 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimentation Platforms Meet Reinforcement Learning: Bayesian Sequential Decision-Making for Continuous Monitoring
Apr 02, 2023With the growing needs of online A/B testing to support the innovation in industry, the opportunity cost of running an experiment becomes non-negligible. Therefore, there is an increasing demand for an efficient continuous monitoring service that allows early stopping when appropriate. Classic statistical methods focus on hypothesis testing and are mostly developed for traditional high-stake problems such as clinical trials, while experiments at online service companies typically have very different features and focuses. Motivated by the real needs, in this paper, we introduce a novel framework that we developed in Amazon to maximize customer experience and control opportunity cost. We formulate the problem as a Bayesian optimal sequential decision making problem that has a unified utility function. We discuss extensively practical design choices and considerations. We further introduce how to solve the optimal decision rule via Reinforcement Learning and scale the solution. We show the effectiveness of this novel approach compared with existing methods via a large-scale meta-analysis on experiments in Amazon.
Rigidity-Aware Detection for 6D Object Pose Estimation
Mar 22, 2023Most recent 6D object pose estimation methods first use object detection to obtain 2D bounding boxes before actually regressing the pose. However, the general object detection methods they use are ill-suited to handle cluttered scenes, thus producing poor initialization to the subsequent pose network. To address this, we propose a rigidity-aware detection method exploiting the fact that, in 6D pose estimation, the target objects are rigid. This lets us introduce an approach to sampling positive object regions from the entire visible object area during training, instead of naively drawing samples from the bounding box center where the object might be occluded. As such, every visible object part can contribute to the final bounding box prediction, yielding better detection robustness. Key to the success of our approach is a visibility map, which we propose to build using a minimum barrier distance between every pixel in the bounding box and the box boundary. Our results on seven challenging 6D pose estimation datasets evidence that our method outperforms general detection frameworks by a large margin. Furthermore, combined with a pose regression network, we obtain state-of-the-art pose estimation results on the challenging BOP benchmark.
V2V4Real: A Real-world Large-scale Dataset for Vehicle-to-Vehicle Cooperative Perception
Mar 19, 2023



Modern perception systems of autonomous vehicles are known to be sensitive to occlusions and lack the capability of long perceiving range. It has been one of the key bottlenecks that prevents Level 5 autonomy. Recent research has demonstrated that the Vehicle-to-Vehicle (V2V) cooperative perception system has great potential to revolutionize the autonomous driving industry. However, the lack of a real-world dataset hinders the progress of this field. To facilitate the development of cooperative perception, we present V2V4Real, the first large-scale real-world multi-modal dataset for V2V perception. The data is collected by two vehicles equipped with multi-modal sensors driving together through diverse scenarios. Our V2V4Real dataset covers a driving area of 410 km, comprising 20K LiDAR frames, 40K RGB frames, 240K annotated 3D bounding boxes for 5 classes, and HDMaps that cover all the driving routes. V2V4Real introduces three perception tasks, including cooperative 3D object detection, cooperative 3D object tracking, and Sim2Real domain adaptation for cooperative perception. We provide comprehensive benchmarks of recent cooperative perception algorithms on three tasks. The V2V4Real dataset can be found at https://research.seas.ucla.edu/mobility-lab/v2v4real/.
Multiplier Bootstrap-based Exploration
Feb 03, 2023Despite the great interest in the bandit problem, designing efficient algorithms for complex models remains challenging, as there is typically no analytical way to quantify uncertainty. In this paper, we propose Multiplier Bootstrap-based Exploration (MBE), a novel exploration strategy that is applicable to any reward model amenable to weighted loss minimization. We prove both instance-dependent and instance-independent rate-optimal regret bounds for MBE in sub-Gaussian multi-armed bandits. With extensive simulation and real data experiments, we show the generality and adaptivity of MBE.
A Reinforcement Learning Framework for Dynamic Mediation Analysis
Jan 31, 2023Mediation analysis learns the causal effect transmitted via mediator variables between treatments and outcomes and receives increasing attention in various scientific domains to elucidate causal relations. Most existing works focus on point-exposure studies where each subject only receives one treatment at a single time point. However, there are a number of applications (e.g., mobile health) where the treatments are sequentially assigned over time and the dynamic mediation effects are of primary interest. Proposing a reinforcement learning (RL) framework, we are the first to evaluate dynamic mediation effects in settings with infinite horizons. We decompose the average treatment effect into an immediate direct effect, an immediate mediation effect, a delayed direct effect, and a delayed mediation effect. Upon the identification of each effect component, we further develop robust and semi-parametrically efficient estimators under the RL framework to infer these causal effects. The superior performance of the proposed method is demonstrated through extensive numerical studies, theoretical results, and an analysis of a mobile health dataset.
On Heterogeneous Treatment Effects in Heterogeneous Causal Graphs
Jan 29, 2023



Heterogeneity and comorbidity are two interwoven challenges associated with various healthcare problems that greatly hampered research on developing effective treatment and understanding of the underlying neurobiological mechanism. Very few studies have been conducted to investigate heterogeneous causal effects (HCEs) in graphical contexts due to the lack of statistical methods. To characterize this heterogeneity, we first conceptualize heterogeneous causal graphs (HCGs) by generalizing the causal graphical model with confounder-based interactions and multiple mediators. Such confounders with an interaction with the treatment are known as moderators. This allows us to flexibly produce HCGs given different moderators and explicitly characterize HCEs from the treatment or potential mediators on the outcome. We establish the theoretical forms of HCEs and derive their properties at the individual level in both linear and nonlinear models. An interactive structural learning is developed to estimate the complex HCGs and HCEs with confidence intervals provided. Our method is empirically justified by extensive simulations and its practical usefulness is illustrated by exploring causality among psychiatric disorders for trauma survivors.
On Learning Necessary and Sufficient Causal Graphs
Jan 29, 2023
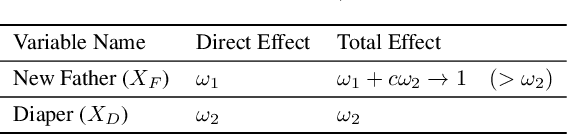
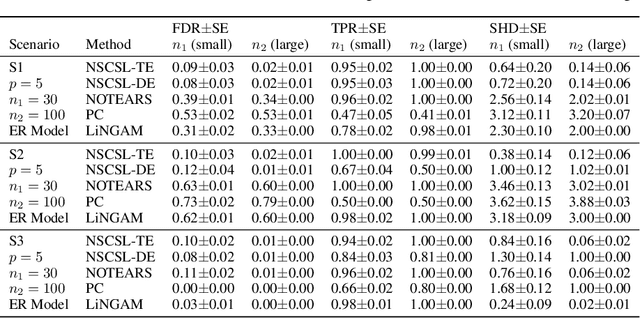
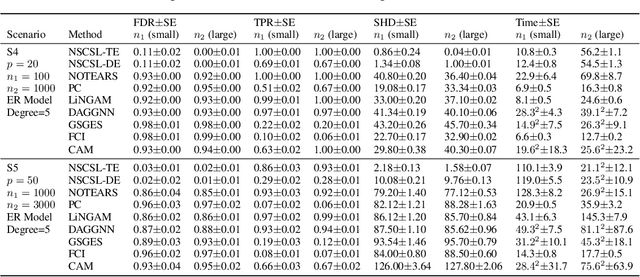
The causal revolution has spurred interest in understanding complex relationships in various fields. Most existing methods aim to discover causal relationships among all variables in a large-scale complex graph. However, in practice, only a small number of variables in the graph are relevant for the outcomes of interest. As a result, causal estimation with the full causal graph -- especially given limited data -- could lead to many falsely discovered, spurious variables that may be highly correlated with but have no causal impact on the target outcome. In this paper, we propose to learn a class of necessary and sufficient causal graphs (NSCG) that only contains causally relevant variables for an outcome of interest, which we term causal features. The key idea is to utilize probabilities of causation to systematically evaluate the importance of features in the causal graph, allowing us to identify a subgraph that is relevant to the outcome of interest. To learn NSCG from data, we develop a score-based necessary and sufficient causal structural learning (NSCSL) algorithm, by establishing theoretical relationships between probabilities of causation and causal effects of features. Across empirical studies of simulated and real data, we show that the proposed NSCSL algorithm outperforms existing algorithms and can reveal important yeast genes for target heritable traits of interest.
Mining the Factor Zoo: Estimation of Latent Factor Models with Sufficient Proxies
Jan 03, 2023Latent factor model estimation typically relies on either using domain knowledge to manually pick several observed covariates as factor proxies, or purely conducting multivariate analysis such as principal component analysis. However, the former approach may suffer from the bias while the latter can not incorporate additional information. We propose to bridge these two approaches while allowing the number of factor proxies to diverge, and hence make the latent factor model estimation robust, flexible, and statistically more accurate. As a bonus, the number of factors is also allowed to grow. At the heart of our method is a penalized reduced rank regression to combine information. To further deal with heavy-tailed data, a computationally attractive penalized robust reduced rank regression method is proposed. We establish faster rates of convergence compared with the benchmark. Extensive simulations and real examples are used to illustrate the advantages.
Deep Spectral Q-learning with Application to Mobile Health
Jan 03, 2023Dynamic treatment regimes assign personalized treatments to patients sequentially over time based on their baseline information and time-varying covariates. In mobile health applications, these covariates are typically collected at different frequencies over a long time horizon. In this paper, we propose a deep spectral Q-learning algorithm, which integrates principal component analysis (PCA) with deep Q-learning to handle the mixed frequency data. In theory, we prove that the mean return under the estimated optimal policy converges to that under the optimal one and establish its rate of convergence. The usefulness of our proposal is further illustrated via simulations and an application to a diabetes dataset.
Heterogeneous Synthetic Learner for Panel Data
Dec 30, 2022



In the new era of personalization, learning the heterogeneous treatment effect (HTE) becomes an inevitable trend with numerous applications. Yet, most existing HTE estimation methods focus on independently and identically distributed observations and cannot handle the non-stationarity and temporal dependency in the common panel data setting. The treatment evaluators developed for panel data, on the other hand, typically ignore the individualized information. To fill the gap, in this paper, we initialize the study of HTE estimation in panel data. Under different assumptions for HTE identifiability, we propose the corresponding heterogeneous one-side and two-side synthetic learner, namely H1SL and H2SL, by leveraging the state-of-the-art HTE estimator for non-panel data and generalizing the synthetic control method that allows flexible data generating process. We establish the convergence rates of the proposed estimators. The superior performance of the proposed methods over existing ones is demonstrated by extensive numerical studies.