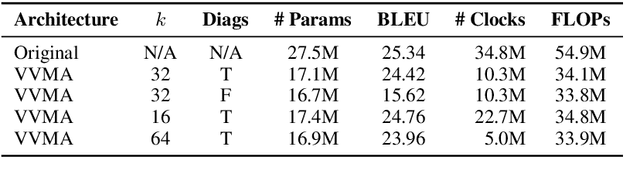
Deep neural networks have become the standard approach to building reliable Natural Language Processing (NLP) applications, ranging from Neural Machine Translation (NMT) to dialogue systems. However, improving accuracy by increasing the model size requires a large number of hardware computations, which can slow down NLP applications significantly at inference time. To address this issue, we propose a novel vector-vector-matrix architecture (VVMA), which greatly reduces the latency at inference time for NMT. This architecture takes advantage of specialized hardware that has low-latency vector-vector operations and higher-latency vector-matrix operations. It also reduces the number of parameters and FLOPs for virtually all models that rely on efficient matrix multipliers without significantly impacting accuracy. We present empirical results suggesting that our framework can reduce the latency of sequence-to-sequence and Transformer models used for NMT by a factor of four. Finally, we show evidence suggesting that our VVMA extends to other domains, and we discuss novel hardware for its efficient use.
On a Novel Application of Wasserstein-Procrustes for Unsupervised Cross-Lingual Learning
Jul 18, 2020
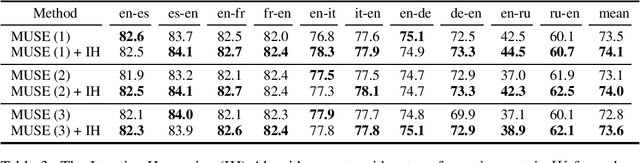

The emergence of unsupervised word embeddings, pre-trained on very large monolingual text corpora, is at the core of the ongoing neural revolution in Natural Language Processing (NLP). Initially introduced for English, such pre-trained word embeddings quickly emerged for a number of other languages. Subsequently, there have been a number of attempts to align the embedding spaces across languages, which could enable a number of cross-language NLP applications. Performing the alignment using unsupervised cross-lingual learning (UCL) is especially attractive as it requires little data and often rivals supervised and semi-supervised approaches. Here, we analyze popular methods for UCL and we find that often their objectives are, intrinsically, versions of the Wasserstein-Procrustes problem. Hence, we devise an approach to solve Wasserstein-Procrustes in a direct way, which can be used to refine and to improve popular UCL methods such as iterative closest point (ICP), multilingual unsupervised and supervised embeddings (MUSE) and supervised Procrustes methods. Our evaluation experiments on standard datasets show sizable improvements over these approaches. We believe that our rethinking of the Wasserstein-Procrustes problem could enable further research, thus helping to develop better algorithms for aligning word embeddings across languages. Our code and instructions to reproduce the experiments are available at https://github.com/guillemram97/wp-hungarian.
Contextualizing Enhances Gradient Based Meta Learning
Jul 17, 2020
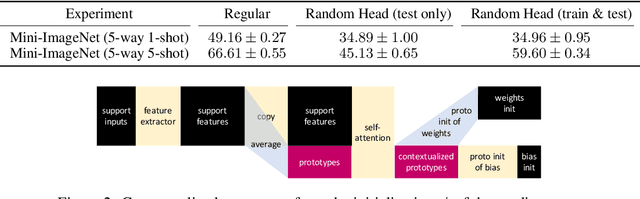
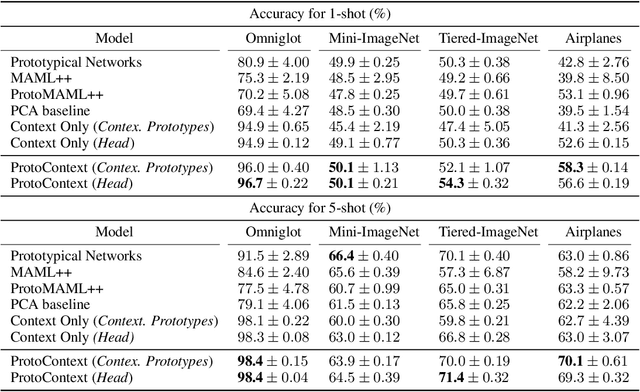
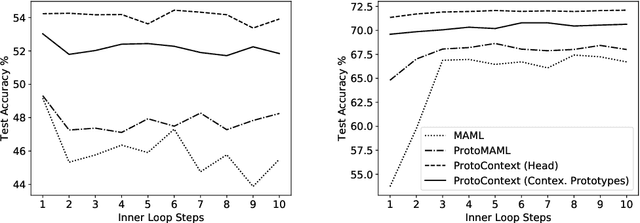
Meta learning methods have found success when applied to few shot classification problems, in which they quickly adapt to a small number of labeled examples. Prototypical representations, each representing a particular class, have been of particular importance in this setting, as they provide a compact form to convey information learned from the labeled examples. However, these prototypes are just one method of representing this information, and they are narrow in their scope and ability to classify unseen examples. We propose the implementation of contextualizers, which are generalizable prototypes that adapt to given examples and play a larger role in classification for gradient-based models. We demonstrate how to equip meta learning methods with contextualizers and show that their use can significantly boost performance on a range of few shot learning datasets. We also present figures of merit demonstrating the potential benefits of contextualizers, along with analysis of how models make use of them. Our approach is particularly apt for low-data environments where it is difficult to update parameters without overfitting. Our implementation and instructions to reproduce the experiments are available at https://github.com/naveace/proto-context.