 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Small Bowel Segmentation using Disentangled Representation
Jul 06, 2021We present a novel unsupervised domain adaptation method for small bowel segmentation based on feature disentanglement. To make the domain adaptation more controllable, we disentangle intensity and non-intensity features within a unique two-stream auto-encoding architecture, and selectively adapt the non-intensity features that are believed to be more transferable across domains. The segmentation prediction is performed by aggregating the disentangled features. We evaluated our method using intravenous contrast-enhanced abdominal CT scans with and without oral contrast, which are used as source and target domains, respectively. The proposed method showed clear improvements in terms of three different metrics compared to other domain adaptation methods that are without the feature disentanglement. The method brings small bowel segmentation closer to clinical application.
The Medical Segmentation Decathlon
Jun 10, 2021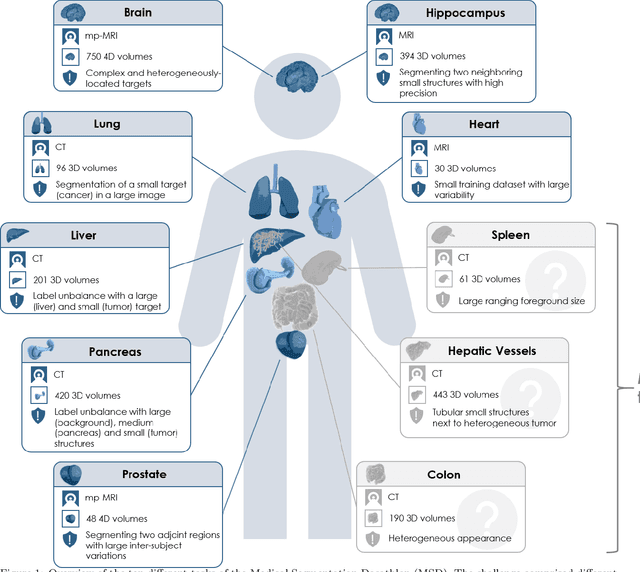
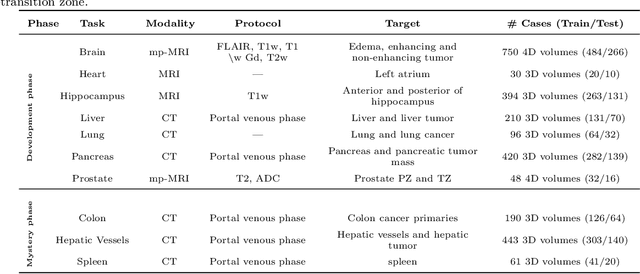
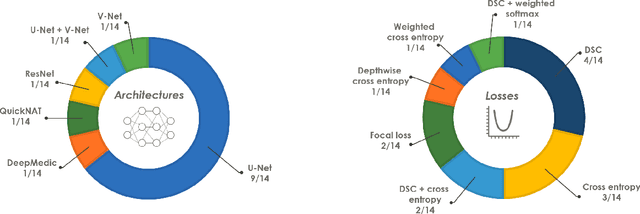
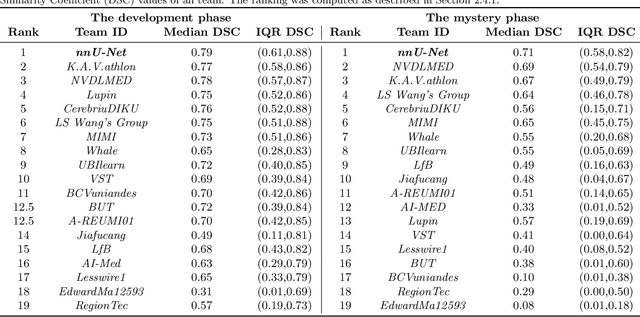
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Common Limitations of Image Processing Metrics: A Picture Story
Apr 13, 2021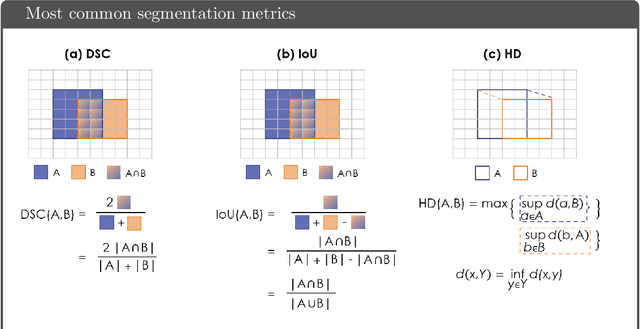
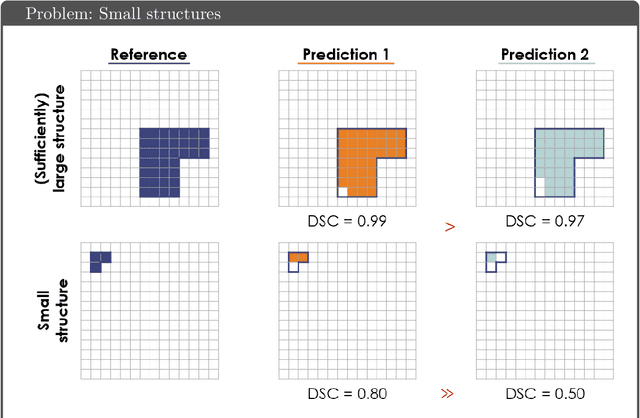
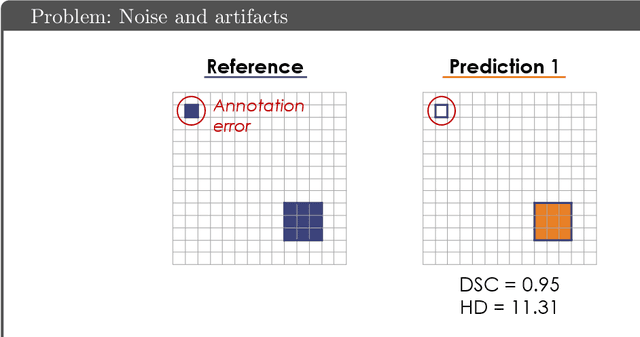
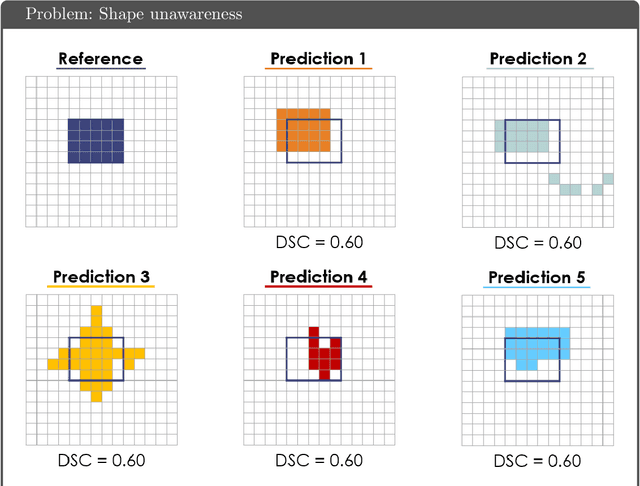
While the importance of automatic image analysis is increasing at an enormous pace, recent meta-research revealed major flaws with respect to algorithm validation. Specifically, performance metrics are key for objective, transparent and comparative performance assessment, but relatively little attention has been given to the practical pitfalls when using specific metrics for a given image analysis task. A common mission of several international initiatives is therefore to provide researchers with guidelines and tools to choose the performance metrics in a problem-aware manner. This dynamically updated document has the purpose to illustrate important limitations of performance metrics commonly applied in the field of image analysis. The current version is based on a Delphi process on metrics conducted by an international consortium of image analysis experts.
A review of deep learning in medical imaging: Image traits, technology trends, case studies with progress highlights, and future promises
Aug 02, 2020



Since its renaissance, deep learning has been widely used in various medical imaging tasks and has achieved remarkable success in many medical imaging applications, thereby propelling us into the so-called artificial intelligence (AI) era. It is known that the success of AI is mostly attributed to the availability of big data with annotations for a single task and the advances in high performance computing. However, medical imaging presents unique challenges that confront deep learning approaches. In this survey paper, we first highlight both clinical needs and technical challenges in medical imaging and describe how emerging trends in deep learning are addressing these issues. We cover the topics of network architecture, sparse and noisy labels, federating learning, interpretability, uncertainty quantification, etc. Then, we present several case studies that are commonly found in clinical practice, including digital pathology and chest, brain, cardiovascular, and abdominal imaging. Rather than presenting an exhaustive literature survey, we instead describe some prominent research highlights related to these case study applications. We conclude with a discussion and presentation of promising future directions.
E$^2$Net: An Edge Enhanced Network for Accurate Liver and Tumor Segmentation on CT Scans
Jul 19, 2020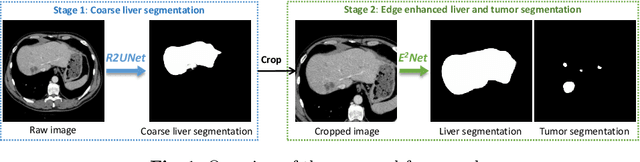
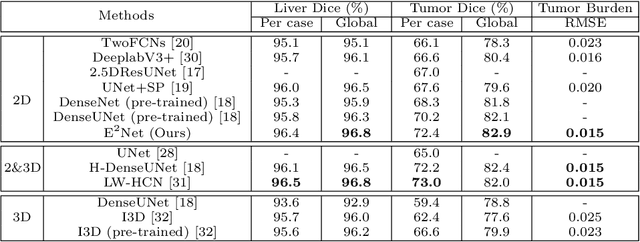
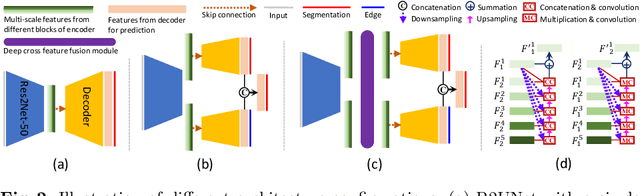
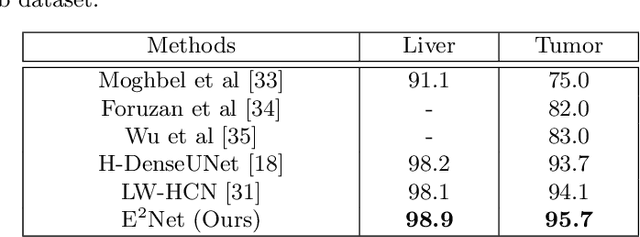
Developing an effective liver and liver tumor segmentation model from CT scans is very important for the success of liver cancer diagnosis, surgical planning and cancer treatment. In this work, we propose a two-stage framework for 2D liver and tumor segmentation. The first stage is a coarse liver segmentation network, while the second stage is an edge enhanced network (E$^2$Net) for more accurate liver and tumor segmentation. E$^2$Net explicitly models complementary objects (liver and tumor) and their edge information within the network to preserve the organ and lesion boundaries. We introduce an edge prediction module in E$^2$Net and design an edge distance map between liver and tumor boundaries, which is used as an extra supervision signal to train the edge enhanced network. We also propose a deep cross feature fusion module to refine multi-scale features from both objects and their edges. E$^2$Net is more easily and efficiently trained with a small labeled dataset, and it can be trained/tested on the original 2D CT slices (resolve resampling error issue in 3D models). The proposed framework has shown superior performance on both liver and liver tumor segmentation compared to several state-of-the-art 2D, 3D and 2D/3D hybrid frameworks.
Deep Small Bowel Segmentation with Cylindrical Topological Constraints
Jul 16, 2020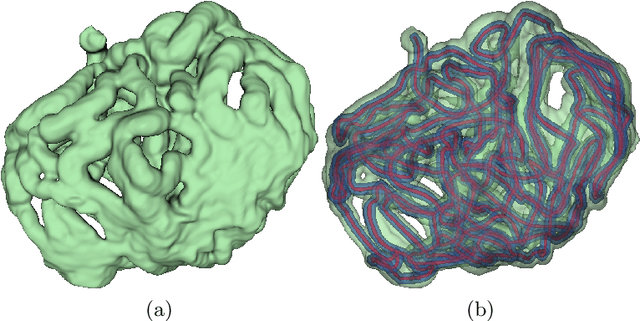
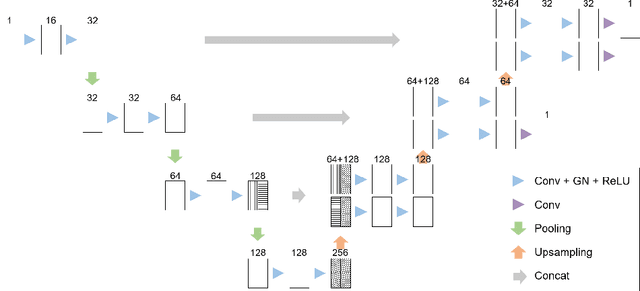

We present a novel method for small bowel segmentation where a cylindrical topological constraint based on persistent homology is applied. To address the touching issue which could break the applied constraint, we propose to augment a network with an additional branch to predict an inner cylinder of the small bowel. Since the inner cylinder is free of the touching issue, a cylindrical shape constraint applied on this augmented branch guides the network to generate a topologically correct segmentation. For strict evaluation, we achieved an abdominal computed tomography dataset with dense segmentation ground-truths. The proposed method showed clear improvements in terms of four different metrics compared to the baseline method, and also showed the statistical significance from a paired t-test.
Cross-Domain Medical Image Translation by Shared Latent Gaussian Mixture Model
Jul 14, 2020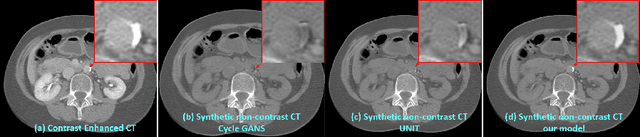
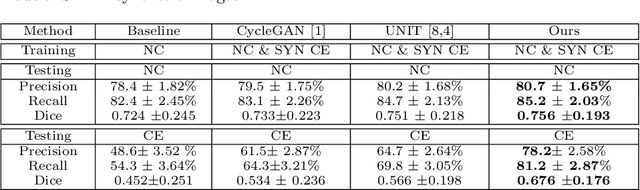
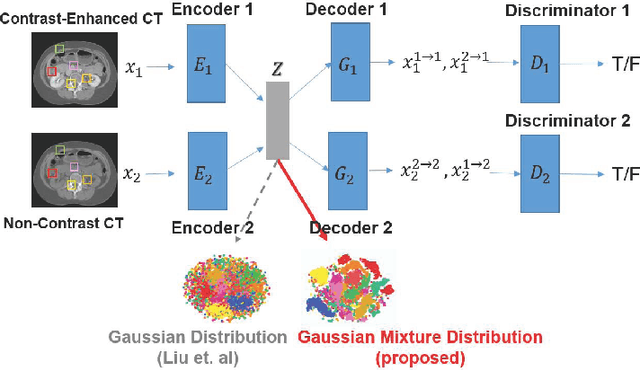
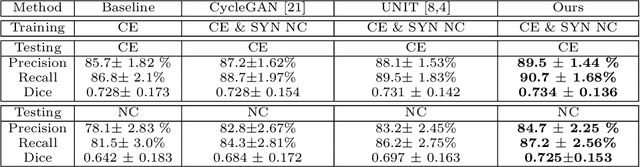
Current deep learning based segmentation models often generalize poorly between domains due to insufficient training data. In real-world clinical applications, cross-domain image analysis tools are in high demand since medical images from different domains are often needed to achieve a precise diagnosis. An important example in radiology is generalizing from non-contrast CT to contrast enhanced CTs. Contrast enhanced CT scans at different phases are used to enhance certain pathologies or organs. Many existing cross-domain image-to-image translation models have been shown to improve cross-domain segmentation of large organs. However, such models lack the ability to preserve fine structures during the translation process, which is significant for many clinical applications, such as segmenting small calcified plaques in the aorta and pelvic arteries. In order to preserve fine structures during medical image translation, we propose a patch-based model using shared latent variables from a Gaussian mixture model. We compare our image translation framework to several state-of-the-art methods on cross-domain image translation and show our model does a better job preserving fine structures. The superior performance of our model is verified by performing two tasks with the translated images - detection and segmentation of aortic plaques and pancreas segmentation. We expect the utility of our framework will extend to other problems beyond segmentation due to the improved quality of the generated images and enhanced ability to preserve small structures.
COVID-19-CT-CXR: a freely accessible and weakly labeled chest X-ray and CT image collection on COVID-19 from biomedical literature
Jun 11, 2020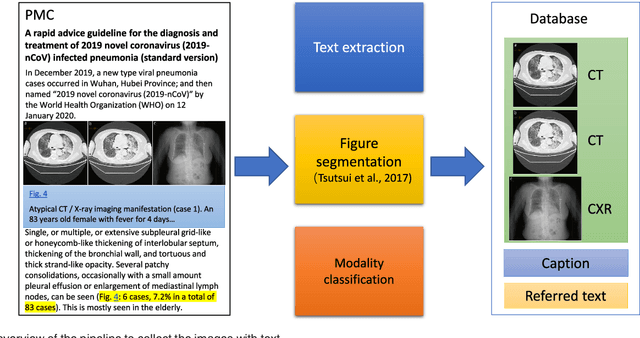
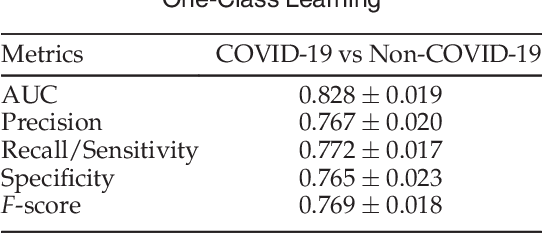
The latest threat to global health is the COVID-19 outbreak. Although there exist large datasets of chest X-rays (CXR) and computed tomography (CT) scans, few COVID-19 image collections are currently available due to patient privacy. At the same time, there is a rapid growth of COVID-19-relevant articles in the biomedical literature. Here, we present COVID-19-CT-CXR, a public database of COVID-19 CXR and CT images, which are automatically extracted from COVID-19-relevant articles from the PubMed Central Open Access (PMC-OA) Subset. We extracted figures, associated captions, and relevant figure descriptions in the article and separated compound figures into subfigures. We also designed a deep-learning model to distinguish them from other figure types and to classify them accordingly. The final database includes 1,327 CT and 263 CXR images (as of May 9, 2020) with their relevant text. To demonstrate the utility of COVID-19-CT-CXR, we conducted four case studies. (1) We show that COVID-19-CT-CXR, when used as additional training data, is able to contribute to improved DL performance for the classification of COVID-19 and non-COVID-19 CT. (2) We collected CT images of influenza and trained a DL baseline to distinguish a diagnosis of COVID-19, influenza, or normal or other types of diseases on CT. (3) We trained an unsupervised one-class classifier from non-COVID-19 CXR and performed anomaly detection to detect COVID-19 CXR. (4) From text-mined captions and figure descriptions, we compared clinical symptoms and clinical findings of COVID-19 vs. those of influenza to demonstrate the disease differences in the scientific publications. We believe that our work is complementary to existing resources and hope that it will contribute to medical image analysis of the COVID-19 pandemic. The dataset, code, and DL models are publicly available at https://github.com/ncbi-nlp/COVID-19-CT-CXR.
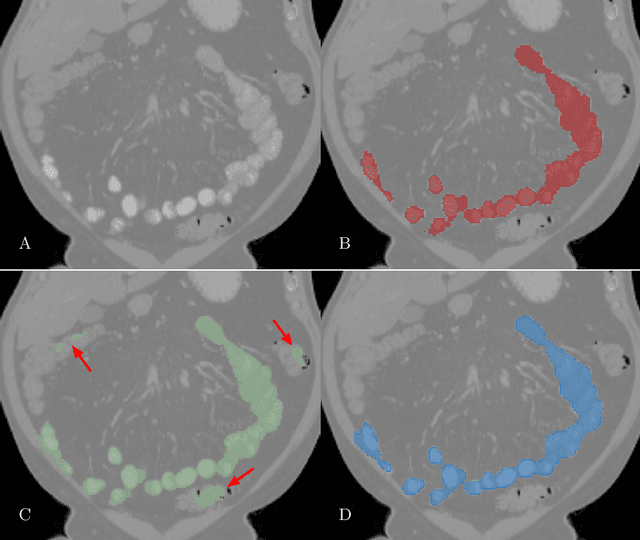
Image Translation by Latent Union of Subspaces for Cross-Domain Plaque Detection
May 22, 2020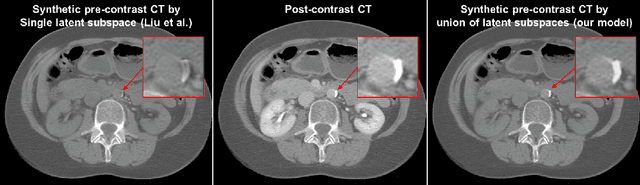

Calcified plaque in the aorta and pelvic arteries is associated with coronary artery calcification and is a strong predictor of heart attack. Current calcified plaque detection models show poor generalizability to different domains (ie. pre-contrast vs. post-contrast CT scans). Many recent works have shown how cross domain object detection can be improved using an image translation model which translates between domains using a single shared latent space. However, while current image translation models do a good job preserving global/intermediate level structures they often have trouble preserving tiny structures. In medical imaging applications, preserving small structures is important since these structures can carry information which is highly relevant for disease diagnosis. Recent works on image reconstruction show that complex real-world images are better reconstructed using a union of subspaces approach. Since small image patches are used to train the image translation model, it makes sense to enforce that each patch be represented by a linear combination of subspaces which may correspond to the different parts of the body present in that patch. Motivated by this, we propose an image translation network using a shared union of subspaces constraint and show our approach preserves subtle structures (plaques) better than the conventional method. We further applied our method to a cross domain plaque detection task and show significant improvement compared to the state-of-the art method.
The Future of Digital Health with Federated Learning
Mar 18, 2020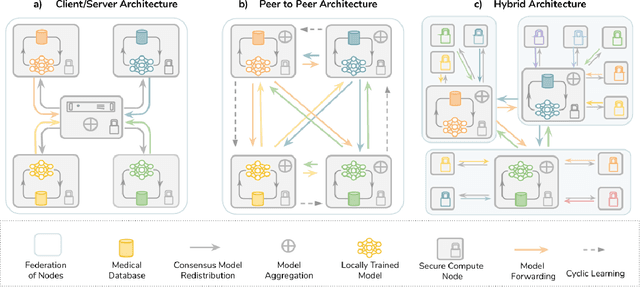
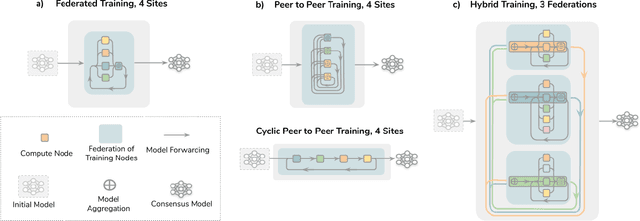
Data-driven Machine Learning has emerged as a promising approach for building accurate and robust statistical models from medical data, which is collected in huge volumes by modern healthcare systems. Existing medical data is not fully exploited by ML primarily because it sits in data silos and privacy concerns restrict access to this data. However, without access to sufficient data, ML will be prevented from reaching its full potential and, ultimately, from making the transition from research to clinical practice. This paper considers key factors contributing to this issue, explores how Federated Learning (FL) may provide a solution for the future of digital health and highlights the challenges and considerations that need to be addressed.