 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Deep Embedding for Clustering Analysis
May 24, 2016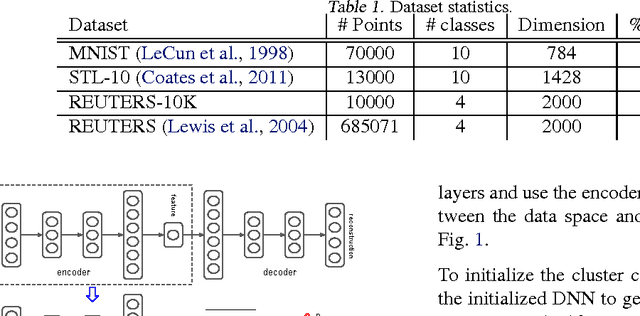
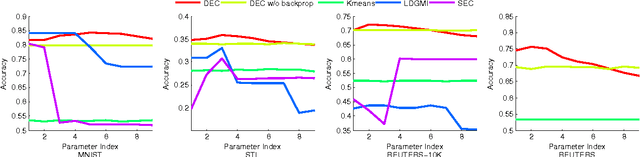
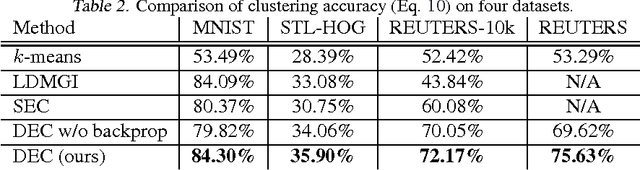

Clustering is central to many data-driven application domains and has been studied extensively in terms of distance functions and grouping algorithms. Relatively little work has focused on learning representations for clustering. In this paper, we propose Deep Embedded Clustering (DEC), a method that simultaneously learns feature representations and cluster assignments using deep neural networks. DEC learns a mapping from the data space to a lower-dimensional feature space in which it iteratively optimizes a clustering objective. Our experimental evaluations on image and text corpora show significant improvement over state-of-the-art methods.
You Only Look Once: Unified, Real-Time Object Detection
May 09, 2016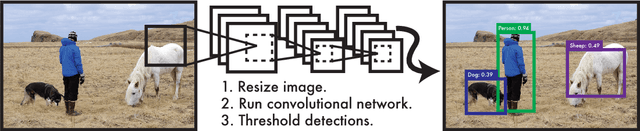
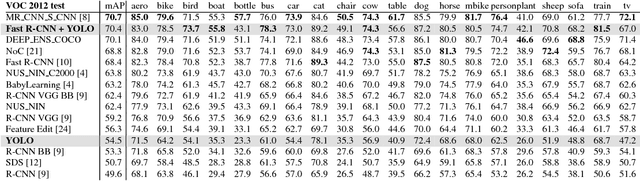
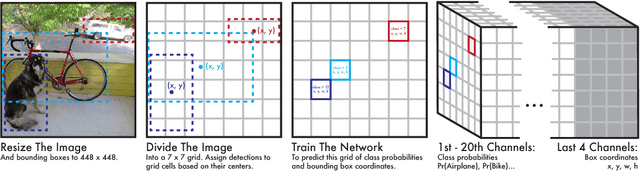
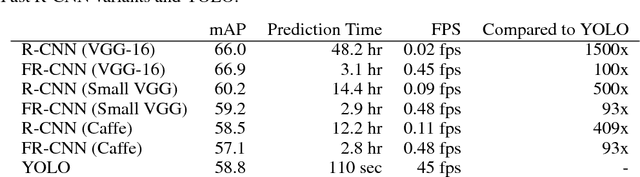
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is far less likely to predict false detections where nothing exists. Finally, YOLO learns very general representations of objects. It outperforms all other detection methods, including DPM and R-CNN, by a wide margin when generalizing from natural images to artwork on both the Picasso Dataset and the People-Art Dataset.
Visual Storytelling
Apr 13, 2016

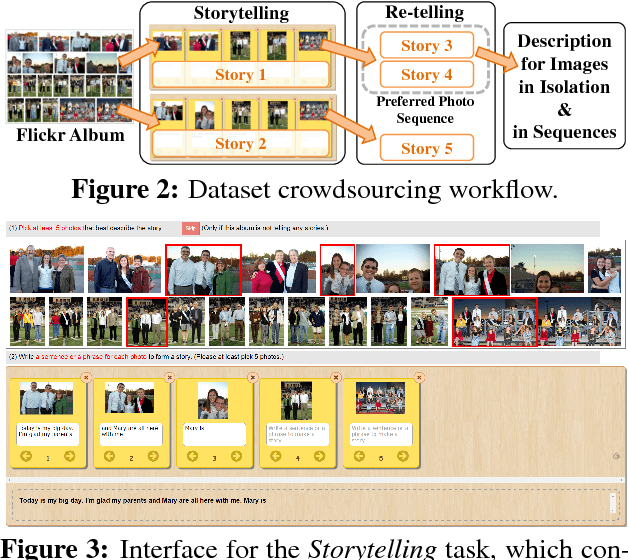
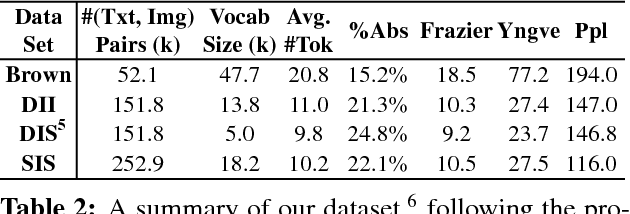
We introduce the first dataset for sequential vision-to-language, and explore how this data may be used for the task of visual storytelling. The first release of this dataset, SIND v.1, includes 81,743 unique photos in 20,211 sequences, aligned to both descriptive (caption) and story language. We establish several strong baselines for the storytelling task, and motivate an automatic metric to benchmark progress. Modelling concrete description as well as figurative and social language, as provided in this dataset and the storytelling task, has the potential to move artificial intelligence from basic understandings of typical visual scenes towards more and more human-like understanding of grounded event structure and subjective expression.
Deep3D: Fully Automatic 2D-to-3D Video Conversion with Deep Convolutional Neural Networks
Apr 13, 2016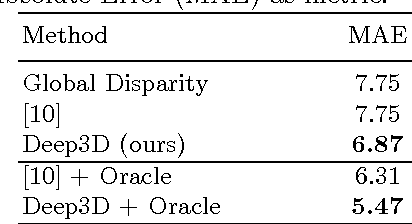
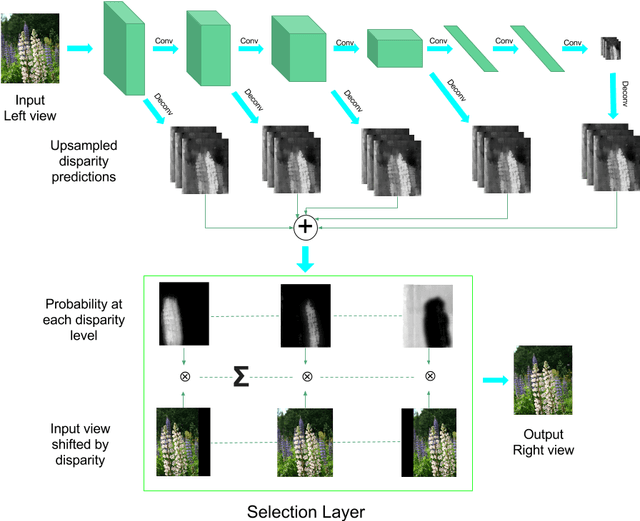
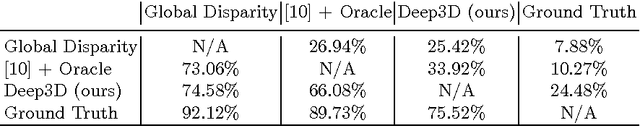

As 3D movie viewing becomes mainstream and Virtual Reality (VR) market emerges, the demand for 3D contents is growing rapidly. Producing 3D videos, however, remains challenging. In this paper we propose to use deep neural networks for automatically converting 2D videos and images to stereoscopic 3D format. In contrast to previous automatic 2D-to-3D conversion algorithms, which have separate stages and need ground truth depth map as supervision, our approach is trained end-to-end directly on stereo pairs extracted from 3D movies. This novel training scheme makes it possible to exploit orders of magnitude more data and significantly increases performance. Indeed, Deep3D outperforms baselines in both quantitative and human subject evaluations.
Seeing through the Human Reporting Bias: Visual Classifiers from Noisy Human-Centric Labels
Apr 12, 2016
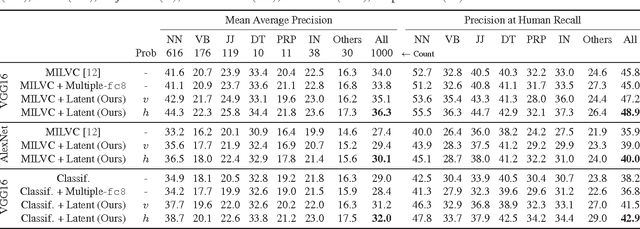
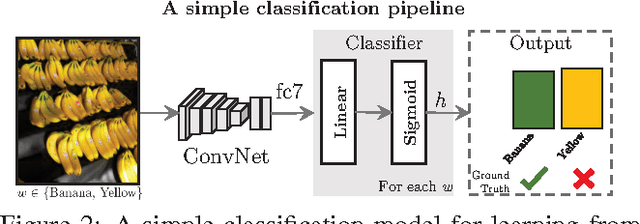
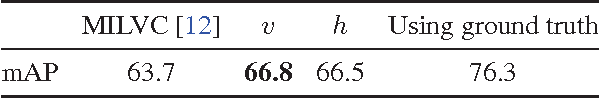
When human annotators are given a choice about what to label in an image, they apply their own subjective judgments on what to ignore and what to mention. We refer to these noisy "human-centric" annotations as exhibiting human reporting bias. Examples of such annotations include image tags and keywords found on photo sharing sites, or in datasets containing image captions. In this paper, we use these noisy annotations for learning visually correct image classifiers. Such annotations do not use consistent vocabulary, and miss a significant amount of the information present in an image; however, we demonstrate that the noise in these annotations exhibits structure and can be modeled. We propose an algorithm to decouple the human reporting bias from the correct visually grounded labels. Our results are highly interpretable for reporting "what's in the image" versus "what's worth saying." We demonstrate the algorithm's efficacy along a variety of metrics and datasets, including MS COCO and Yahoo Flickr 100M. We show significant improvements over traditional algorithms for both image classification and image captioning, doubling the performance of existing methods in some cases.
Training Region-based Object Detectors with Online Hard Example Mining
Apr 12, 2016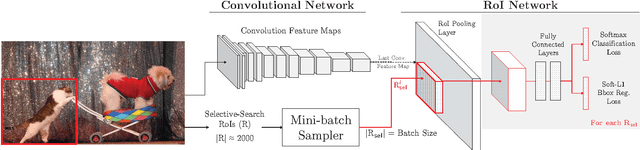
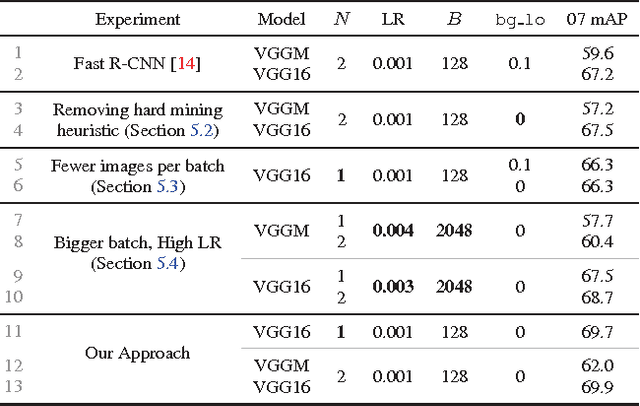
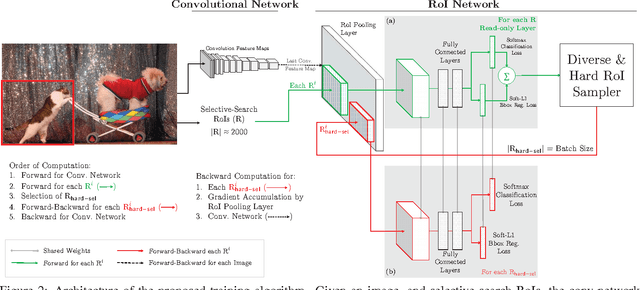

The field of object detection has made significant advances riding on the wave of region-based ConvNets, but their training procedure still includes many heuristics and hyperparameters that are costly to tune. We present a simple yet surprisingly effective online hard example mining (OHEM) algorithm for training region-based ConvNet detectors. Our motivation is the same as it has always been -- detection datasets contain an overwhelming number of easy examples and a small number of hard examples. Automatic selection of these hard examples can make training more effective and efficient. OHEM is a simple and intuitive algorithm that eliminates several heuristics and hyperparameters in common use. But more importantly, it yields consistent and significant boosts in detection performance on benchmarks like PASCAL VOC 2007 and 2012. Its effectiveness increases as datasets become larger and more difficult, as demonstrated by the results on the MS COCO dataset. Moreover, combined with complementary advances in the field, OHEM leads to state-of-the-art results of 78.9% and 76.3% mAP on PASCAL VOC 2007 and 2012 respectively.
Contextual Action Recognition with R*CNN
Mar 25, 2016
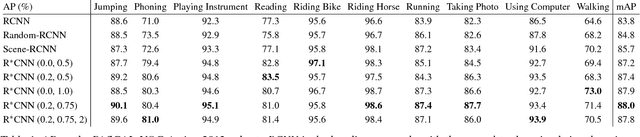
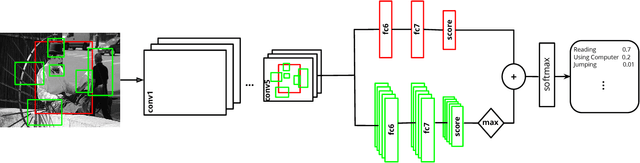

There are multiple cues in an image which reveal what action a person is performing. For example, a jogger has a pose that is characteristic for jogging, but the scene (e.g. road, trail) and the presence of other joggers can be an additional source of information. In this work, we exploit the simple observation that actions are accompanied by contextual cues to build a strong action recognition system. We adapt RCNN to use more than one region for classification while still maintaining the ability to localize the action. We call our system R*CNN. The action-specific models and the feature maps are trained jointly, allowing for action specific representations to emerge. R*CNN achieves 90.2% mean AP on the PASAL VOC Action dataset, outperforming all other approaches in the field by a significant margin. Last, we show that R*CNN is not limited to action recognition. In particular, R*CNN can also be used to tackle fine-grained tasks such as attribute classification. We validate this claim by reporting state-of-the-art performance on the Berkeley Attributes of People dataset.
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Jan 06, 2016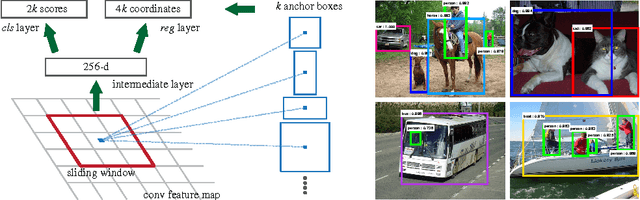
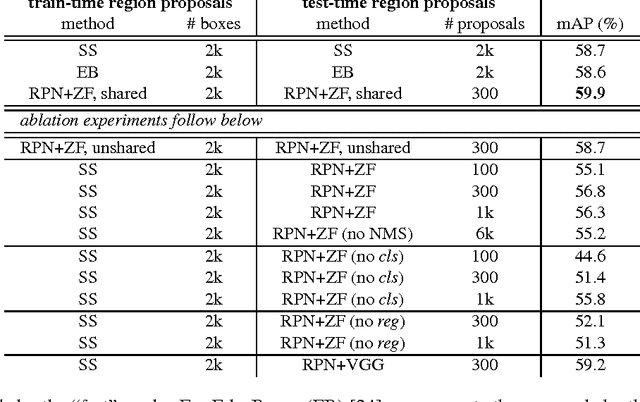
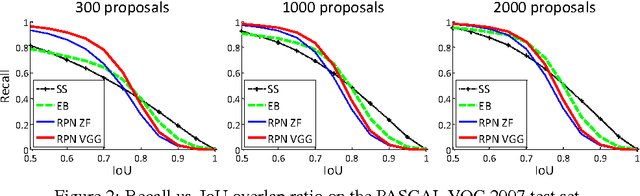

State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object locations. Advances like SPPnet and Fast R-CNN have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network (RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end to generate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features---using the recently popular terminology of neural networks with 'attention' mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model, our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO 2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks. Code has been made publicly available.
Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks
Dec 14, 2015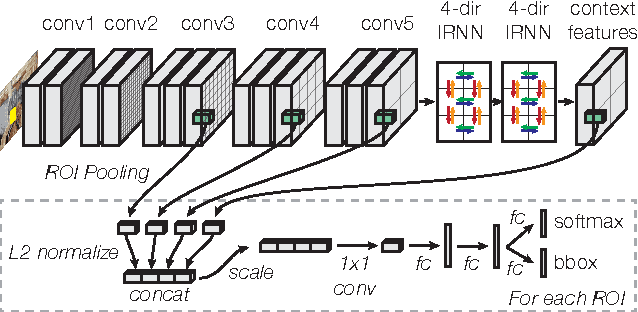
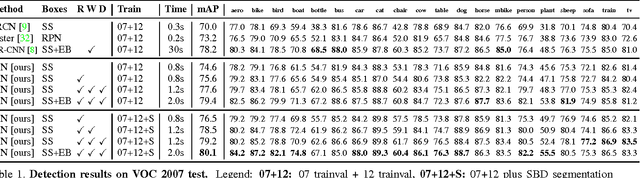
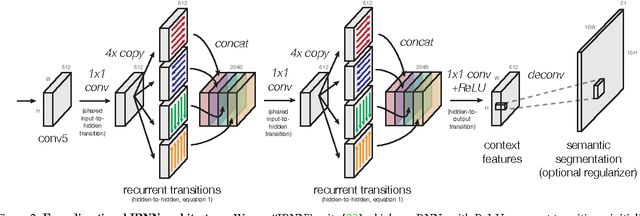
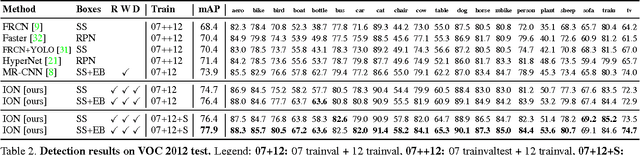
It is well known that contextual and multi-scale representations are important for accurate visual recognition. In this paper we present the Inside-Outside Net (ION), an object detector that exploits information both inside and outside the region of interest. Contextual information outside the region of interest is integrated using spatial recurrent neural networks. Inside, we use skip pooling to extract information at multiple scales and levels of abstraction. Through extensive experiments we evaluate the design space and provide readers with an overview of what tricks of the trade are important. ION improves state-of-the-art on PASCAL VOC 2012 object detection from 73.9% to 76.4% mAP. On the new and more challenging MS COCO dataset, we improve state-of-art-the from 19.7% to 33.1% mAP. In the 2015 MS COCO Detection Challenge, our ION model won the Best Student Entry and finished 3rd place overall. As intuition suggests, our detection results provide strong evidence that context and multi-scale representations improve small object detection.
Fast R-CNN
Sep 27, 2015



This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks. Compared to previous work, Fast R-CNN employs several innovations to improve training and testing speed while also increasing detection accuracy. Fast R-CNN trains the very deep VGG16 network 9x faster than R-CNN, is 213x faster at test-time, and achieves a higher mAP on PASCAL VOC 2012. Compared to SPPnet, Fast R-CNN trains VGG16 3x faster, tests 10x faster, and is more accurate. Fast R-CNN is implemented in Python and C++ (using Caffe) and is available under the open-source MIT License at https://github.com/rbgirshick/fast-rcnn.