 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavDreams: Towards Camera-Only RL Navigation Among Humans
Mar 23, 2022
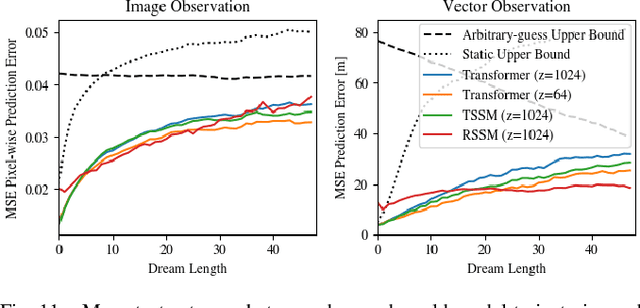
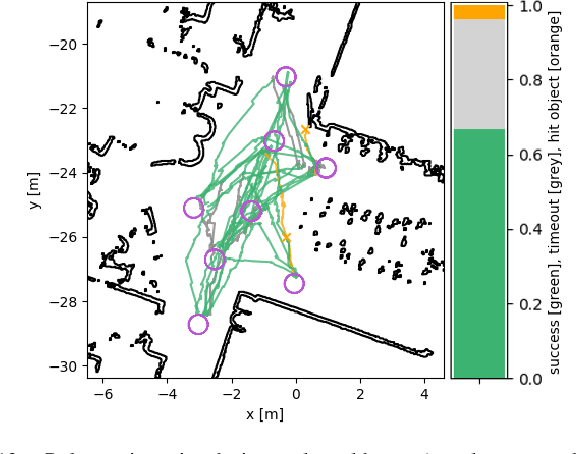
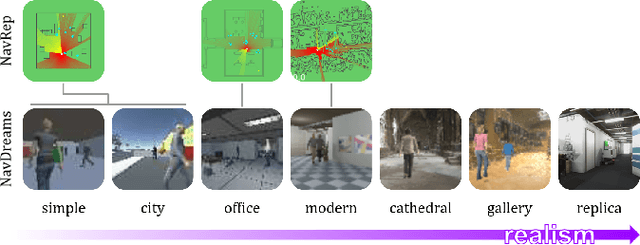
Autonomously navigating a robot in everyday crowded spaces requires solving complex perception and planning challenges. When using only monocular image sensor data as input, classical two-dimensional planning approaches cannot be used. While images present a significant challenge when it comes to perception and planning, they also allow capturing potentially important details, such as complex geometry, body movement, and other visual cues. In order to successfully solve the navigation task from only images, algorithms must be able to model the scene and its dynamics using only this channel of information. We investigate whether the world model concept, which has shown state-of-the-art results for modeling and learning policies in Atari games as well as promising results in 2D LiDAR-based crowd navigation, can also be applied to the camera-based navigation problem. To this end, we create simulated environments where a robot must navigate past static and moving humans without colliding in order to reach its goal. We find that state-of-the-art methods are able to achieve success in solving the navigation problem, and can generate dream-like predictions of future image-sequences which show consistent geometry and moving persons. We are also able to show that policy performance in our high-fidelity sim2real simulation scenario transfers to the real world by testing the policy on a real robot. We make our simulator, models and experiments available at https://github.com/danieldugas/NavDreams.
Energy Tank-Based Policies for Robust Aerial Physical Interaction with Moving Objects
Mar 07, 2022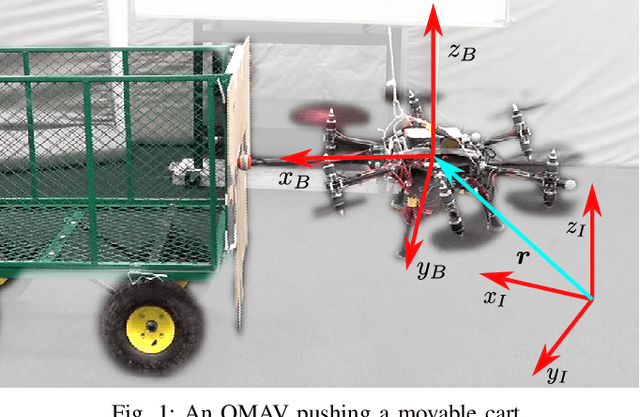
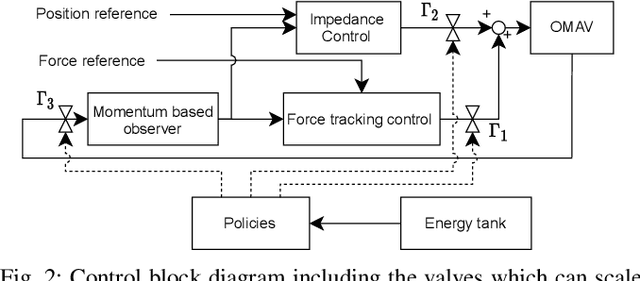
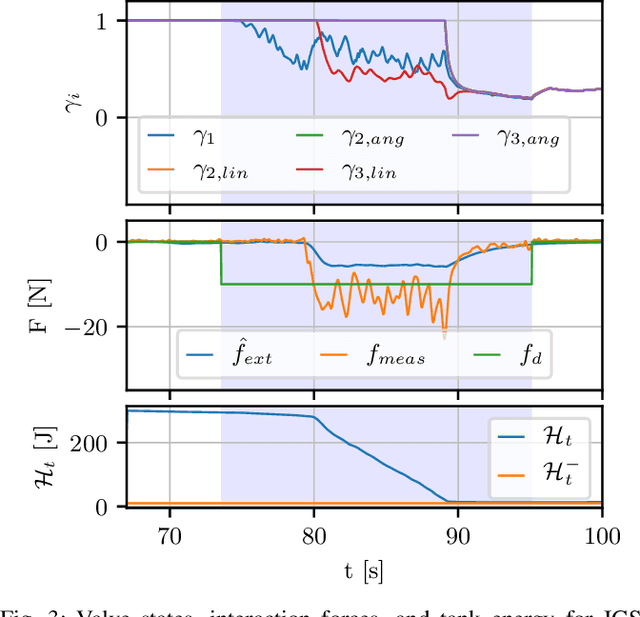
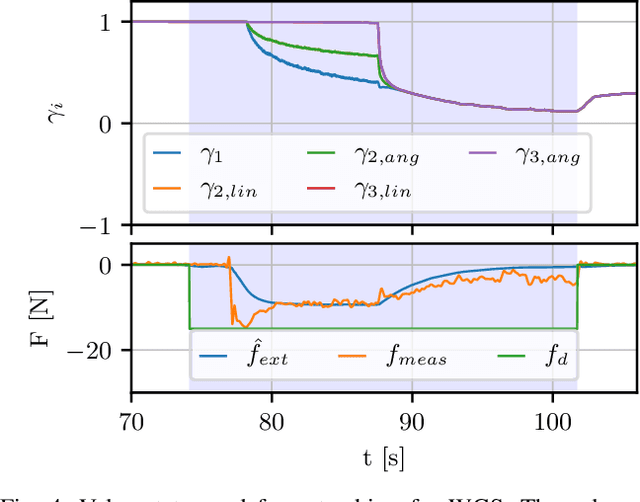
Although manipulation capabilities of aerial robots greatly improved in the last decade, only few works addressed the problem of aerial physical interaction with dynamic environments, proposing strongly model-based approaches. However, in real scenarios, modeling the environment with high accuracy is often impossible. In this work we aim at developing a control framework for OMAVs for reliable physical interaction tasks with articulated and movable objects in the presence of possibly unforeseen disturbances, and without relying on an accurate model of the environment. Inspired by previous applications of energy-based controllers for physical interaction, we propose a passivity-based impedance and wrench tracking controller in combination with a momentum-based wrench estimator. This is combined with an energy-tank framework to guarantee the stability of the system, while energy and power flow-based adaptation policies are deployed to enable safe interaction with any type of passive environment. The control framework provides formal guarantees of stability, which is validated in practice considering the challenging task of pushing a cart of unknown mass, moving on a surface of unknown friction, as well as subjected to unknown disturbances. For this scenario, we present, evaluate and discuss three different policies.
Towards 6DoF Bilateral Teleoperation of an Omnidirectional Aerial Vehicle for Aerial Physical Interaction
Mar 07, 2022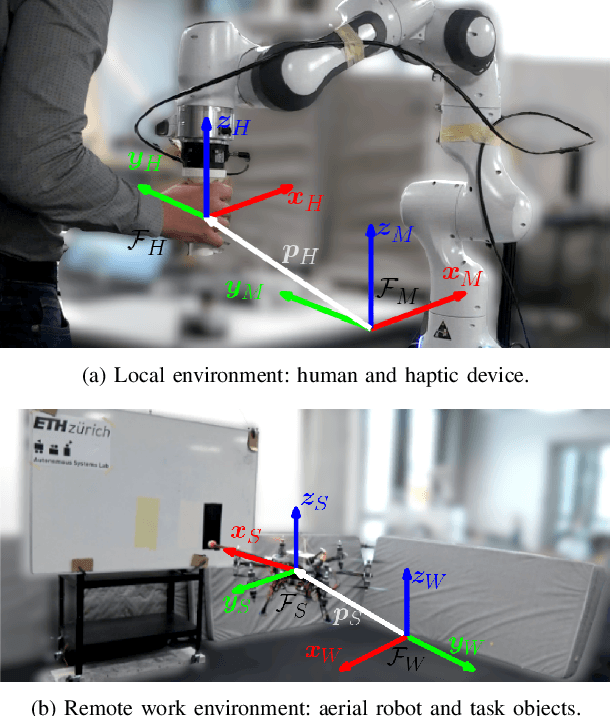
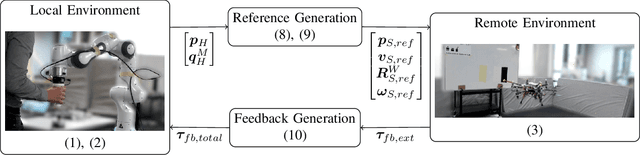
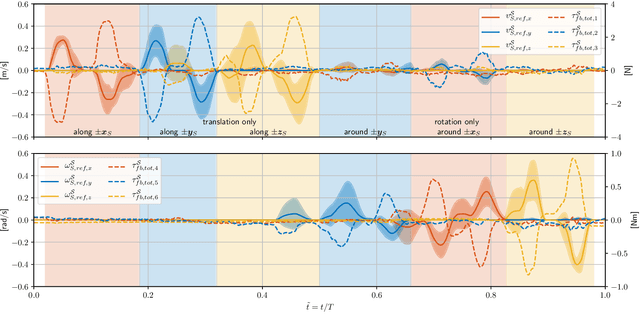
Bilateral teleoperation offers an intriguing solution towards shared autonomy with aerial vehicles in contact-based inspection and manipulation tasks. Omnidirectional aerial robots allow for full pose operations, making them particularly attractive in such tasks. Naturally, the question arises whether standard bilateral teleoperation methodologies are suitable for use with these vehicles. In this work, a fully decoupled 6DoF bilateral teleoperation framework for aerial physical interaction is designed and tested for the first time. The method is based on the well established rate control, recentering and interaction force feedback policy. However, practical experiments evince the difficulty of performing decoupled motions in a single axis only. As such, this work shows that the trivial extension of standard methods is insufficient for omnidirectional teleoperation, due to the operators physical inability to properly decouple all input DoFs. This suggests that further studies on enhanced haptic feedback are necessary.
Human-State-Aware Controller for a Tethered Aerial Robot Guiding a Human by Physical Interaction
Mar 07, 2022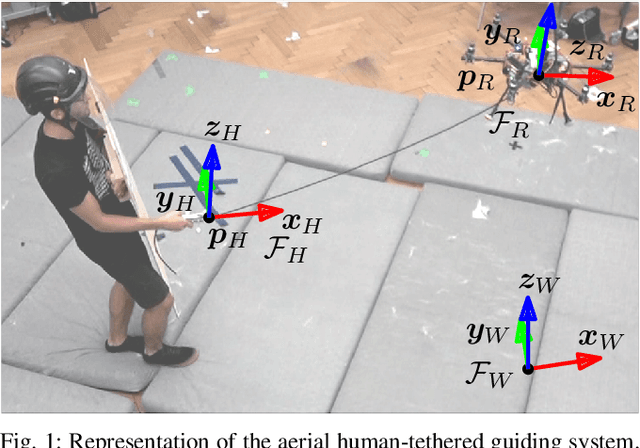
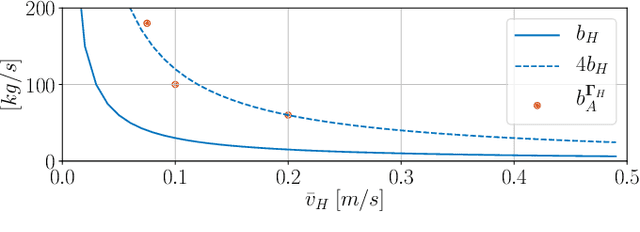
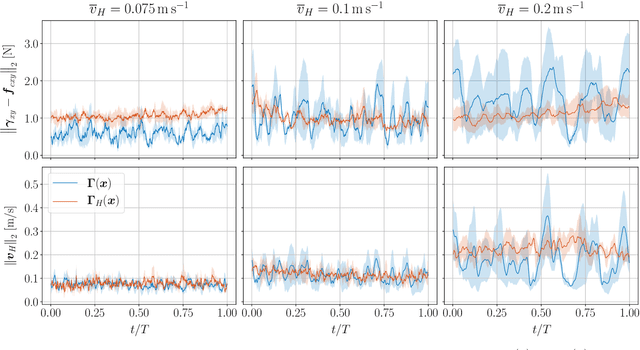
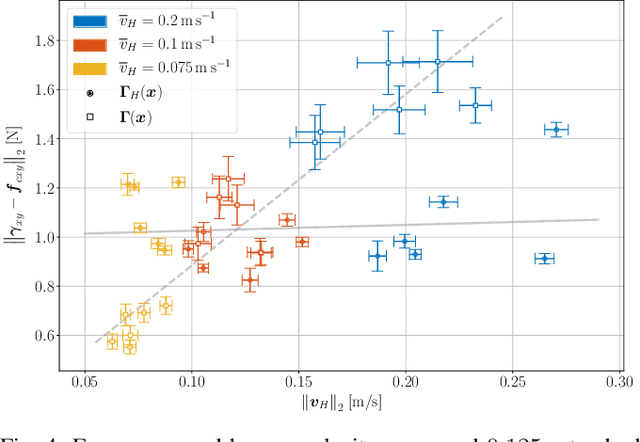
With the rapid development of Aerial Physical Interaction, the possibility to have aerial robots physically interacting with humans is attracting a growing interest. In one of our previous works, we considered one of the first systems in which a human is physically connected to an aerial vehicle by a cable. There, we developed a compliant controller that allows the robot to pull the human toward a desired position using forces only as an indirect communication-channel. However, this controller is based on the robot-state only, which makes the system not adaptable to the human behavior, and in particular to their walking speed. This reduces the effectiveness and comfort of the guidance when the human is still far from the desired point. In this paper, we formally analyze the problem and propose a human-state-aware controller that includes a human`s velocity feedback. We theoretically prove and experimentally show that this method provides a more consistent guiding force which enhances the guiding experience.
Descriptellation: Deep Learned Constellation Descriptors for SLAM
Mar 01, 2022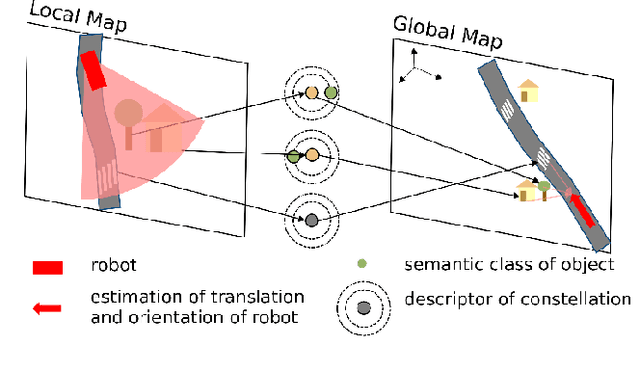
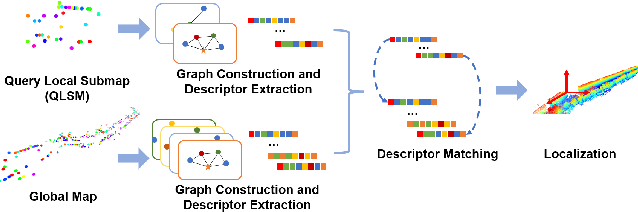
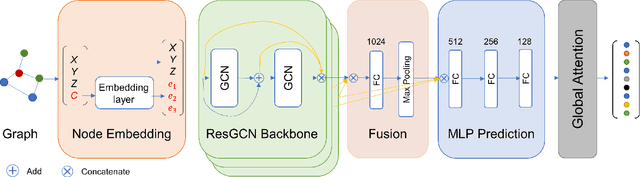
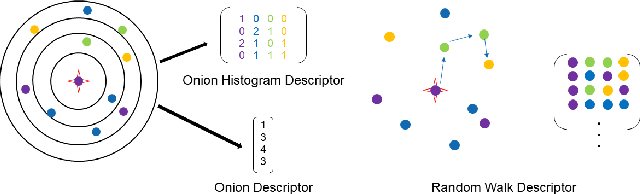
Current global localization descriptors in Simultaneous Localization and Mapping (SLAM) often fail under vast viewpoint or appearance changes. Adding topological information of semantic objects into the descriptors ameliorates the problem. However, hand-crafted topological descriptors extract limited information and they are not robust to environmental noise, drastic perspective changes, or object occlusion or misdetections. To solve this problem, we formulate a learning-based approach by constructing constellations from semantically meaningful objects and use Deep Graph Convolution Networks to map the constellation representation to a descriptor. We demonstrate the effectiveness of our Deep Learned Constellation Descriptor (Descriptellation) on the Paris-Rue-Lille and IQmulus datasets. Although Descriptellation is trained on randomly generated simulation datasets, it shows good generalization abilities on real-world datasets. Descriptellation outperforms the PointNet and handcrafted constellation descriptors for global localization, and shows robustness against different types of noise.
Embodied Active Domain Adaptation for Semantic Segmentation via Informative Path Planning
Mar 01, 2022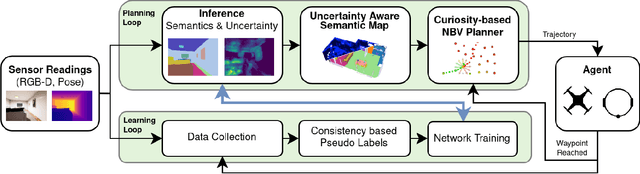
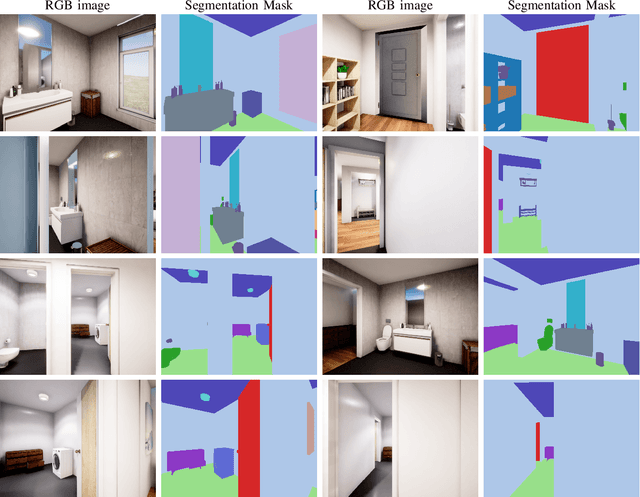


This work presents an embodied agent that can adapt its semantic segmentation network to new indoor environments in a fully autonomous way. Because semantic segmentation networks fail to generalize well to unseen environments, the agent collects images of the new environment which are then used for self-supervised domain adaptation. We formulate this as an informative path planning problem, and present a novel information gain that leverages uncertainty extracted from the semantic model to safely collect relevant data. As domain adaptation progresses, these uncertainties change over time and the rapid learning feedback of our system drives the agent to collect different data. Experiments show that our method adapts to new environments faster and with higher final performance compared to an exploration objective, and can successfully be deployed to real-world environments on physical robots.
Collaborative Robot Mapping using Spectral Graph Analysis
Mar 01, 2022
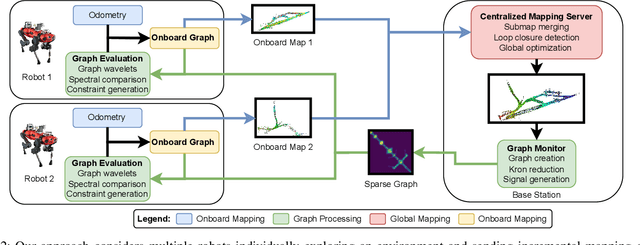
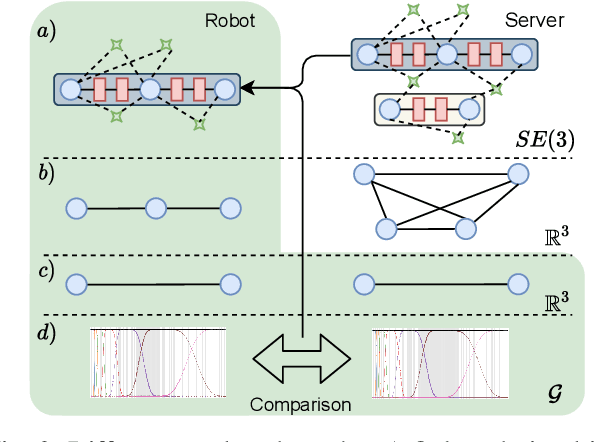
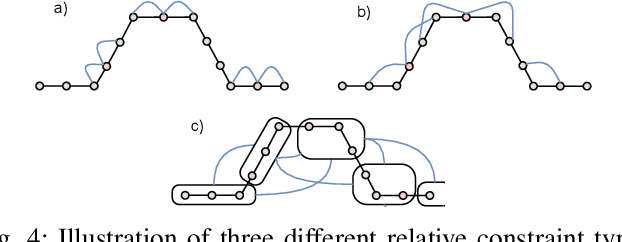
In this paper, we deal with the problem of creating globally consistent pose graphs in a centralized multi-robot SLAM framework. For each robot to act autonomously, individual onboard pose estimates and maps are maintained, which are then communicated to a central server to build an optimized global map. However, inconsistencies between onboard and server estimates can occur due to onboard odometry drift or failure. Furthermore, robots do not benefit from the collaborative map if the server provides no feedback in a computationally tractable and bandwidth-efficient manner. Motivated by this challenge, this paper proposes a novel collaborative mapping framework to enable accurate global mapping among robots and server. In particular, structural differences between robot and server graphs are exploited at different spatial scales using graph spectral analysis to generate necessary constraints for the individual robot pose graphs. The proposed approach is thoroughly analyzed and validated using several real-world multi-robot field deployments where we show improvements of the onboard system up to 90%.
Fast and Compute-efficient Sampling-based Local Exploration Planning via Distribution Learning
Feb 28, 2022
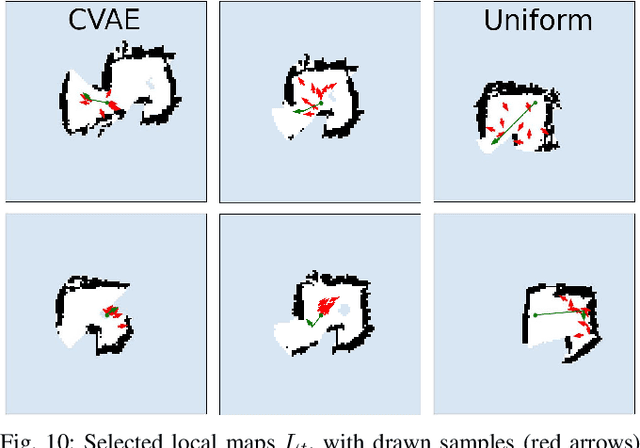
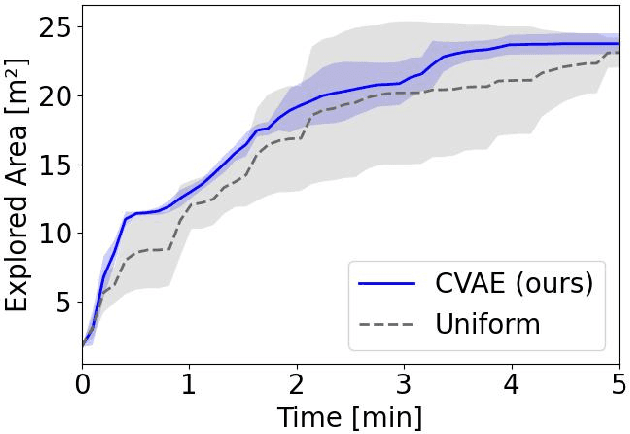
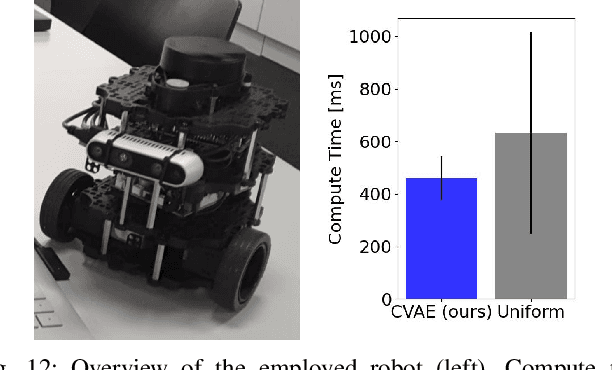
Exploration is a fundamental problem in robotics. While sampling-based planners have shown high performance, they are oftentimes compute intensive and can exhibit high variance. To this end, we propose to directly learn the underlying distribution of informative views based on the spatial context in the robot's map. We further explore a variety of methods to also learn the information gain. We show in thorough experimental evaluation that our proposed system improves exploration performance by up to 28\% over classical methods, and find that learning the gains in addition to the sampling distribution can provide favorable performance vs. compute trade-offs for compute-constrained systems. We demonstrate in simulation and on a low-cost mobile robot that our system generalizes well to varying environments.
SL Sensor: An Open-Source, ROS-Based, Real-Time Structured Light Sensor for High Accuracy Construction Robotic Applications
Jan 22, 2022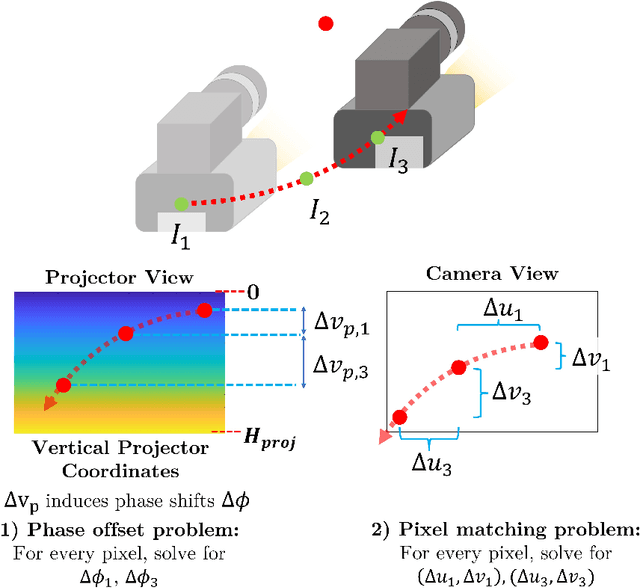


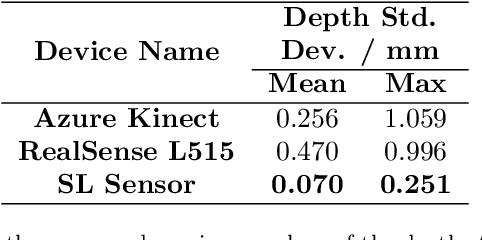
High accuracy 3D surface information is required for many construction robotics tasks such as automated cement polishing or robotic plaster spraying. However, consumer-grade depth cameras currently found in the market are not accurate enough for these tasks where millimeter (mm)-level accuracy is required. We present SL Sensor, a structured light sensing solution capable of producing high fidelity point clouds at 5Hz by leveraging on phase shifting profilometry (PSP) codification techniques. We compared SL Sensor to two commercial depth cameras - the Azure Kinect and RealSense L515. Experiments showed that the SL Sensor surpasses the two devices in both precision and accuracy. Furthermore, to demonstrate SL Sensor's ability to be a structured light sensing research platform for robotic applications, we developed a motion compensation strategy that allows the SL Sensor to operate during linear motion when traditional PSP methods only work when the sensor is static. Field experiments show that the SL Sensor is able produce highly detailed reconstructions of spray plastered surfaces. The software and a sample hardware build of the SL Sensor are made open-source with the objective to make structured light sensing more accessible to the construction robotics community. All documentation and code is available at https://github.com/ethz-asl/sl_sensor/ .
Semi-automatic 3D Object Keypoint Annotation and Detection for the Masses
Jan 19, 2022
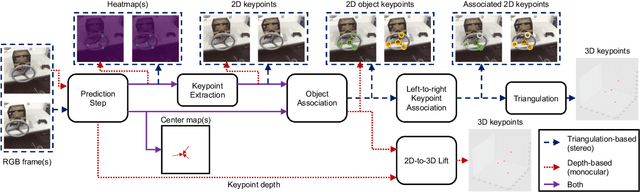

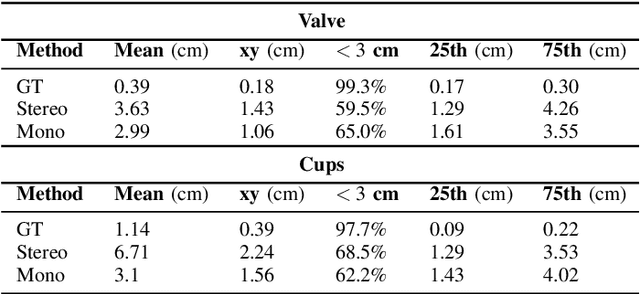
Creating computer vision datasets requires careful planning and lots of time and effort. In robotics research, we often have to use standardized objects, such as the YCB object set, for tasks such as object tracking, pose estimation, grasping and manipulation, as there are datasets and pre-learned methods available for these objects. This limits the impact of our research since learning-based computer vision methods can only be used in scenarios that are supported by existing datasets. In this work, we present a full object keypoint tracking toolkit, encompassing the entire process from data collection, labeling, model learning and evaluation. We present a semi-automatic way of collecting and labeling datasets using a wrist mounted camera on a standard robotic arm. Using our toolkit and method, we are able to obtain a working 3D object keypoint detector and go through the whole process of data collection, annotation and learning in just a couple hours of active time.