 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning for Protection: Increasing Jailbreak Resistance in Aligned LLMs Without Fine-Tuning
Jan 19, 2024Large Language Models (LLMs) are vulnerable to `Jailbreaking' prompts, a type of attack that can coax these models into generating harmful and illegal content. In this paper, we show that pruning up to 20% of LLM parameters markedly increases their resistance to such attacks without additional training and without sacrificing their performance in standard benchmarks. Intriguingly, we discovered that the enhanced safety observed post-pruning correlates to the initial safety training level of the model, hinting that the effect of pruning could be more general and may hold for other LLM behaviors beyond safety. Additionally, we introduce a curated dataset of 225 harmful tasks across five categories, inserted into ten different Jailbreaking prompts, showing that pruning aids LLMs in concentrating attention on task-relevant tokens in jailbreaking prompts. Lastly, our experiments reveal that the prominent chat models, such as LLaMA-2 Chat, Vicuna, and Mistral Instruct exhibit high susceptibility to jailbreaking attacks, with some categories achieving nearly 70-100% success rate. These insights underline the potential of pruning as a generalizable approach for improving LLM safety, reliability, and potentially other desired behaviors.
Meta-Learning and Self-Supervised Pretraining for Real World Image Translation
Dec 22, 2021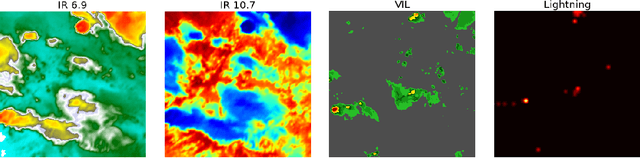
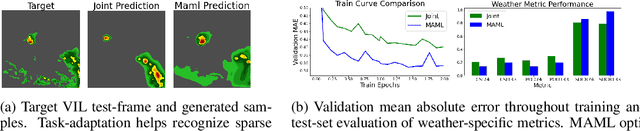
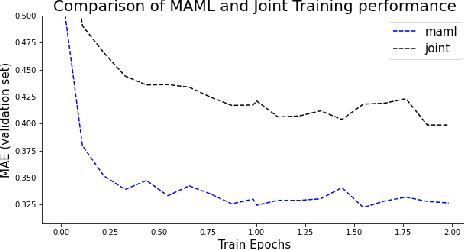

Recent advances in deep learning, in particular enabled by hardware advances and big data, have provided impressive results across a wide range of computational problems such as computer vision, natural language, or reinforcement learning. Many of these improvements are however constrained to problems with large-scale curated data-sets which require a lot of human labor to gather. Additionally, these models tend to generalize poorly under both slight distributional shifts and low-data regimes. In recent years, emerging fields such as meta-learning or self-supervised learning have been closing the gap between proof-of-concept results and real-life applications of machine learning by extending deep-learning to the semi-supervised and few-shot domains. We follow this line of work and explore spatio-temporal structure in a recently introduced image-to-image translation problem in order to: i) formulate a novel multi-task few-shot image generation benchmark and ii) explore data augmentations in contrastive pre-training for image translation downstream tasks. We present several baselines for the few-shot problem and discuss trade-offs between different approaches. Our code is available at https://github.com/irugina/meta-image-translation.
Data-Informed Global Sparseness in Attention Mechanisms for Deep Neural Networks
Nov 20, 2020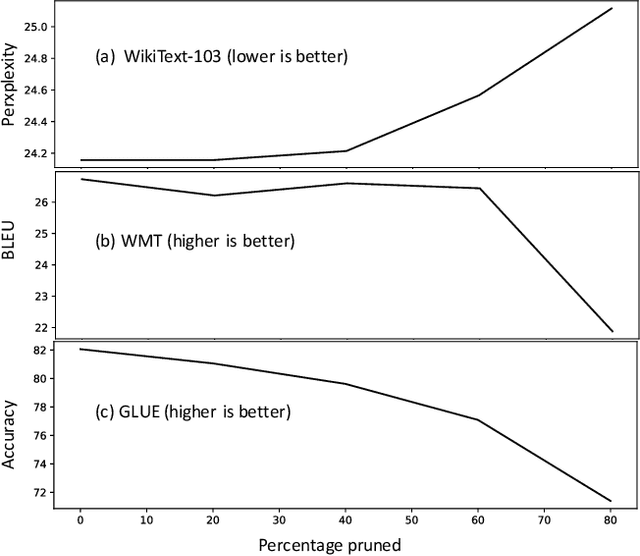
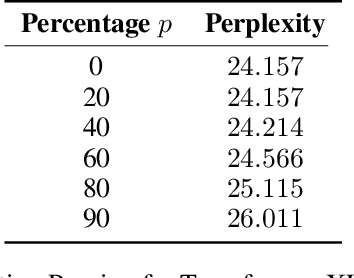
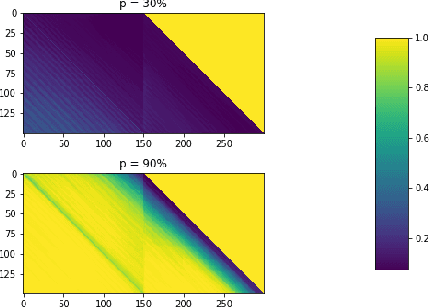
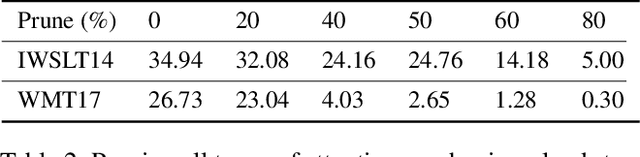
The attention mechanism is a key component of the neural revolution in Natural Language Processing (NLP). As the size of attention-based models has been scaling with the available computational resources, a number of pruning techniques have been developed to detect and to exploit sparseness in such models in order to make them more efficient. The majority of such efforts have focused on looking for attention patterns and then hard-coding them to achieve sparseness, or pruning the weights of the attention mechanisms based on statistical information from the training data. In this paper, we marry these two lines of research by proposing Attention Pruning (AP): a novel pruning framework that collects observations about the attention patterns in a fixed dataset and then induces a global sparseness mask for the model. Through attention pruning, we find that about 90% of the attention computation can be reduced for language modelling and about 50% for machine translation and %natural language inference prediction with BERT on GLUE tasks, while maintaining the quality of the results. Additionally, using our method, we discovered important distinctions between self- and cross-attention patterns, which could guide future NLP research in attention-based modelling. Our approach could help develop better models for existing or for new NLP applications, and generally for any model that relies on attention mechanisms. Our implementation and instructions to reproduce the experiments are available at https://github.com/irugina/AP.