 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual SONAR: Cross-Lingual and Cross-Modal Sentence Embeddings Bridging Massively Multilingual Text and Speech
Mar 17, 2026Cross-lingual sentence encoders typically cover only a few hundred languages and often trade downstream quality for stronger alignment, limiting their adoption. We introduce OmniSONAR, a new family of omnilingual, cross-lingual and cross-modal sentence embedding models that natively embed text, speech, code, and mathematical expressions in a single semantic space, while delivering state-of-the-art downstream performance at the scale of thousands of languages, from high-resource to extremely low-resource varieties. To reach this scale without representation collapse, we use progressive training. We first learn a strong foundational space for 200 languages with an LLM-initialized encoder-decoder, combining token-level decoding with a novel split-softmax contrastive loss and synthetic hard negatives. Building on this foundation, we expand to several thousands language varieties via a two-stage teacher-student encoder distillation framework. Finally, we demonstrate the cross-modal extensibility of this space by seamlessly mapping 177 spoken languages into it. OmniSONAR halves cross-lingual similarity search error on the 200-language FLORES dataset and reduces error by a factor of 15 on the 1,560-language BIBLE benchmark. It also enables strong translation, outperforming NLLB-3B on multilingual benchmarks and exceeding prior models (including much larger LLMs) by 15 chrF++ points on 1,560 languages into English BIBLE translation. OmniSONAR also performs strongly on MTEB and XLCoST. For speech, OmniSONAR achieves a 43% lower similarity-search error and reaches 97% of SeamlessM4T speech-to-text quality, despite being zero-shot for translation (trained only on ASR data). Finally, by training an encoder-decoder LM, Spectrum, exclusively on English text processing OmniSONAR embedding sequences, we unlock high-performance transfer to thousands of languages and speech for complex downstream tasks.
Optimising Calls to Large Language Models with Uncertainty-Based Two-Tier Selection
May 03, 2024Researchers and practitioners operating on a limited budget face the cost-performance trade-off dilemma. The challenging decision often centers on whether to use a large LLM with better performance or a smaller one with reduced costs. This has motivated recent research in the optimisation of LLM calls. Either a cascading strategy is used, where a smaller LLM or both are called sequentially, or a routing strategy is used, where only one model is ever called. Both scenarios are dependent on a decision criterion which is typically implemented by an extra neural model. In this work, we propose a simpler solution; we use only the uncertainty of the generations of the small LLM as the decision criterion. We compare our approach with both cascading and routing strategies using three different pairs of pre-trained small and large LLMs, on nine different tasks and against approaches that require an additional neural model. Our experiments reveal this simple solution optimally balances cost and performance, outperforming existing methods on 25 out of 27 experimental setups.
Cache & Distil: Optimising API Calls to Large Language Models
Oct 20, 2023



Large-scale deployment of generative AI tools often depends on costly API calls to a Large Language Model (LLM) to fulfil user queries. To curtail the frequency of these calls, one can employ a smaller language model -- a student -- which is continuously trained on the responses of the LLM. This student gradually gains proficiency in independently handling an increasing number of user requests, a process we term neural caching. The crucial element in neural caching is a policy that decides which requests should be processed by the student alone and which should be redirected to the LLM, subsequently aiding the student's learning. In this study, we focus on classification tasks, and we consider a range of classic active learning-based selection criteria as the policy. Our experiments suggest that Margin Sampling and Query by Committee bring consistent benefits across tasks and budgets.
On a Novel Application of Wasserstein-Procrustes for Unsupervised Cross-Lingual Learning
Jul 18, 2020
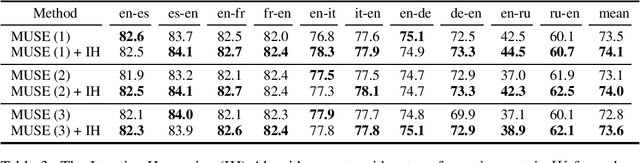

The emergence of unsupervised word embeddings, pre-trained on very large monolingual text corpora, is at the core of the ongoing neural revolution in Natural Language Processing (NLP). Initially introduced for English, such pre-trained word embeddings quickly emerged for a number of other languages. Subsequently, there have been a number of attempts to align the embedding spaces across languages, which could enable a number of cross-language NLP applications. Performing the alignment using unsupervised cross-lingual learning (UCL) is especially attractive as it requires little data and often rivals supervised and semi-supervised approaches. Here, we analyze popular methods for UCL and we find that often their objectives are, intrinsically, versions of the Wasserstein-Procrustes problem. Hence, we devise an approach to solve Wasserstein-Procrustes in a direct way, which can be used to refine and to improve popular UCL methods such as iterative closest point (ICP), multilingual unsupervised and supervised embeddings (MUSE) and supervised Procrustes methods. Our evaluation experiments on standard datasets show sizable improvements over these approaches. We believe that our rethinking of the Wasserstein-Procrustes problem could enable further research, thus helping to develop better algorithms for aligning word embeddings across languages. Our code and instructions to reproduce the experiments are available at https://github.com/guillemram97/wp-hungarian.